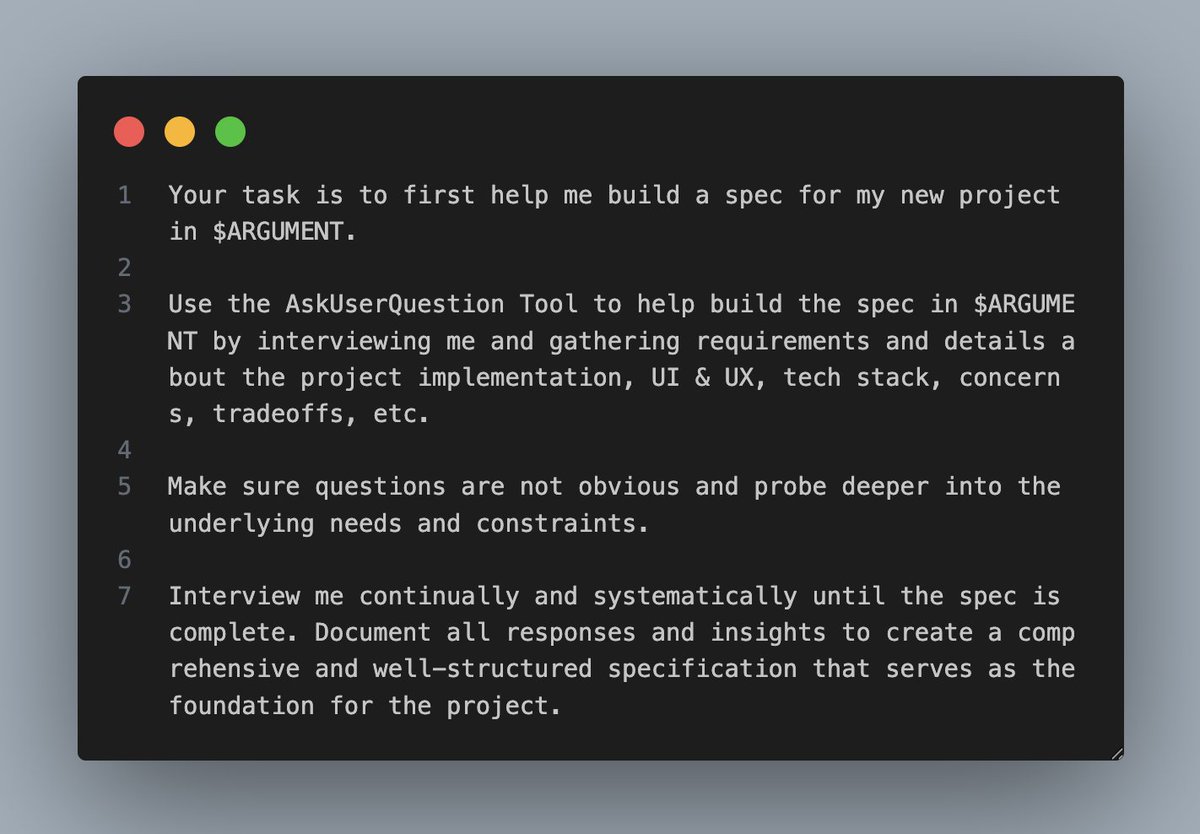
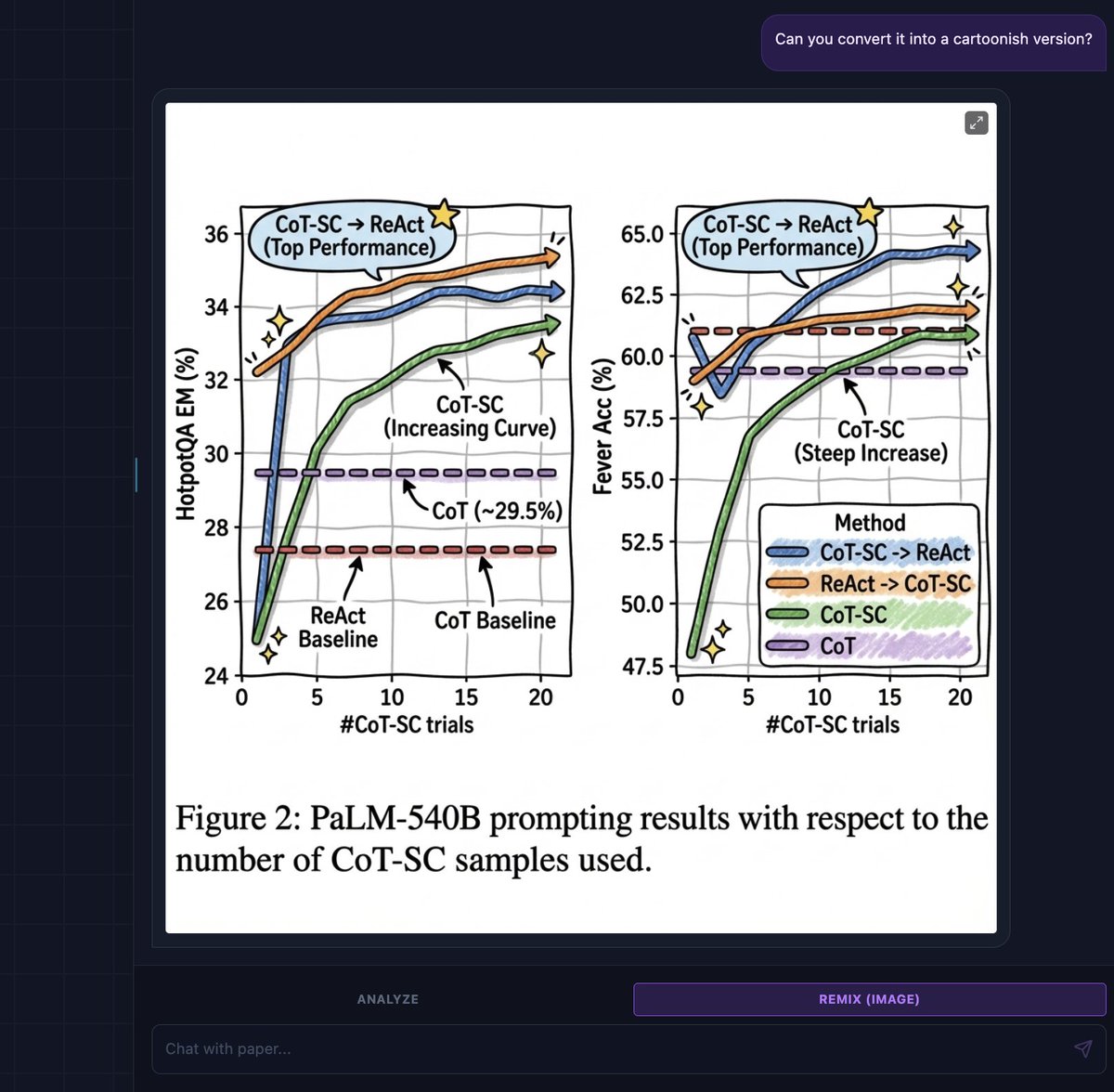
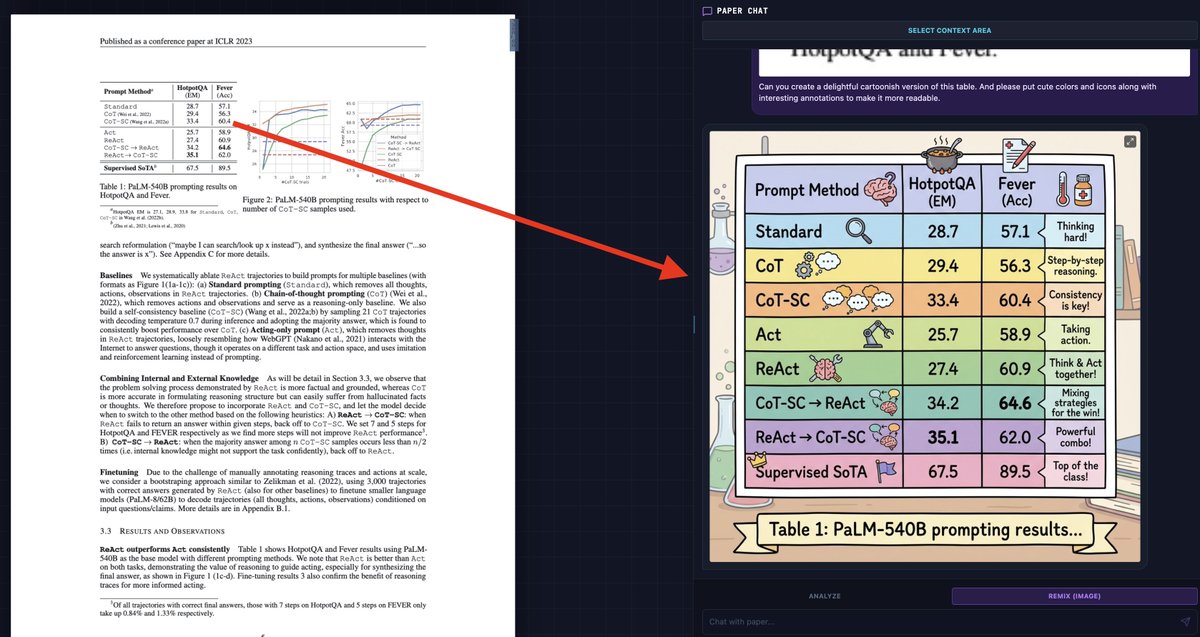
Takeaways/Observations/Advice from my #NeurIPS2018 experience (thread):
❄️(1): deep learning seems stagnant in terms of impactful and new ideas
❄️(1): deep learning seems stagnant in terms of impactful and new ideas
❄️(2): on the flip side, deep learning is providing tremendous opportunities for building powerful applications (could be seen from the amount of creativity and value of works presented in workshops such as ML for Health and Creativity)
❄️(3): the rise of deep learning applications is all thanks to the continued integration of software tools (open source) and hardware (GPUs and TPUs)
❄️(4): Conversational AI is important because it encompasses most subfields in NLP... also, embedding social capabilities into these type of AI systems is a challenging task but very important one going forward
❄️(5): it's important to start to think about how to transition from supervised learning to problems involving semi-supervised learning and beyond. Reinforcement learning seems to be the next frontier. BTW, Bayesian deep learning is a thing!?
