Recent well liked threads

چگونگی فروپاشی یک اپوزیسیون موضوع این رشته توییت است. این الگوی فروپاشی بارها تکرار شده است اما برای درک درست شیوه آن باید از یک تاریخچه نسبتا قدیمی آغاز کرد. کاملترین نمونه انجام شده در دولتهای مدرن.../۱ 

فریب ، ماهرانهترین فنون بکار رفته در جاسوسی و نهایت این هنرست.
سازمانهای جاسوسی با شناسایی خواست های طرف مقابل،طعمه هایی منطبق را سر راه وی قرار داده و به اغوای او میپردازند تا زمانی که به دام افتاده سپس با تغذیه اطلاعات تحریف شده و هدفمند، وی را به سوی دلخواه منحرف می کنند./۲
سازمانهای جاسوسی با شناسایی خواست های طرف مقابل،طعمه هایی منطبق را سر راه وی قرار داده و به اغوای او میپردازند تا زمانی که به دام افتاده سپس با تغذیه اطلاعات تحریف شده و هدفمند، وی را به سوی دلخواه منحرف می کنند./۲
عملیات تراست بعنوان مهمترین و سازمان یافته ترین فریب انجام شده در تاریخ سازمانهای جاسوسی نام برده میشود که در مدت طولانی با موفقیت ادامه پیدا کرد./۳


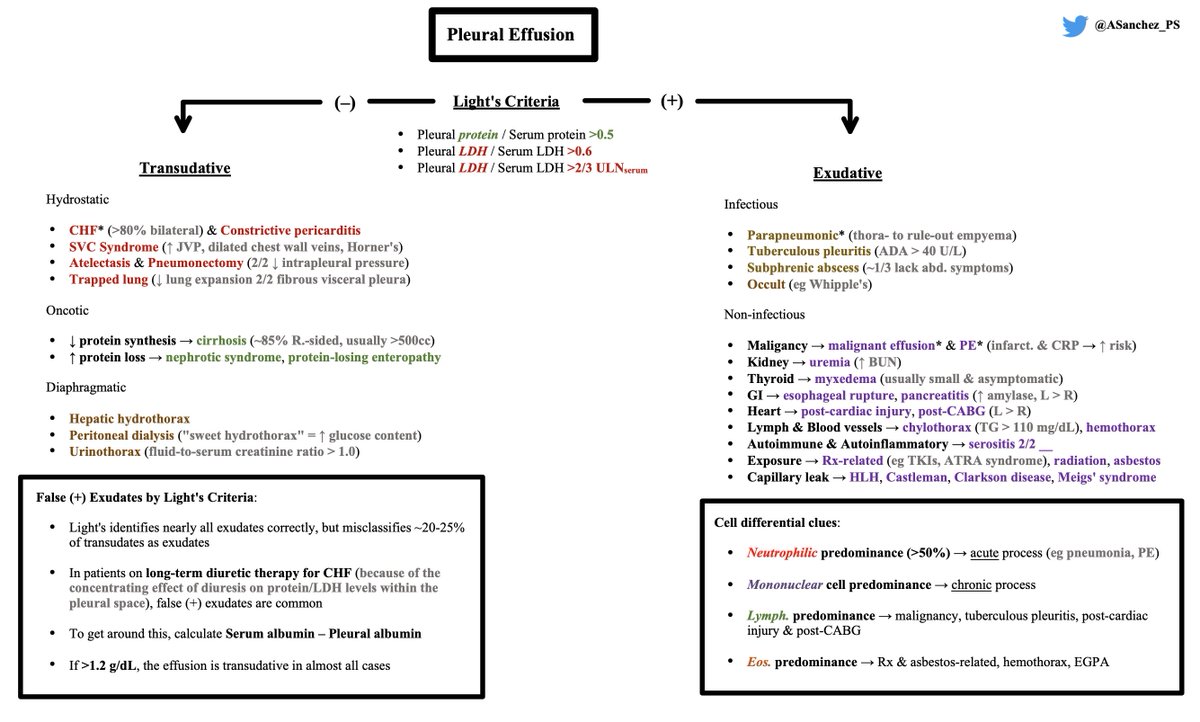
🫁💧 Pleural Effusion Schema 💧🫁
1) Thoracentesis → Calculate Light's criteria (Note: ~20-25% of true transudates are misclassified)
2) Stratify transudative DDx by Starling equation (Hydrostatic, Oncotic etiologies) & Diaphragm-related etiologies
3) Exudative DDx = longer!
1) Thoracentesis → Calculate Light's criteria (Note: ~20-25% of true transudates are misclassified)
2) Stratify transudative DDx by Starling equation (Hydrostatic, Oncotic etiologies) & Diaphragm-related etiologies
3) Exudative DDx = longer!
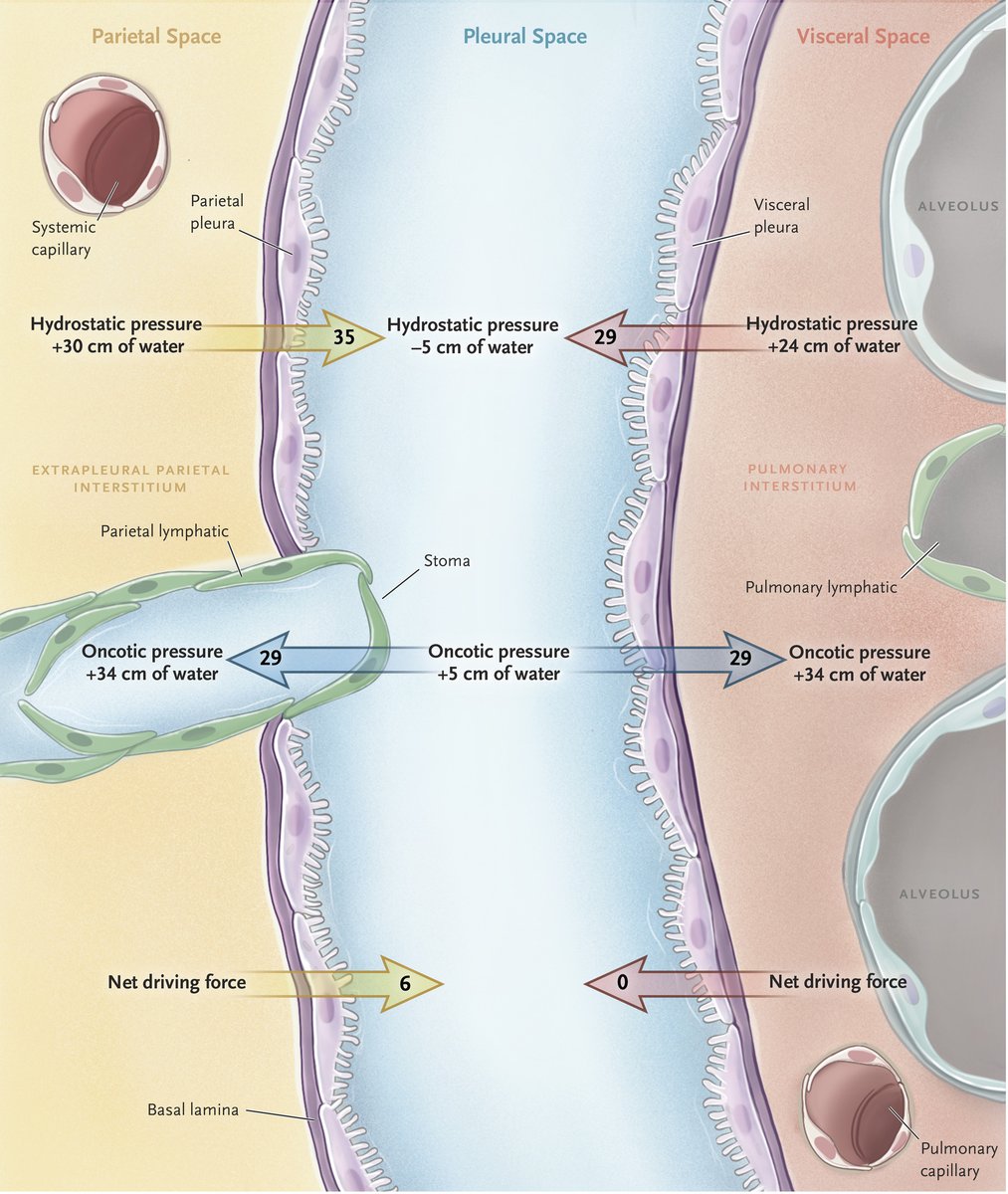
B/c hydrostatic pressures are higher on the parietal pleura than on the visceral pleura & the oncotic pressures are equivalent, pleural fluid is primarily produced from the parietal pleura. The lymphatic vessels on the parietal pleura are responsible for pleural fluid resorption.
💧 Of the transudative effusions, decompensated CHF is the most common
💧 Oncotic issues can be due to ↓ protein synthesis (cirrhosis) & ↑ protein loss (nephrotic syndrome, protein-losing enteropathy)
💧 Other etiologies have unique pathophys. & lab signatures (see below)
💧 Oncotic issues can be due to ↓ protein synthesis (cirrhosis) & ↑ protein loss (nephrotic syndrome, protein-losing enteropathy)
💧 Other etiologies have unique pathophys. & lab signatures (see below)


