
There's a lot of questions abt smaller, open source LLMs vs larger, closed models for tasks like question answering. So, we added @MosaicML MPT-7B & @lmsysorg Vicuna-13b to @LangChainAI auto-evaluator. You test them on your own Q+A use-case ... autoevaluator.langchain.com/playground 

... great pod w/ @jefrankle @swyx @abhi_venigalla on MPT-7B, so used auto-evaluator to benchmark it on a test set of 5 Q+A pairs from the GPT3 paper. Results are close to larger models and it's very fast (kudos to @MosaicML inference team!) ...
https://twitter.com/karpathy/status/1660824101412548609?s=20

... @sfgunslinger also deployed Vicuna-13b on @replicatehq and it achieves performance parity w/ the larger models on this test set. Prompt eng may further improve this (v helpful discussion w/ the folks at @replicatehq / @JoeEHoover); we are looking into improving latency ...

... @AnthropicAI Claude-100k (discussed in more depth below) is very impressive for a "retriever-free" approach (pass the full 75 pg GPT3 pdf into the model's context window!), but costs higher latency ...
https://twitter.com/RLanceMartin/status/1658499575626465283?s=20

... @swyx @transitive_bs and @simonw make the interesting point that smaller (open source) models as "reasoning engines" coupled to retrievers (to fetch relevant data) may be sufficient for many apps (Q+A, agents, etc). It's def worth testing them.
https://twitter.com/swyx/status/1654214894923960320?s=20
... all auto-evaluator code is open source here:
github.com/langchain-ai/a…
github.com/langchain-ai/a…
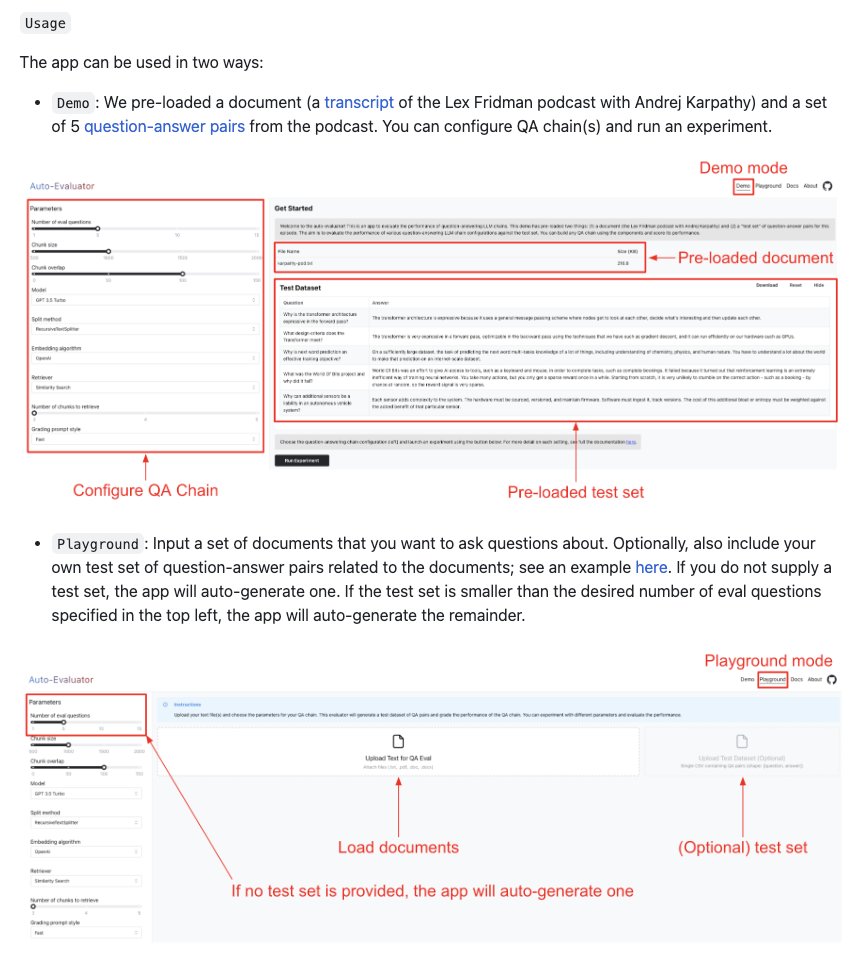
... and on app usage: in "Playground" simply upload any PDF doc. The app will use an LLM to auto-generate a Q+A eval set, run on a user-selected chain (model, retriever, etc) built w/ @LangChainAI, use a GPT4 to grade, and store each expt for you.
• • •
Missing some Tweet in this thread? You can try to
force a refresh















