
In light of this question, I thought I'd do a little thread on purely practical event-study stuff.
No theory, just a bunch of pictures of how I make event-studies and what you get when you make different mistakes/choices.
No theory, just a bunch of pictures of how I make event-studies and what you get when you make different mistakes/choices.
https://twitter.com/nomadj1s/status/1165035394737590272?s=20
I do my event-studies totally by hand. I choose the omitted category, I deal with endpoints myself, and I make the dummies ahead of time.
Here's how:
Here's how:

Then I run my regression and either outreg2 (old) or regsave (newer) the results, add back in the omitted category, and dive into all the details of @Stata graphing syntax:
h/t to @saynikpay and @talgross for the horizontal y-axis labels:
h/t to @saynikpay and @talgross for the horizontal y-axis labels:
https://twitter.com/talgross/status/1128698178675585024?s=20

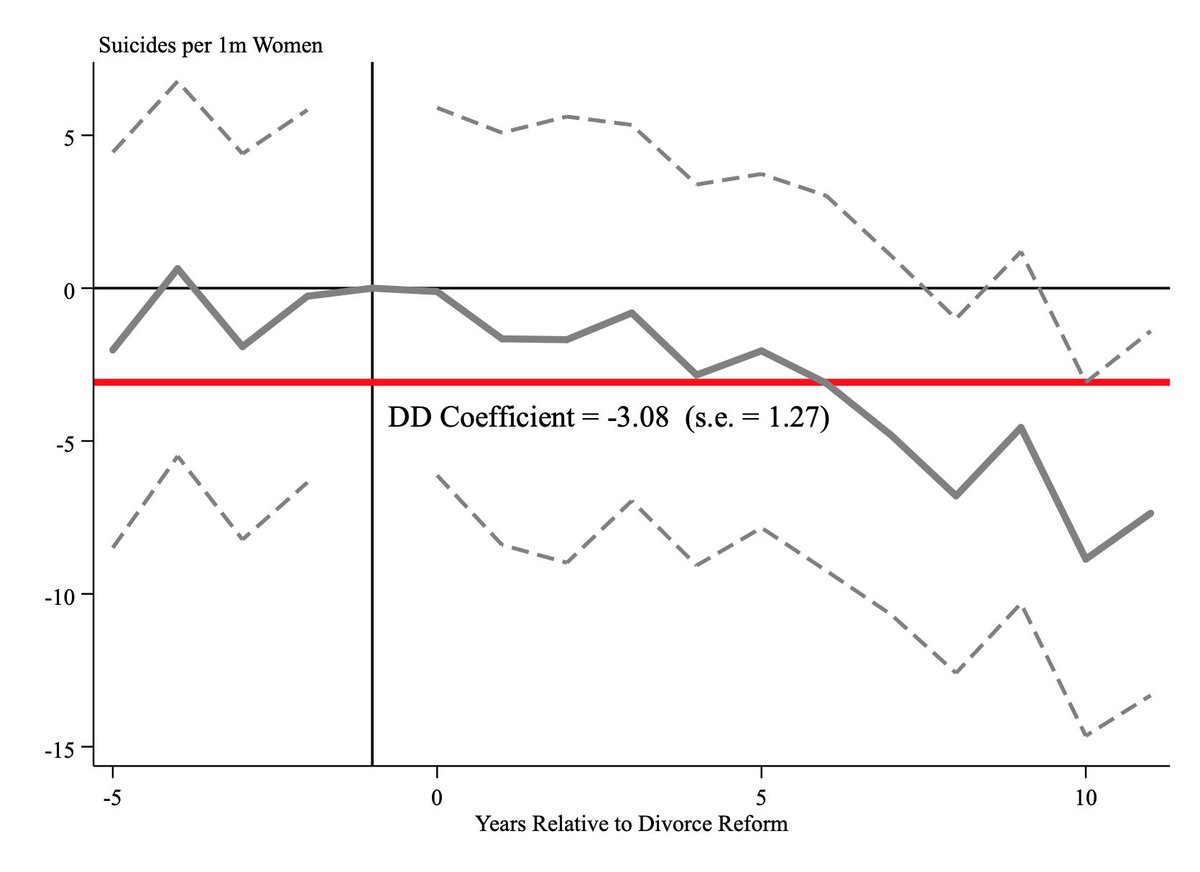
This produces @BetseyStevenson and @JustinWolfers nice event study for no-fault divorce and female suicide rates (which, btw, was so clearly written up that I nailed the figure with no replication files whatsoever!)
Only show coefs from "balanced" event-times. You see some units *way* before/after treatment, but only for the earliest or latest treated ones. Those coefs are partly driven by level diffs b/w units like here. See how weird and noisy things get at the ends? Those aren't "effects"

Bin up the end points (see recode statements above), and estimate those coefs, but do not report them. You can see when papers do this b/c there's a point on the x-axis that's like "12+" and the coef is way different.
Here they don't look that weird, but they often do.
Here they don't look that weird, but they often do.

Another option would be to estimate all the event-study coefs but only plot the balanced ones. I don't think it matters much and it really really doesn't matter here:

A very characteristic ES problem is when you forget to include those endpoints. Then "the" omitted category is a combination of -1 and the earliest/latest coefs. It produces a picture with an anomalous dip right at "-1":

I say omit -1, but some people like omitting other pre dummies. It just shifts the whole line. Here's what happens if you omit the earliest balanced pre dummy.
I think it makes the coefs hard to read, but its not a big deal really. (Don't omit unbalanced periods though)
I think it makes the coefs hard to read, but its not a big deal really. (Don't omit unbalanced periods though)

And for fun, lets pick on unit-specific linear trends. This example has no clear pre-trends (their intended target) but it does have time-varying effects (their unintended target). Trends ruin a perfectly good event-study for bad reasons. They just rotate the line around -1

And finally, let me plug my graphing style, which puts one line through coefs and one line through upper/lower CIs rather than connecting with vertical error bars. To me, lines make it easier to evaluate dynamics and approximate what you'd get if you had higher frequency data.
Oh, and I learned all of this working with @martha_j_bailey for the last 10 years!
• • •
Missing some Tweet in this thread? You can try to
force a refresh