نظریهی "مجموعهی امنیتی منطقهای" چگونه تحولات غرب آسیا را چارچوببندی میکند؟
#رشتو
«مجموعهی امنیتی منطقهای» نظریهای است که در بررسی و روایت مسائل مختلفی که در حوزهی امنیت بینالملل رخ میدهد، سطح تحلیل منطقهای را به عنوان چارچوب اصلی و بنیادین خود انتخاب کرده است./۱
#رشتو
«مجموعهی امنیتی منطقهای» نظریهای است که در بررسی و روایت مسائل مختلفی که در حوزهی امنیت بینالملل رخ میدهد، سطح تحلیل منطقهای را به عنوان چارچوب اصلی و بنیادین خود انتخاب کرده است./۱
این نظریه بر این فرض مبتنی است که پایان جنگ سرد، جهان را به سمت برهوت ناامنی سوق داد. پس از تشکیل اسرائیل، در جهان عرب و بخش مهمی از جهان اسلام، موضوع رژیم صهیونیستی امنیتی شده بود و ساز و کارهای مختلفی برای مقابله با آن به وجود آمده بود. هدف آمریکا این بودکه اسرائیل دیگر.../۲
در ذهنیت کشورها و کنشگران منطقه امری امنیتی نباشد و جمهوری اسلامی ایران جایگزین آن به عنوان خطر اصلی امنیتی شود. این امر میتوانست ساز و کارهای اقتصادی و اجتماعی و زیستمحیطی مختلف با خود به همراه داشته باشد که به نوعی نظم مجموعۀ امنیتی خاورمیانه که پس از شکلگیری اسرائیل.../۳

