
📜🚨📜🚨
NN loss landscapes are full of permutation symmetries, ie. swap any 2 units in a hidden layer. What does this mean for SGD? Is this practically useful?
For the past 5 yrs these Qs have fascinated me. Today, I am ready to announce "Git Re-Basin"!
arxiv.org/abs/2209.04836
NN loss landscapes are full of permutation symmetries, ie. swap any 2 units in a hidden layer. What does this mean for SGD? Is this practically useful?
For the past 5 yrs these Qs have fascinated me. Today, I am ready to announce "Git Re-Basin"!
arxiv.org/abs/2209.04836
We show that NN loss landscapes contain effectively only a single basin(!) provided sufficient width. Even better, we develop practical algos to navigate these basins...
Say you train Model A.
Independently, your friend trains Model B, possibly on different data.
With Git Re-Basin, you can merge models A+B in weight space at _no cost to the loss_
Independently, your friend trains Model B, possibly on different data.
With Git Re-Basin, you can merge models A+B in weight space at _no cost to the loss_
Git Re-Basin applies to any NN arch & we provide the first-ever demonstration of zero-barrier linear mode connectivity between two independently trained (no pre-training!) ResNets.
Put simply: a ResNet loss landscape contains only a single basin & we have algo to prove it
Put simply: a ResNet loss landscape contains only a single basin & we have algo to prove it
Phenomenon #1: "merge-ability" is an emergent property of SGD training -> merging at init doesn't work but a phase transition occurs such that it becomes possible over time 
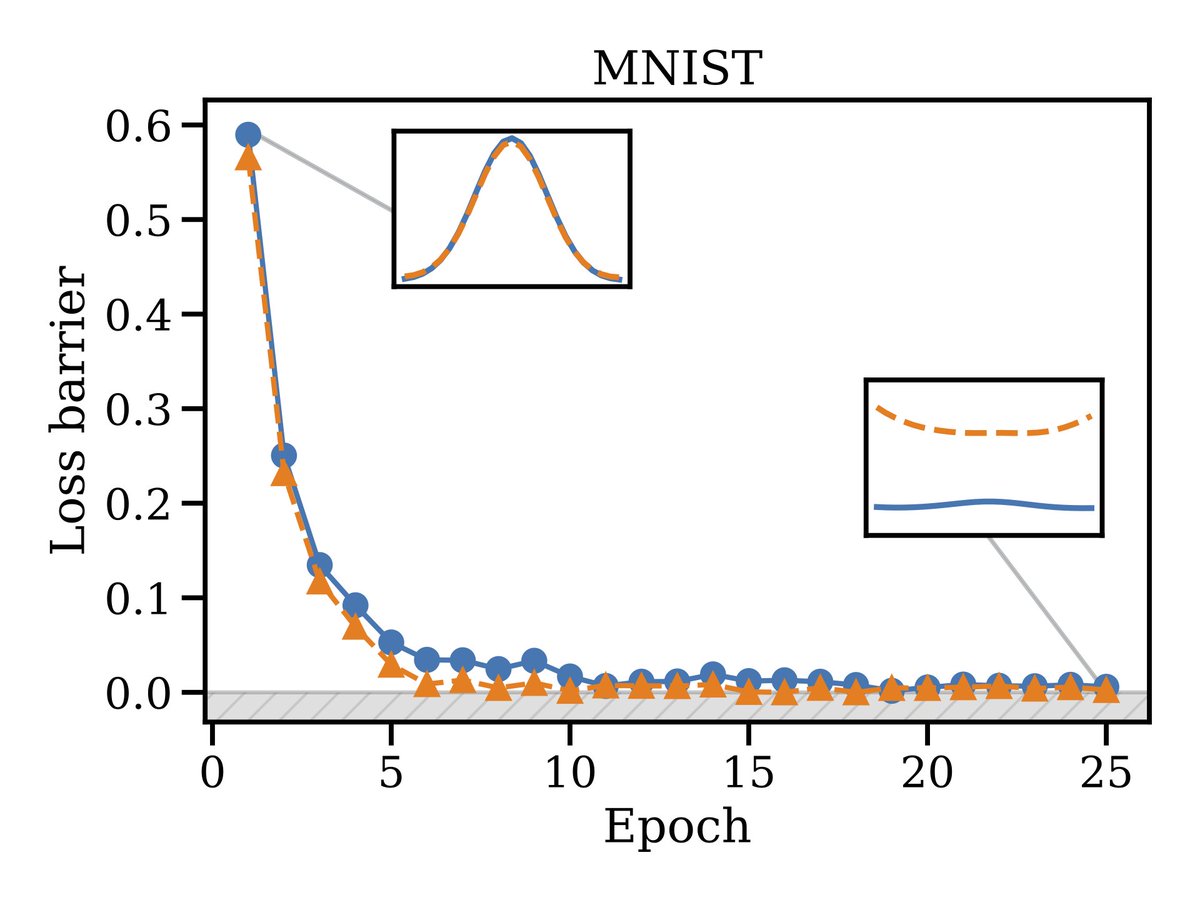

Phenomenon #2: Model width is intimately related to merge-ability: the wider the better. Not too burdensome of a constraint since we're all training in the wide/overparameterized regime anyways. Important nonetheless...


Also, not all arch's are equally mergeable: VGGs seem to be harder than ResNets 🤷♂️ We hypothesize that merge-ability is an indicator of compatible data/arch fit.
Finally, my fav result: it's possible to train models on disjoint and biased datasets, then merge them together in weight space.
Eg, you have some data in US, some in EU. Can't mix data due to GDPR etc. Train separate models, merge weights -> generalize to the combined dataset!
Eg, you have some data in US, some in EU. Can't mix data due to GDPR etc. Train separate models, merge weights -> generalize to the combined dataset!

So there ya go: it's possible to mix trained models like mixing potions, no pre-training or fine-tuning necessary.
That said, there are still loads of open questions left! I'm v curious to see where LMC and model patching work goes in the future 🚀
That said, there are still loads of open questions left! I'm v curious to see where LMC and model patching work goes in the future 🚀
Also plenty of exciting possible applications to federated learning, distributed training, deep learning optimization, and so forth
Ok, that's enough for one thread... Check out algos, counterexamples, proofs, and more in
the paper (arxiv.org/abs/2209.04836)
and code (github.com/samuela/git-re…)
the paper (arxiv.org/abs/2209.04836)
and code (github.com/samuela/git-re…)
Joint work with Jonathan Hayase and @siddhss5. Inspired by work from @colinraffel, @rahiment, @jefrankle, @RAIVNLab folks, and many other beautiful people!
Shout out to @Mitchnw, @adityakusupati, @RamanujanVivek and others who came along the ride!
Shout out to @Mitchnw, @adityakusupati, @RamanujanVivek and others who came along the ride!
Oh I forgot to add: our weight matching algo (sec 3.2) runs in ~10 seconds. So you won't be waiting around all day!
• • •
Missing some Tweet in this thread? You can try to
force a refresh



