
What happens when you launch a fresh install of Firefox? I was curious, so I did so with version 68.0.2, and monitored my network activity.
Here's what I learned…
Here's what I learned…
Note, this doesn't involve any interaction beyond opening the browser and waiting a few minutes.
What I found were dozens of requests, which loaded nearly 16 MB in data. Lets break down what I saw.
What I found were dozens of requests, which loaded nearly 16 MB in data. Lets break down what I saw.

Let's first look at which endpoints were hit, and how often. Firefox launched with a mozilla.org tab opened in a blurred tab. Resources loaded from there would explain the 26 calls. Some of these other hosts should be familiar, if you've read my other browser threads.

The first 5 requests were for detectportal.firefox.com over the HTTP protocol. These are meant to detect public networks, like that available at the coffee shop. If the response does not contain 'success', it's a good indicator you're on a portal.

Next up were 2 identical requests for ocsp.digicert.com. OCSP is the Online Certificate Status Protocol, and is used to check for revocation of bad certs. I assume FF is testing its own certificate, since the browser opens with a Mozilla tab. No clue why it checked twice.
A call to snippets.cdn.mozilla.net is next. The path carries information about the device I am using: OS, 32 or 64 bit, lang, etc. The call redirects to 12 KB of JSON. Snippets are small messages displayed on the New Tab.
Two Remote Settings calls are made to the tiles.services.mozilla.com host. They are nearly identical bits of JSON. One is for the cfr provider, and the other is for cfr-fxa, per the github.com/mozilla/gecko/… resource. I have no remote settings, which explains ASR_RS_NO_MESSAGES.

A third "tiles.services.moz" call is made, with a different body. It contains a client_id. Along with it were a few other bits of data:
event=AS_ENABLED
locale=en-US
profile_creation_date=18134
region=UNSET
release_channel=release
topic=main
value=0
version=68.0.2
event=AS_ENABLED
locale=en-US
profile_creation_date=18134
region=UNSET
release_channel=release
topic=main
value=0
version=68.0.2
The mozilla.org tab discussing the importance of Privacy loads in the background, bringing along with it the Google Tag Manager and Google Analytics. Hello, Google.

It looks like we aren't done talking with Google either. Firefox makes its next move in downloading Safe Browsing bits from Google APIs. This is common among browsers today (Exception: @brave proxies the call through brave.com, keeping users out of Google's hands).
Next up, normandy.cdn.mozilla.net. Mozilla says it "…is a feature that allows Mozilla to change the default value of a preference for a targeted set of users, without deploying an update to FF." It returns a JSON file with a handful of URLs. Firefox will use these URLs at times.

In fact, part of the Normandy response included a URL for the classify-client action. Firefox makes a call for that next. The server returns a bit of JSON that specifies the users country, and a request time:
{"country":"US","request_time":"2019-08-26T02:41:45.823283Z"}
{"country":"US","request_time":"2019-08-26T02:41:45.823283Z"}
The Normandy work doesn't stop there. Next we see calls to firefox.settings.services.mozilla.com. Each with a different path. The first request carries the bits that make up the path for the second request. And the third looks like the Snippets file from earlier.



The last normandy response above then instructs Firefox to download numerous certificates from content-signature-2.cdn.mozilla.net.
At this point, Firefox takes a break and checks for available updates. It doesn't find any, so we get an XML response with an empty <updates> object.
At this point, Firefox takes a break and checks for available updates. It doesn't find any, so we get an XML response with an empty <updates> object.

Another Normandy call to retrieve settings is made. This one results in a large list of buckets or records; I'm not sure of the nomenclature here. Either way, we see numerous calls for more data made as a result. For instance, "Have I Been Pwned" data is retrieved.

After a few more normandy calls, we now see a request to the aus5 sub on mozilla.org. This also passes device information, resulting in an XML response containing addons to download/install. The OpenH264 addon is requested over HTTP. I hope they do integrity checking!
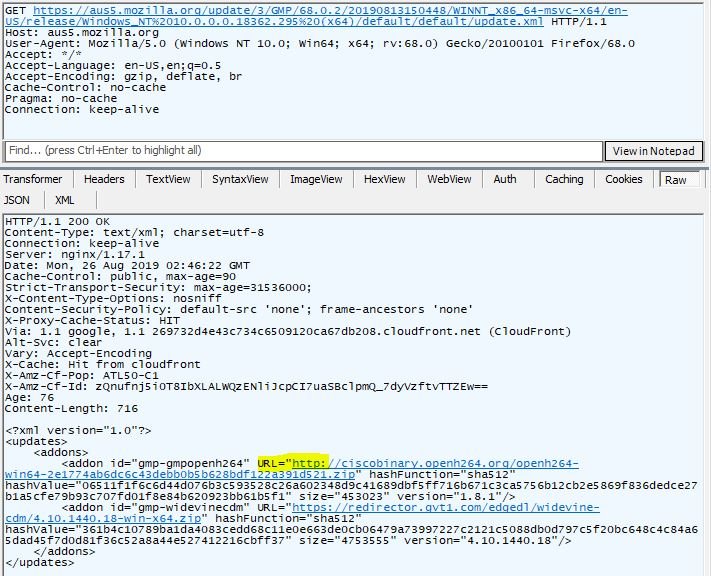
Also, it looks like these identical files are being downloaded twice. Is it a coincidence that Firefox opens with 2 tabs, and makes 2 identical calls?
The 2nd addon is WideVine. This is requested directly from Google's gvt1.com domain. Hello again, Google.
The 2nd addon is WideVine. This is requested directly from Google's gvt1.com domain. Hello again, Google.
Firefox has been open for a few minutes, and Mozilla would like to know about me, my machine, and how I have Firefox configured. 37,097 bytes of information are sent to incoming.telemetry.mozilla.org.

Of all browsers I've reviewed recently, Firefox is one of the most active upon installation. I think it may be the only one to immediately collect telemetry data too.
I would like to see them proxy calls to Google endpoints, and avoid the initial mozilla.org tab.
I would like to see them proxy calls to Google endpoints, and avoid the initial mozilla.org tab.
That pretty much covers what Firefox does when you first run the browser after installation.
If you enjoyed this thread, see the others I did on Opera, Vivaldi, Brave, Dissenter, and Chrome.
Take care!
If you enjoyed this thread, see the others I did on Opera, Vivaldi, Brave, Dissenter, and Chrome.
Take care!
https://twitter.com/jonathansampson/status/1165392803687542790
I also reviewed Google Chrome, for those interested:
https://twitter.com/jonathansampson/status/1165493206441779200
• • •
Missing some Tweet in this thread? You can try to
force a refresh