Wow, that Cochrane review on nurse vs doctors is actually REMARKABLY bad. So, it's obviously an interesting question, and I was totally suprised to see there have been 19 RCTs comparing mortality between nurses and doctors (!). And the reported CI is tight RR 1.03 (0.87 to 1.21)+
So that seemed totally odd. I would have seen those trials. So I have a look. Wow. They are TOTALLY disparate. NICU care. ART in Uganda. Lung cancer follow up. Diabetes clinic. INTRAVITREAL EYE INECTION! Do we think that these are comparable and meta-analysable in any way?! +
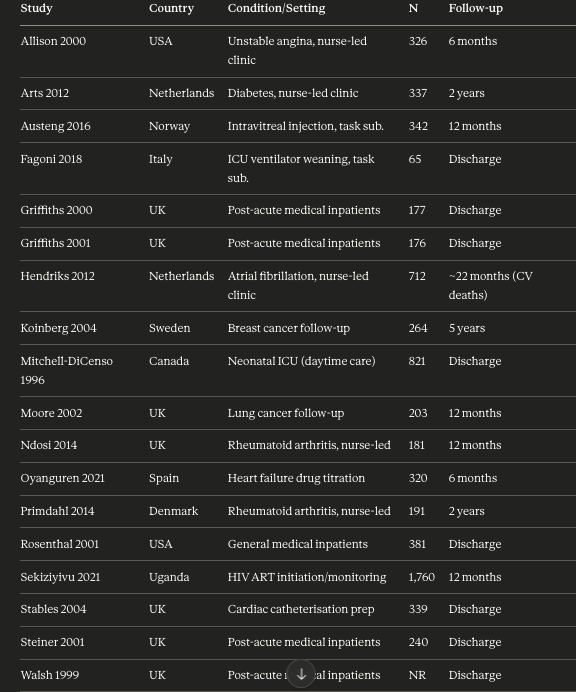
And, in 90% of these settings, deaths are either i) inevitable, or ii) random and rare. If you look at the row level data, nearly all the studies are super rare (<10 events), and 40% of the meta-analysis weight is one study (Moore et al, 2002), which is on lung cancer follow up+

1/
In 12 Tagen möchte die Bundesregierung ~300 Millionen an die Firma STARK zahlen, die u.a. Peter Thiel, Döpfners & der CIA gehört.
Es geht nicht um irgendein Produkt, sondern um Waffen zum Schutz unseres Landes. Es droht ein zweites “Palantir”.
Das sollten wir nicht zulassen!
In 12 Tagen möchte die Bundesregierung ~300 Millionen an die Firma STARK zahlen, die u.a. Peter Thiel, Döpfners & der CIA gehört.
Es geht nicht um irgendein Produkt, sondern um Waffen zum Schutz unseres Landes. Es droht ein zweites “Palantir”.
Das sollten wir nicht zulassen!

2/
Thiel ist brandgefährlich. Er sagt: Demokratie & Freiheit seien nicht vereinbar.
Die neuen Epstein-Files belegen seine Verbindungen nach Russland & zum faschistischen Vordenker Alexander Dugin, über den die Bundesregierung sagt: er will Krieg zwischen Russland & dem Westen.
Thiel ist brandgefährlich. Er sagt: Demokratie & Freiheit seien nicht vereinbar.
Die neuen Epstein-Files belegen seine Verbindungen nach Russland & zum faschistischen Vordenker Alexander Dugin, über den die Bundesregierung sagt: er will Krieg zwischen Russland & dem Westen.

3/
Die Bundesregierung handelt fahrlässig. Sie weiß bisher nicht, wem wie viel an der STARK gehört.
Wie viel ist in den Händen von MAGA-Fans?
Das darf nicht passieren – schon gar nicht in der Verteidigung.
STARK muss Regierung & Bundestag die Eigentümerstruktur offenlegen!
Die Bundesregierung handelt fahrlässig. Sie weiß bisher nicht, wem wie viel an der STARK gehört.
Wie viel ist in den Händen von MAGA-Fans?
Das darf nicht passieren – schon gar nicht in der Verteidigung.
STARK muss Regierung & Bundestag die Eigentümerstruktur offenlegen!

