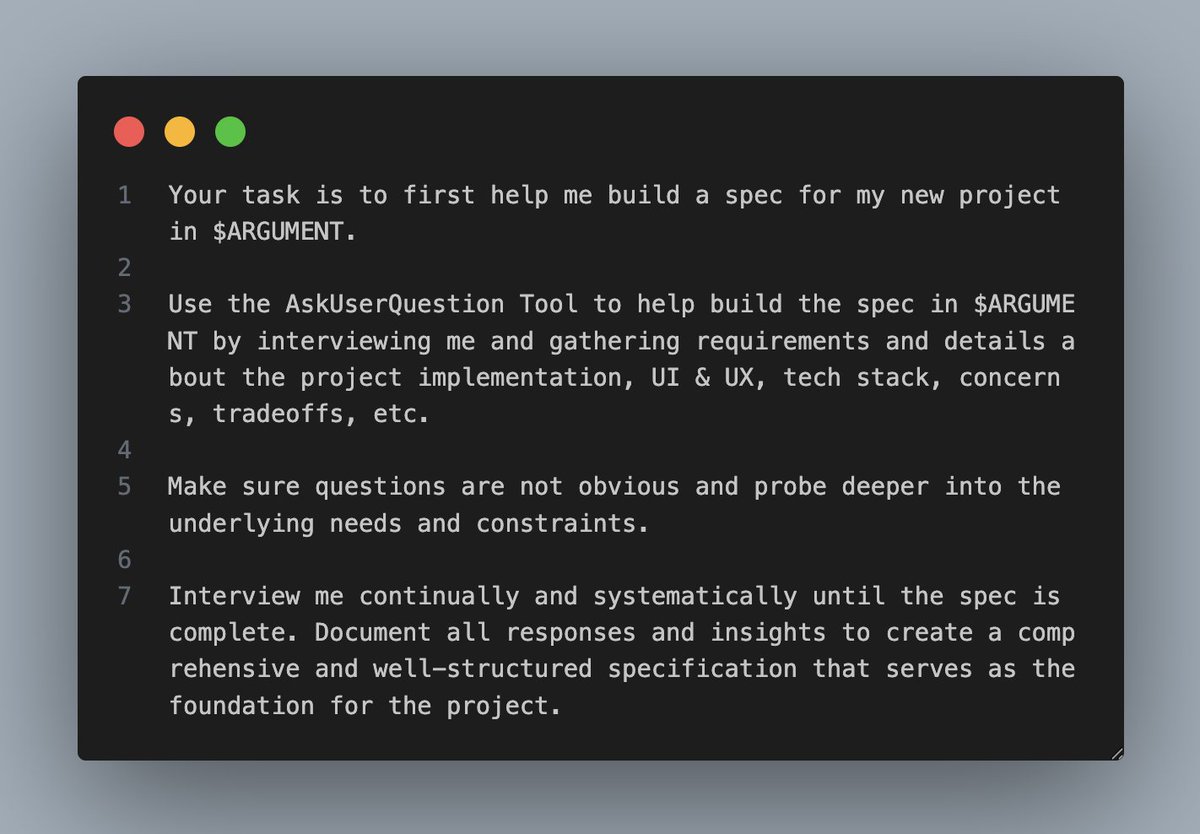
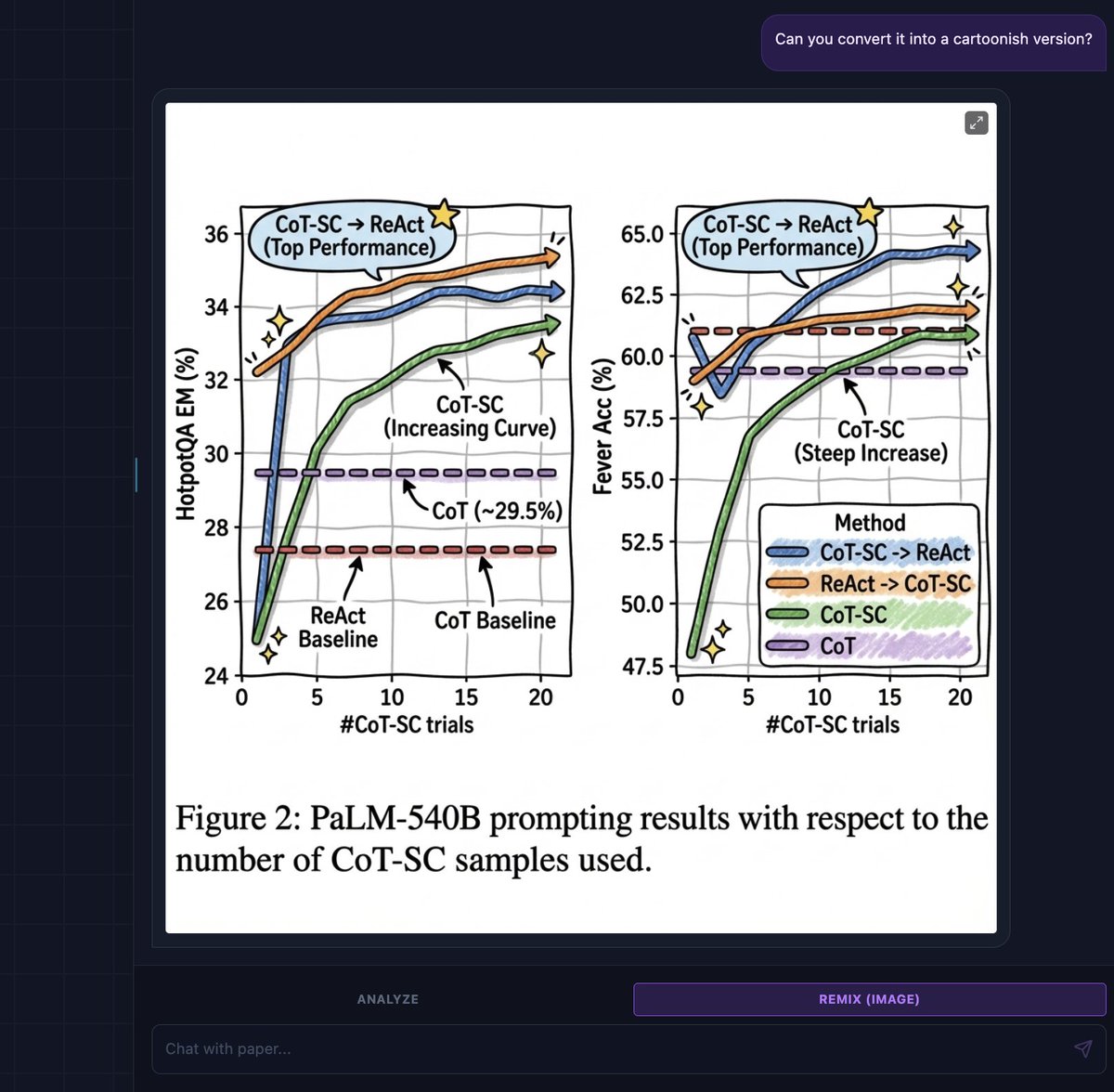
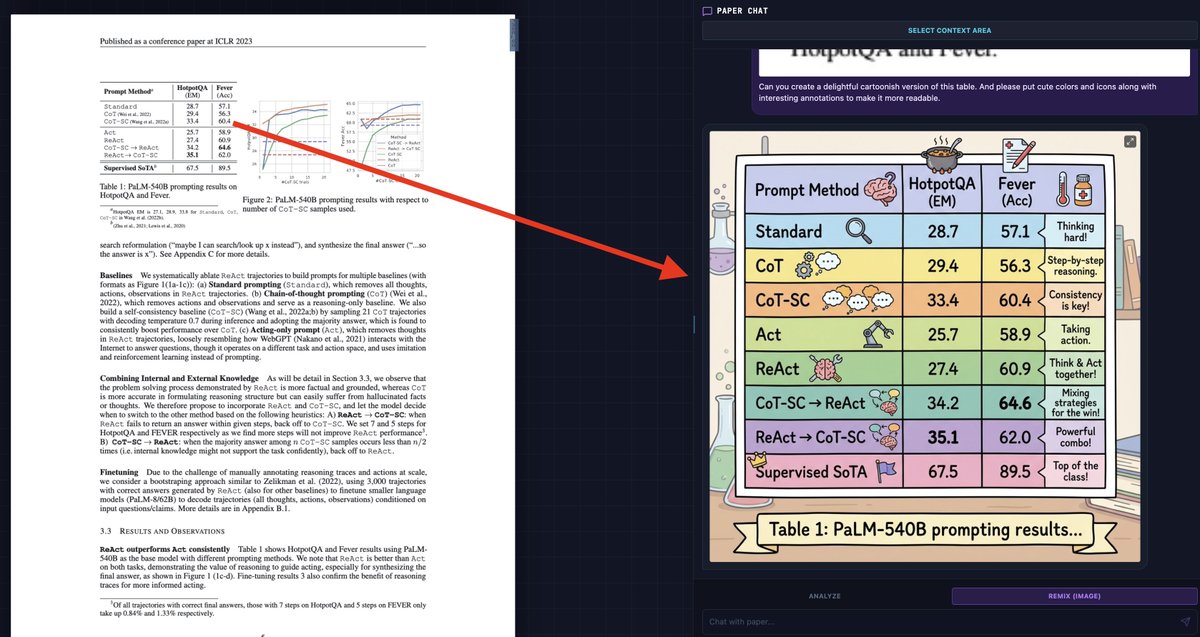
Machine learning for single cell biology: insights and challenges by Dana Pe’er. #NeurIPS2019 

The representation challenge

On visualizing and modeling the data



On clustering single sell data

The challenge of inferring temporal progression of cell phenotype

An effort to map different cell types


There exist many challenges on how to analyze cell data

Data harmonization is a critical challenge

Ways in how deep learning is used in cell understanding

👏

Other challenges

Understanding response to therapy

Segmenting and analyzing cells is challenging




• • •
Missing some Tweet in this thread? You can try to
force a refresh