
When a model predicts a label with a given score, what does that score represent? We'll try to answer that on today's #IDATHAINSIGHTS thread 🧵- 1/22 

2/22 - Usually, it is used and documented as a measure of how confident the model is about it's prediction. Sometimes it's also interpreted as a probability. But wait, a probability of what?
#IDATHAINSIGHTS
#IDATHAINSIGHTS

3/22 - Strictly speaking, in order for it to be a probability, it just needs to follow these two rules: 👇
- it has to be a value between 0 and 1
- the sum of all possible values must be 1
en.m.wikipedia.org/wiki/Probabili…
#IDATHAINSIGHTS
- it has to be a value between 0 and 1
- the sum of all possible values must be 1
en.m.wikipedia.org/wiki/Probabili…
#IDATHAINSIGHTS
4/22 - Usually, the output layer of a #NeuralNetwork (NN) is a softmax layer, which guarantees both rules are satisfied.
en.wikipedia.org/wiki/Softmax_f…
#IDATHAINSIGHTS
en.wikipedia.org/wiki/Softmax_f…
#IDATHAINSIGHTS
5/22 - But is this enough to give to a certain value like 0.98 a probabilistic interpretation? 🤔
#IDATHAINSIGHTS
#IDATHAINSIGHTS
6/22 - Well, it turns out that if you just draw random scores, and apply a #softmax layer on them, you end up with confidence scores which add up to one and are between 0 and 1: a probability measure, but a useless one. We'll need more than this
#IDATHAINSIGHTS
#IDATHAINSIGHTS
7/22 - Of course a #NeuralNetwork is much more than a random number generator: all its layers are trained to minimize an error function, which is usually the cross entropy.
#IDATHAINSIGHTS
#IDATHAINSIGHTS
8/22 - When a model is trained to minimize cross entropy, and uses a softmax layer as an output layer, it can be shown that the cross entropy is minimized when the output of the system coincides with the posterior of the classes given the samples.
#IDATHAINSIGHTS
#IDATHAINSIGHTS
9/22 - This is the reason why we think that the output of the system should be posteriors: the probability of this class being the correct, given this sample. 👌
#IDATHAINSIGHTS
#IDATHAINSIGHTS
10/22 - So, in practice, ¿What do we expect from a 0.98 score? It's desirable that if this is actually a posterior, then 98% of the predictions with 0.98 confidence should be correct, and the other 2 should not.
#IDATHAINSIGHTS
#IDATHAINSIGHTS
11/22 - When this happens, we say that the model is calibrated: the scores modeled as probabilities are also verified in practice. However, it is also known that modern NN on practice are really badly calibrated.
arxiv.org/pdf/1706.04599…
#IDATHAINSIGHTS
arxiv.org/pdf/1706.04599…
#IDATHAINSIGHTS
13/22 - All we need to do is to construct a histogram on the confidence scores values. Suppose it has 10 bins, and then, on each bin, the samples on it should have exactly the same accuracy the bin represents.
#IDATHAINSIGHTS
#IDATHAINSIGHTS
14/22 - Otherwise, the model is uncalibrated and you should not interpret its scores as probabilities. The diagrams in the image are called "reliability diagrams".
#IDATHAINSIGHTS
#IDATHAINSIGHTS
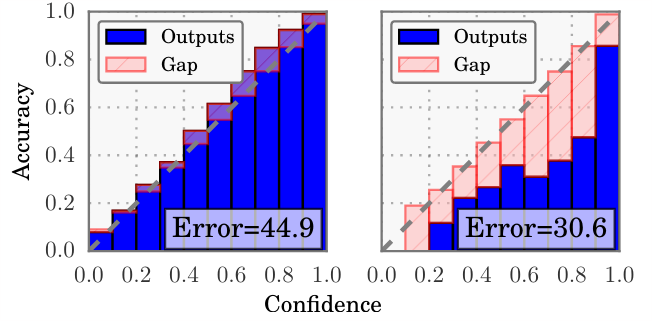
15/22 - There is a good amount of ways to measure this miscalibration, one of the most common is Expected Calibration Error (ECE), as defined in the picture. If you want to read more on the pros & cons of different metrics, checkout this paper 📃
openaccess.thecvf.com/content_CVPRW_…
openaccess.thecvf.com/content_CVPRW_…

16/22 - Well, but, if there are theoretical guarantees that cross entropy + softmax output posteriors, why are modern NNs so badly calibrated?
#IDATHAINSIGHTS
#IDATHAINSIGHTS
17/22 - There are several things that contribute to that: batch normalization, depth & width of the NN for instance. They generally lead to more accurate models but at the expense of miscalibration.
#IDATHAINSIGHTS
#IDATHAINSIGHTS
18/22 - In addition to this, the distribution of the training data is usually modified to improve the training process.
#IDATHAINSIGHTS
#IDATHAINSIGHTS
19/22 - It's also important to know that even if our models are really poorly calibrated, they still are capable of predicting the right class. That is because calibration and discrimination are not dependent on each other. 🔷
#IDATHAINSIGHTS
#IDATHAINSIGHTS
20/22 -
Discrimination: how well the scores separate the classes
Calibration: whether those scores can be interpreted probabilistically.
#IDATHAINSIGHTS
Discrimination: how well the scores separate the classes
Calibration: whether those scores can be interpreted probabilistically.
#IDATHAINSIGHTS
21/22 - Should you worry about miscalibration then? Well, it depends on your use case. If you just want to minimize a classification metric (accuracy, f-score, etc.), you may not care, but if you need your scores to be posteriors, you should fix it. How to do it? Stay tuned 😜
22/22 - Interested in this topic? Checkout Luciana Ferrer's great talk at @Khipu_AI 🙌
tv.vera.com.uy/video/55289
References: 📃
drive.google.com/file/d/1j7lykM…
scikit-learn.org/stable/modules…
cs231n.stanford.edu
tv.vera.com.uy/video/55289
References: 📃
drive.google.com/file/d/1j7lykM…
scikit-learn.org/stable/modules…
cs231n.stanford.edu