5 punten uit de nieuwe vooruitzichten van het Planbureau:
Onze economie blijft de komende jaren hangen in een patroon van positieve, maar (te) lage groei 1/5
Onze economie blijft de komende jaren hangen in een patroon van positieve, maar (te) lage groei 1/5
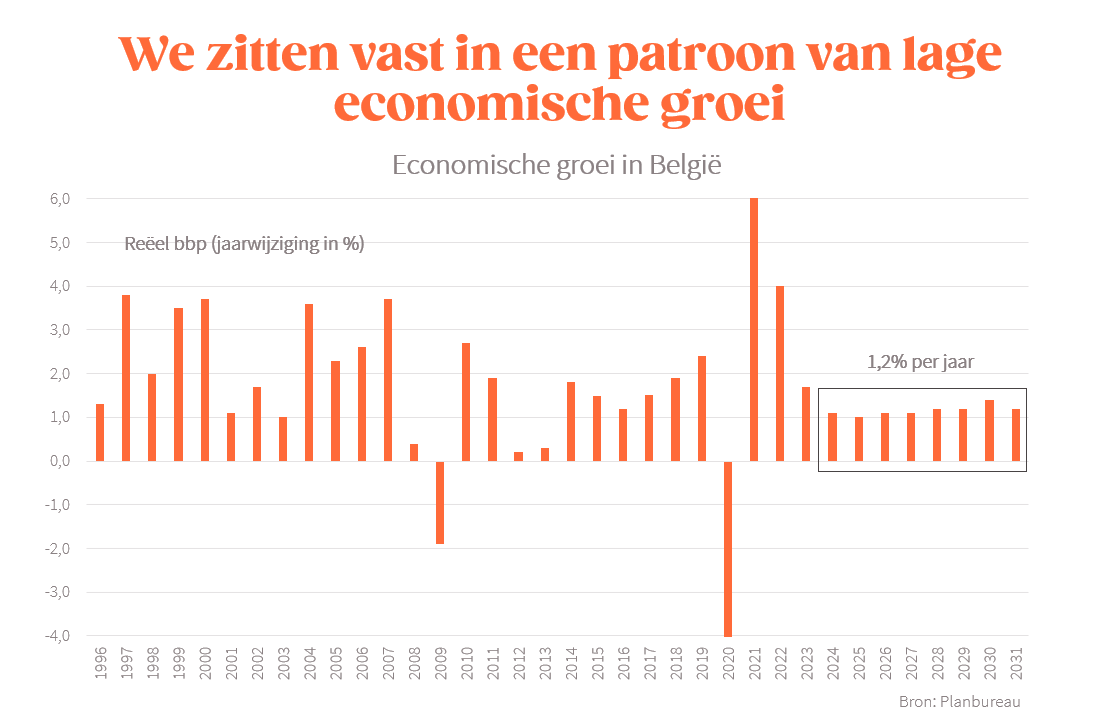
5 punten uit de nieuwe vooruitzichten van het Planbureau:
Het goeie nieuws: de koopkracht blijft toenemen, gemiddeld +15% (bovenop inflatie) in 2019-2031 2/5
Het goeie nieuws: de koopkracht blijft toenemen, gemiddeld +15% (bovenop inflatie) in 2019-2031 2/5
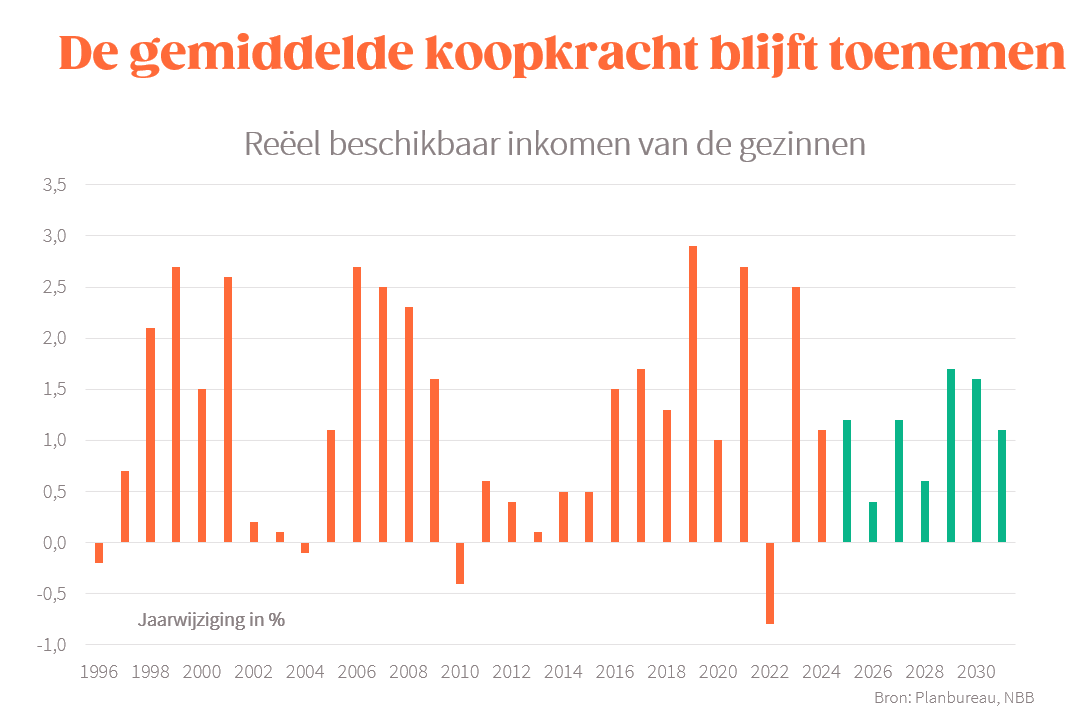
5 punten uit de nieuwe vooruitzichten van het Planbureau:
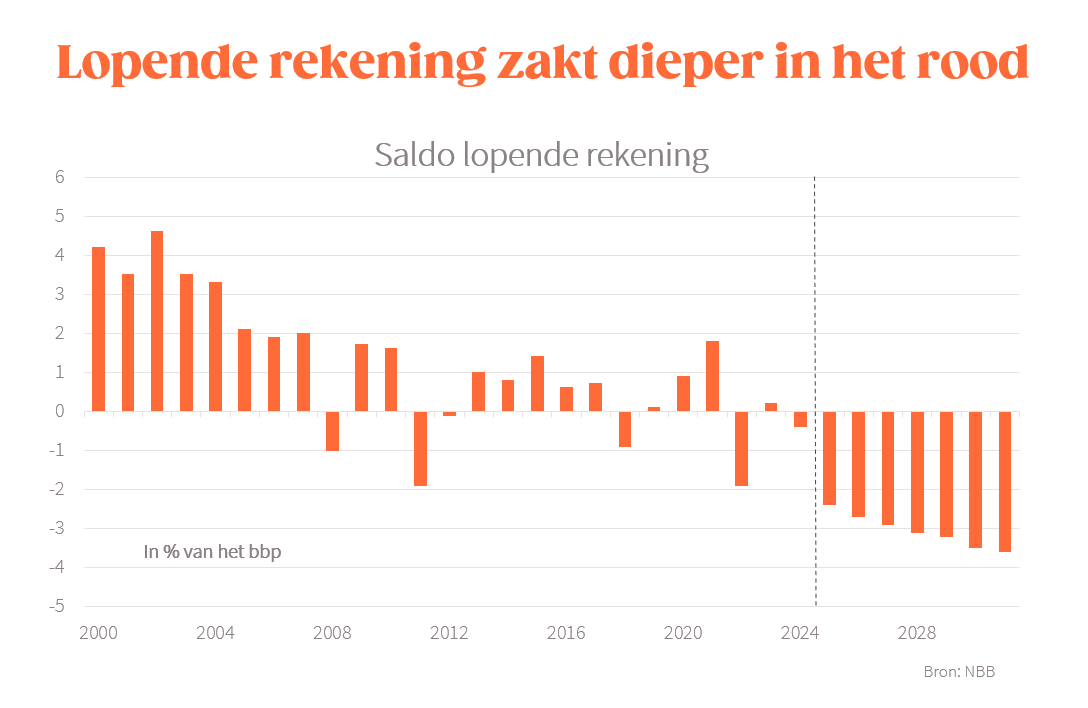
Onze exporteurs blijven internationaal marktaandeel verliezen (-8% in 2024-2031), waardoor de lopende rekening dieper in het rood duikt 3/5
Onze exporteurs blijven internationaal marktaandeel verliezen (-8% in 2024-2031), waardoor de lopende rekening dieper in het rood duikt 3/5

