
What happens when you launch Google Chrome for the first time on a Windows 10 machine?
When I launched Google Chrome for the first time (and let it sit for a minute), 32 requests were made, and 7.26 MB of data downloaded.
When I launched Google Chrome for the first time (and let it sit for a minute), 32 requests were made, and 7.26 MB of data downloaded.

The first call Chrome makes is to the googleapis domain. It passes my OS type, browser channel (Stable), and version (v76) along. The response is 32KB of flags, features, and more. Not clear what they all do (as many can't be found in Chromium source) but some are fairly clear.

The next call appears to try and communicate with the Google accounts server (already trying to pair me with a profile?). This call is to accounts.google.com, for the /ListAccounts path. The endpoint responds with ["gaia.l.a.r",[]], meaning no account was found (AFAIK).
Based on the following, I would expect a positive GAIA (Google Accounts and ID Administration) to return with my Google Email address. Since it didn't, I'm suspect they failed to pair to me anything.

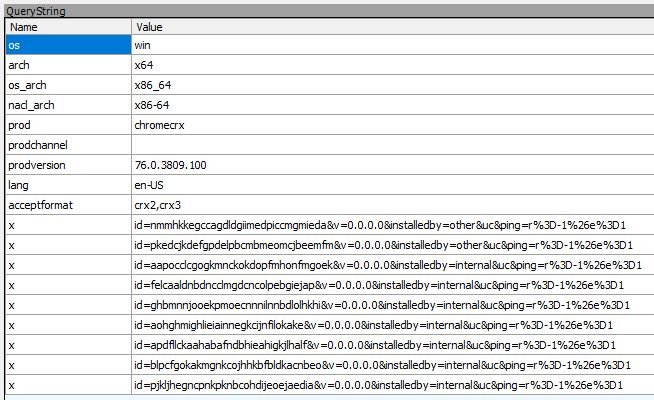
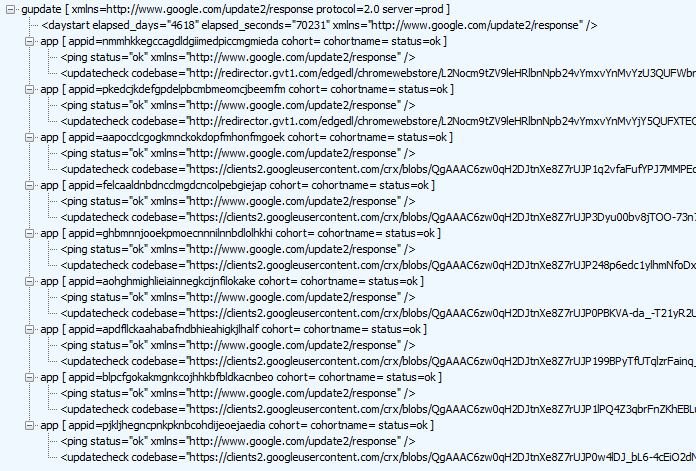
Chrome's next call is to the clients2.google.com endpoint. It passes quite a few extension/app IDs over the wire. Google responds with an XML document pointing towards endpoints in the Web Store that need to be queried. You see those queries later in the session list.
A brief tangent now; Chrome fires a request off to gstatic.com for some type of translation model. While the response isn't easy to parse, it holds numerous language codes (as we'd expect in this instance):

Back to the extension/app IDs we were investigating earlier. Chrome now begins to issue requests for the corresponding CRX files. The first request is for the Google Drive extension. Honestly, this hardly qualifies as an extension IMHO. One line of JavaScript and a manifest file.
There are 9 extensions downloaded during the first-run. They're mostly very small, and mainly related to Google Drive and Docs. Also an extension for YouTube, GMail, Chrome Cast, and Payments. Most of these can be seen on the /apps page in the browser itself.


The redirector.gvt1.com request is for Chrome Cast. It, for some reason, takes a different route than the other extensions. The same for their "craw" bits, which appear to be tied into Web Store Payments, judging by the locale files. I'm curious why these are served uniquely.

I should note, redirector.gvt1.com doesn't actually serve the extension bits. Instead, it does (as it's name suggests) a redirection. The path to which it directs us is quite odd: /r3---sn-8xgp1vo-5uae.gvt1.com. This pattern looks familiar for some reason—not sure why.
The last thing we see related to these initial extensions is a verify request for each. IDs are sent over the wire, and googleapis responds with a bit of data to check integrity.

That appears to be all of the extension-related work. Next the browser made a call out to docs.google.com. Why? No idea. But it 302s to accounts.google.com—to the /ServiceLogin endpoint. A custom header appears to store a client_id, as well as a device_id.

Next up is a request to Google's /searchdomaincheck endpoint. It simply responds with 'google.com'. I assume this is asking where search data should go, by default.

We now come to the very last call to clients2.google.com. At this point, it is confirming that none of the extensions need to be updated. What I find odd, though, is that the two which installed via redirector.* are recorded as 'installedby=other' instead of internal.

This wraps up the first-run experience for Google Chrome. Note, this is what happens before you do anything in the browser.
Searching for 'brave software' triggers numerous round-trips to Google for suggestions.
A few rows down, a prefetch for brave.com happens.
Searching for 'brave software' triggers numerous round-trips to Google for suggestions.
A few rows down, a prefetch for brave.com happens.
If you enjoyed this thread, be sure to check out these:
https://twitter.com/jonathansampson/status/1165392803687542790
• • •
Missing some Tweet in this thread? You can try to
force a refresh