❄️(6): we should not avoid the questions or the thoughts of inspiring our AI algorithms based on biological systems just because people are saying this is bad... there is still a whole lot to learn from neuroscience
❄️(7): when we use the word "algorithms" to refer to AI systems it seems to be used in negative ways by the media... what if we use the term "models" instead? (rephrased from Hanna Wallach)
❄️(8): we can embrace the gains of deep learning and revise our traditional learning systems based on what we have learned from modern deep learning techniques (this was my favorite piece of advice)
❄️(9): the ease of applying machine learning to different problems has sparked leaderboard chasing... let's all be careful of those short-term rewards
❄️(10): there is a ton of noise in the field of AI... when you read about AI papers, systems and technologies just be aware of that
❄️(11): causal reasoning needs to be paid close attention... especially as we begin to heavily use AI systems to make important decisions in our lives
❄️(12): efforts in diversification seems to have amplified healthy interactions between young and prominent members of the AI community
❄️(13): we can expect to see more multimodal systems and environments being used and leveraged to help with learning in various settings (e.g., conversation, simulations, etc.)
❄️(14): let's get serious about reproducibility... this goes for all sub-disciplines in the field of AI
❄️(15): more efforts need to be invested in finding ways to properly evaluate different types of machine learning systems... this was a resonant theme at the conference...from the NLP people to the statisticians to the reinforcement learning people... it's a serious problem
I will formalize and expound on all of these observations, takeaways, and advice learned from my NeurIPS experience in a future post (will be posted directly at @dair_ai)... at the moment, I am still trying to put together the resources (links, slides, papers, etc.)
• • •
Missing some Tweet in this thread? You can try to
force a refresh