The US and Europe want “NATO 3.0” — EP.
“New version of alliance. It must rely on partnership, not dependence.
In 2025, NATO began a real shift. Europe will lead the Alliance’s conventional defense” — Deputy Defense Secretary Elbridge Colby.
1/
“New version of alliance. It must rely on partnership, not dependence.
In 2025, NATO began a real shift. Europe will lead the Alliance’s conventional defense” — Deputy Defense Secretary Elbridge Colby.
1/

Colby: In a sense, this is a return to ‘NATO 1.0’ — a serious Alliance focused on defense and deterrence.
This year, we must stand together, be pragmatic, and embrace the flexible realism reflected in the U.S. National Security and National Defense Strategies.
2/
This year, we must stand together, be pragmatic, and embrace the flexible realism reflected in the U.S. National Security and National Defense Strategies.
2/
Colby: “NATO 3.0” would mean returning the Alliance to its original purpose.
On February 12, a meeting of NATO defense ministers, the Ukraine-NATO Council, and a Ramstein-format meeting will take place at NATO headquarters in Brussels.
3X
On February 12, a meeting of NATO defense ministers, the Ukraine-NATO Council, and a Ramstein-format meeting will take place at NATO headquarters in Brussels.
3X
Kyiv Independent on Dnipro river frontline: The drone war is just as much about the counter drone war.
Both sides bring strong electronic warfare assets. FPV teams need to fly out, learn where the Russian EW assets are, and then find a way through to hit their targets. 1/
Both sides bring strong electronic warfare assets. FPV teams need to fly out, learn where the Russian EW assets are, and then find a way through to hit their targets. 1/
“It is very difficult to dig in on the islands. Use shovel once and there is water. Evacuation and rotation are much more difficult. I stayed for 10 days because there was no possibility in the form of a boat. Getting into a boat to the island and from the island are the most emotional moments.” 2/
“Basically, war is war everywhere, so how, where, or in what direction it is doesn't really matter. It's scary everywhere. Now that I'm in Kherson, I feel more like I'm closer to home.” 3/

#Taldiacomahir de 1955 va néixer Enric Miralles, l'arquitecte català contemporani més reconegut arreu del món, juntament amb Bofill, i l'arquitectura del qual sovint relacionem amb Gaudí. Però què tenen a veure els dos arquitectes? i què en pensava Miralles sobre Gaudí? Fil ✍️

Miralles i Gaudí compartien una llibertat molt personal a l'hora de crear: la seva arquitectura no pot ser copiada. Això és l'ull central compartit entre els dos arquitectes. Però Gaudí, amb el seu ull blau clar, era un simbolista, i Miralles, amb el seu ull marró fosc, no tant.

Vistos així formen un ésser de tres ulls amb forma de cor, però no hi ha realment massa estima entre l'arquitectura d'aquests dos. Ambdós eren uns "nerds", dos intel·lectuals amb extensos coneixements sobre moltes coses, però els seus títols d'arquitecte estan separats 100 anys.

Macron: No peace without the Europeans. You can negotiate without the Europeans, but it will not bring peace at the table.
I decided to establish a direct channel of communication with Russia. We will be part of the solution, and we should be part of the discussion. 1/
I decided to establish a direct channel of communication with Russia. We will be part of the solution, and we should be part of the discussion. 1/
Macron: If we reach a settlement on Ukraine, we will still have to contend with an aggressive Russia, with a defensive industry on a sugar high, and a bloated army.
We will have to define rules of coexistence that limit the risk of escalation after a future ceasefire. 2/
We will have to define rules of coexistence that limit the risk of escalation after a future ceasefire. 2/
Macron: We have to be the one to negotiate new architecture of security for Europe the day after, because our geography will not change.
We will live with Russia at the same place. I don't want this negotiation to be organized by somebody else as Europeans. 3X
We will live with Russia at the same place. I don't want this negotiation to be organized by somebody else as Europeans. 3X

#Reiche gerät nach #Netzpaket-Leak unter Druck
Reiches Entwurf für eine umfangreiche Änderung des EEG und des EnWG erntet mittlerweile nicht nur Kritik von den #Grünen und Verbänden der #EE-Erzeuger, sondern auch von großen #Energiekonzernen...
1/19
t-online.de/heim-garten/ak…
Reiches Entwurf für eine umfangreiche Änderung des EEG und des EnWG erntet mittlerweile nicht nur Kritik von den #Grünen und Verbänden der #EE-Erzeuger, sondern auch von großen #Energiekonzernen...
1/19
t-online.de/heim-garten/ak…
2/19
..sowie der im Bund mitregierenden #SPD.
Der Chef von #RWE, Markus #Krebber, sagte dazu: "Das ist absurd". Die Redispatchkosten auf Erzeuger umzuwälzen, würde nur den "Schmerz" verlagern, ohne das Problem zu lösen. Denn die einzige Lösung für das Problem, das...
..sowie der im Bund mitregierenden #SPD.
Der Chef von #RWE, Markus #Krebber, sagte dazu: "Das ist absurd". Die Redispatchkosten auf Erzeuger umzuwälzen, würde nur den "Schmerz" verlagern, ohne das Problem zu lösen. Denn die einzige Lösung für das Problem, das...
3/19
...das Netzpaket in den Griff bekommen will, lautet: beschleunigter #Netzausbau und schnellere #Digitalisierung der Netze".
Ähnlich sieht das auch die energiepolitische Sprecherin der #SPD-Bundestagsfraktion Nina #Scheer den Gesetzentwurf. Sie betonte, der Umstieg auf...
...das Netzpaket in den Griff bekommen will, lautet: beschleunigter #Netzausbau und schnellere #Digitalisierung der Netze".
Ähnlich sieht das auch die energiepolitische Sprecherin der #SPD-Bundestagsfraktion Nina #Scheer den Gesetzentwurf. Sie betonte, der Umstieg auf...


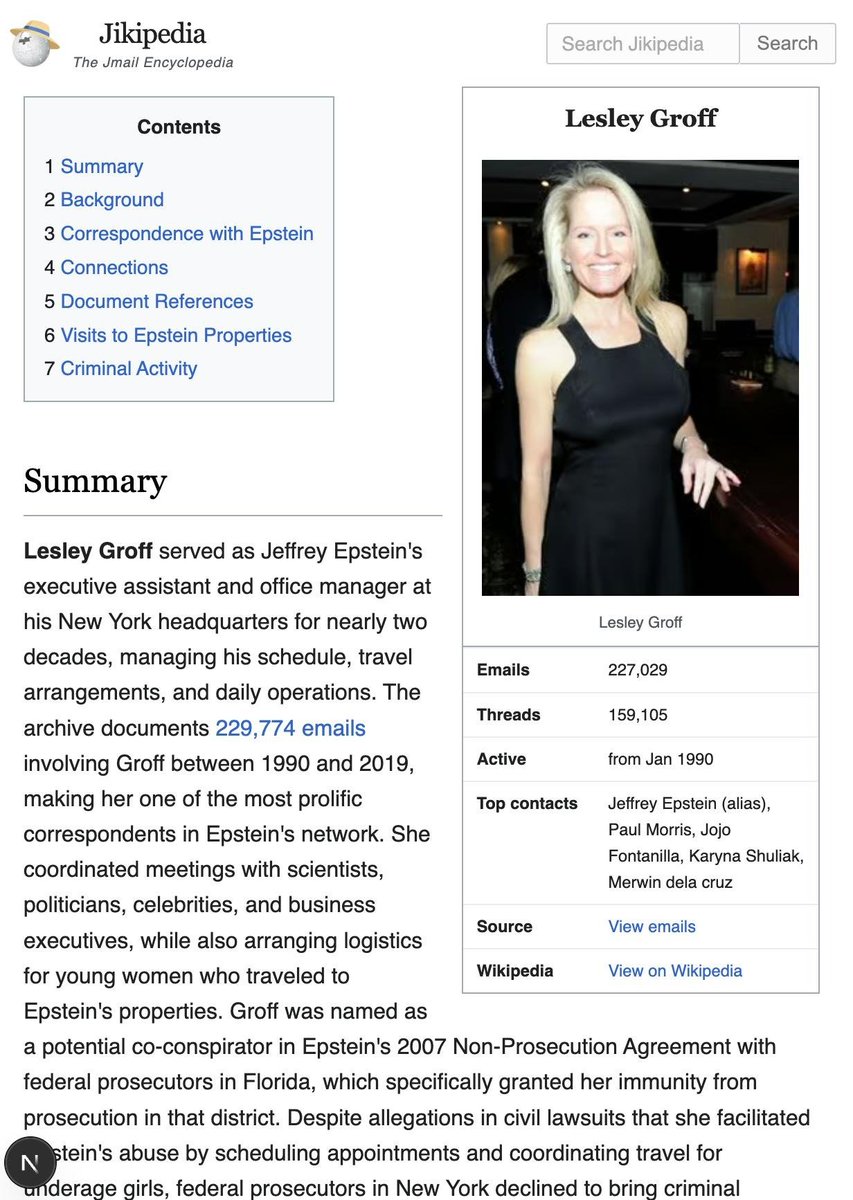
We built Jikipedia, a new wiki that compiles Jmail data into exhaustive reports on key figures in the Epstein scandal.
It lists all recorded visits to Epstein's estates, each person's possible knowledge of Epstein's crimes and laws that they may have violated.
Here is Epstein's executive assistant, who sent >100k emails to him and was shielded from prison via a 2007 non-prosecution deal.
It lists all recorded visits to Epstein's estates, each person's possible knowledge of Epstein's crimes and laws that they may have violated.
Here is Epstein's executive assistant, who sent >100k emails to him and was shielded from prison via a 2007 non-prosecution deal.
view at
The wiki cites US codes that people may be have been breaking as seen in the Jmail record.
We believe that the US government has a responsibility to fully investigate the people implicated by these files. jmail.world/wiki
The wiki cites US codes that people may be have been breaking as seen in the Jmail record.
We believe that the US government has a responsibility to fully investigate the people implicated by these files. jmail.world/wiki
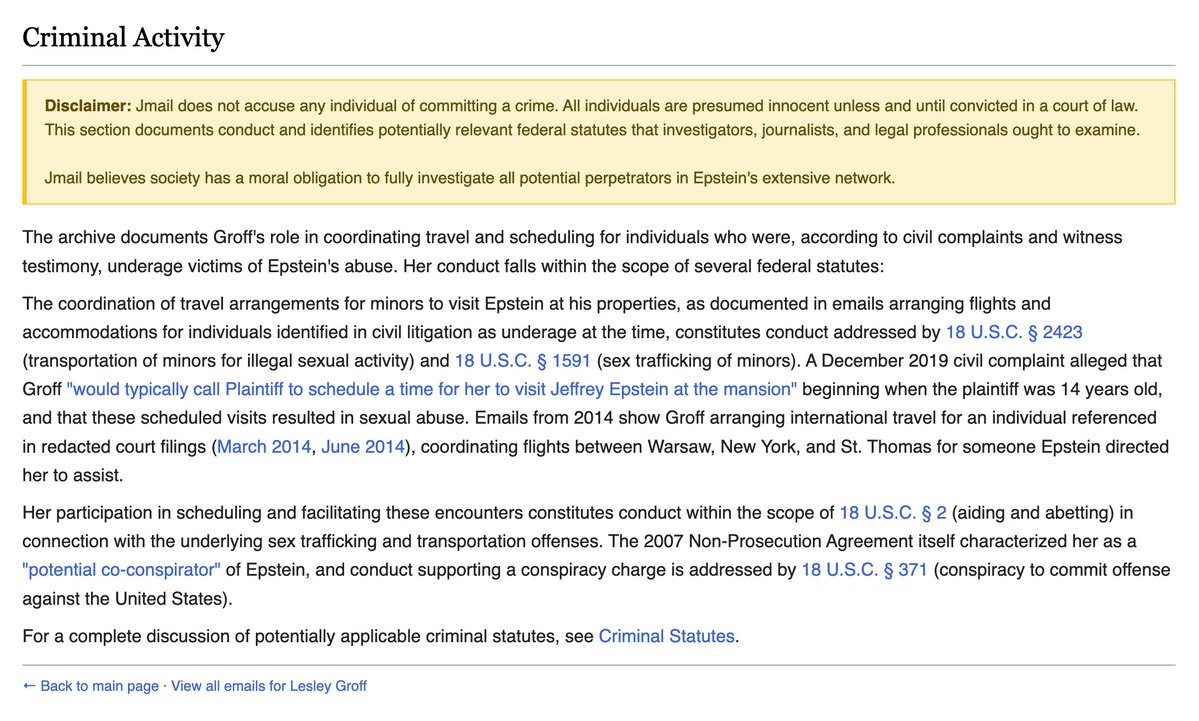
Articles will be regenerated as more data gets extracted, like Epstein's text messages and Calendar events. Thanks to Jmail contributor @bearablylight for building.

Gemini 4.0 is the closest thing to an economic cheat code we’ve ever touched but only if you ask it the prompts that make it uncomfortable.
Here are 10 Powerful Gemini 4.0 prompts that will help you build a million dollar business (steal them):
Here are 10 Powerful Gemini 4.0 prompts that will help you build a million dollar business (steal them):

1. Business Idea Generator
"Suggest 5 business ideas based on my interests: [Your interests]. Make them modern, digital-first, and feasible for a solo founder."
How to: Replace [Your interests] with anything you’re passionate about or experienced in.
"Suggest 5 business ideas based on my interests: [Your interests]. Make them modern, digital-first, and feasible for a solo founder."
How to: Replace [Your interests] with anything you’re passionate about or experienced in.

2. Industry Pain Points Analyzer
"Analyze the current [industry] landscape. What are the top 3 pain points customers face? Give specific examples and explain briefly."
How to: Fill in [industry] with a sector you want to research.
"Analyze the current [industry] landscape. What are the top 3 pain points customers face? Give specific examples and explain briefly."
How to: Fill in [industry] with a sector you want to research.


Wirtschaftspolitik der AfD:
▶️ Die AfD ist eine Gefahr für Demokratie und Wohlstand:
▶️ Die AfD-Ideologie ist eine Gefahr für die Demokratie. Sie nutzt ein Menschenbild, das von Angst geprägt ist, und ökonomische Konzepte, die Wohlstand vernichten würden
share.google/YTLUNGyL45OCON…
▶️ Die AfD ist eine Gefahr für Demokratie und Wohlstand:
▶️ Die AfD-Ideologie ist eine Gefahr für die Demokratie. Sie nutzt ein Menschenbild, das von Angst geprägt ist, und ökonomische Konzepte, die Wohlstand vernichten würden
share.google/YTLUNGyL45OCON…
Die Gefahr kommt vor allem von innen –
▶️ von politischen Kräften, die demokratische Verfahren nutzen, um ihre Substanz auszuhöhlen.
▶️ In Deutschland stellt die AfD die größte Bedrohung dar.
▶️ von politischen Kräften, die demokratische Verfahren nutzen, um ihre Substanz auszuhöhlen.
▶️ In Deutschland stellt die AfD die größte Bedrohung dar.
Sie ist nicht einfach eine radikale Protestbewegung, sondern eine Partei, deren Ziele und Ideologie das
▶️ FUNDAMENT unseres demokratischen Rechtsstaats bedrohen.
Kolumne von
Marcel Fratzscher
▶️ FUNDAMENT unseres demokratischen Rechtsstaats bedrohen.
Kolumne von
Marcel Fratzscher

הייתי בן 40 אתמול, קבלו 40 מחשבות על החיים.
1/40 אתם האחראים היחידים על החיים שלכם. אם תמיד אתם מאשימים גורם חיצוני במצב שאתם נמצאים בו אז אין מה לעשות ואתם סתם תהיו מדוכאים. רוצים להצליח? תניחו שזה עליכם ואף אחד לא יבוא לעזור. זה נכון לקריירה, לרומנטיקה, לספורט ובכלל.
1/40 אתם האחראים היחידים על החיים שלכם. אם תמיד אתם מאשימים גורם חיצוני במצב שאתם נמצאים בו אז אין מה לעשות ואתם סתם תהיו מדוכאים. רוצים להצליח? תניחו שזה עליכם ואף אחד לא יבוא לעזור. זה נכון לקריירה, לרומנטיקה, לספורט ובכלל.

2/40 אף פעם לא מאוחר מדי לעשות חברים. חלק מהאנשים שאני איתם (פיזית או וירטואלית) הכי הרבה והם חלק גדול מחיי הם כאלה שלא ידעתי מי הם לפני פחות מ-5 שנים. רק אחד איתי 40 שנה.
3/40 יש הילה סביב הקונספט של יזמות. לא כולם צריכים להיות יזמים ואפשר להיות מצליחים, עשירים ומאושרים גם כשכירים.

"अनिल अंबानी, इंडिया, न्यूयॉर्क ला भेटायला एप्रिल च्या पहिल्या आठवड्यात येत आहे. मोदी मे मध्ये येत आहे"
पिडोफाईल गलिच्छ व नीच गुन्हेगार जेफ्री एपस्टीन च्या ईमेल मधला संवाद.
६ फेब्रुवारी २६ ला 'यु एस डिपार्टमेंट ऑफ जस्टीस' च्या वेबसाईट वर 'एपस्टीन फाईल्स मध्ये INDIA शोधलं तर
पिडोफाईल गलिच्छ व नीच गुन्हेगार जेफ्री एपस्टीन च्या ईमेल मधला संवाद.
६ फेब्रुवारी २६ ला 'यु एस डिपार्टमेंट ऑफ जस्टीस' च्या वेबसाईट वर 'एपस्टीन फाईल्स मध्ये INDIA शोधलं तर
४८४ पेजेस उघडत होती, त्यात प्रत्येक पेजवर १० डॉक्युमेंट्स होते. नंतर पेजेस कमी होऊन ४७८ झाली, म्हणजे ६० कागदपत्र गायब!
त्यानंतर इंटरनॅशनल पीस इन्स्टिट्युट आणि जोशुआ फिंक चे पेपर्स गायब होऊ लागले...
संबंध काय?
हरदीप पुरी भाजप जॉईन करण्या आधी इंटरनॅशनल पीस सोबत होता,
त्यानंतर इंटरनॅशनल पीस इन्स्टिट्युट आणि जोशुआ फिंक चे पेपर्स गायब होऊ लागले...
संबंध काय?
हरदीप पुरी भाजप जॉईन करण्या आधी इंटरनॅशनल पीस सोबत होता,
आणि जोशुआ फिंक हा ब्लॅक रॉक च्या लॅरी फिंक चा मुलगा ज्याने अदानी च्या बॉण्ड मध्ये गुंतवणूक केली होती.
यांचे संबंध एपस्टीन फाईल्स मध्ये होते
आता या गायब कागदांसाठी भारताला काय काय त्याग करावा लागला, लागतोय, लागेल ते समोर येईलच.
त्याहून महत्वाचं म्हणजे जेफ्री एपस्टीन ला पितृस्थानी
यांचे संबंध एपस्टीन फाईल्स मध्ये होते
आता या गायब कागदांसाठी भारताला काय काय त्याग करावा लागला, लागतोय, लागेल ते समोर येईलच.
त्याहून महत्वाचं म्हणजे जेफ्री एपस्टीन ला पितृस्थानी
Rubio: We don’t know if the Russians are serious about ending the war in Ukraine. They say they are.
We don’t know under what terms they’re willing to do it, or whether terms acceptable to Ukraine would ever be accepted by Russia. But we’re going to continue to test it. 1/
We don’t know under what terms they’re willing to do it, or whether terms acceptable to Ukraine would ever be accepted by Russia. But we’re going to continue to test it. 1/
Rubio on Ukraine peace talks: Here’s the good news. The issues that must be confronted to end this war have been narrowed.
The bad news is they’ve been narrowed to the hardest questions to answer. And work remains to be done on that front. 2/
The bad news is they’ve been narrowed to the hardest questions to answer. And work remains to be done on that front. 2/
Rubio: It would be geopolitical malpractice not to engage China. Our national interests will often clash.
We expect China to act in its own interest, as we do in ours. The purpose of diplomacy is to manage those conflicts and strive to resolve them peacefully. 3X
We expect China to act in its own interest, as we do in ours. The purpose of diplomacy is to manage those conflicts and strive to resolve them peacefully. 3X

1 HILO LIDERES EUROPEOS DESESPERADOS POR ENTRAR EN GUERRA
Parece absurdo porque nadie quiere ser movilizado para ir a morir a un frente lejano.
Pero los Lideres necesitan una guerra
Parece absurdo porque nadie quiere ser movilizado para ir a morir a un frente lejano.
Pero los Lideres necesitan una guerra
2 Europa está en quiebra
Las élites corruptas nos han endeudado más allá de cualquier posibilidad de pago
La Brillante solución, Comisión de Helsinki fue:
"Balcanizamos Rusia y nos quedamos con sus materias primas, 60 Billones de euros"
Pero la cosa no salió como esperaban
Las élites corruptas nos han endeudado más allá de cualquier posibilidad de pago
La Brillante solución, Comisión de Helsinki fue:
"Balcanizamos Rusia y nos quedamos con sus materias primas, 60 Billones de euros"
Pero la cosa no salió como esperaban

3 En realidad Rusia ha ganado la guerra, pero la UE se ha gastado T-O-D-O en armar Ucrania y no pueden admitirlo.
Su "solución" entrar en guerra contra Rusia
¿Piensan ganarla? NO. No pueden
¿Entonces?eleconomista.es/mercados-cotiz…
Su "solución" entrar en guerra contra Rusia
¿Piensan ganarla? NO. No pueden
¿Entonces?eleconomista.es/mercados-cotiz…

@GibsTweets_KF @d33p3r4m4 Hey I thought you might like this. It's Jersh defending hosting a board for pedophiles to discuss being pedophiles. He's a proud, unabashed pedophile enabler. Because of "free speech."
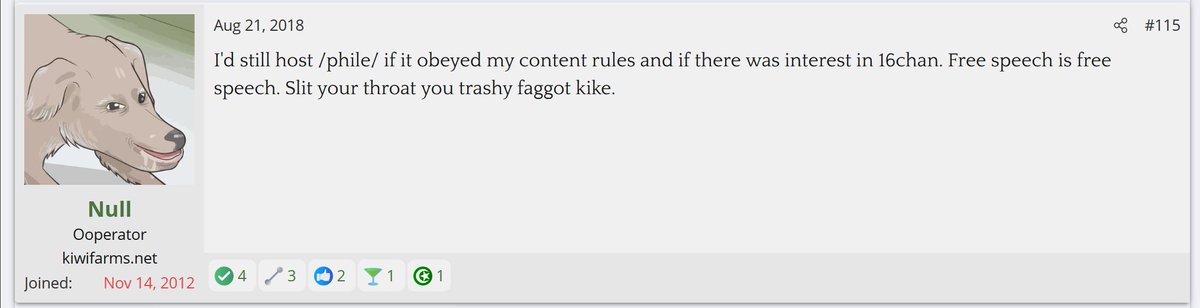
@GibsTweets_KF @d33p3r4m4 Here he is also calling this character "fucking hot." I understand you and the rest of his cocksuckers bought into the "age appropriate neko shota" line, but he was 15 when he wrote this and this is clearly a little girl.

@GibsTweets_KF @d33p3r4m4 Erm..............................................
