
Really existed about our #UAI2020 paper with @IAugenstein & @vageeshsaxena.
TX-Ray: interprets and quantifies adaptation/transfer during self-supervised pretraining and supervised fine-tuning -- i.e. explores transfer even without probing tasks. #ML #XAI
arxiv.org/abs/1912.00982
TX-Ray: interprets and quantifies adaptation/transfer during self-supervised pretraining and supervised fine-tuning -- i.e. explores transfer even without probing tasks. #ML #XAI
arxiv.org/abs/1912.00982
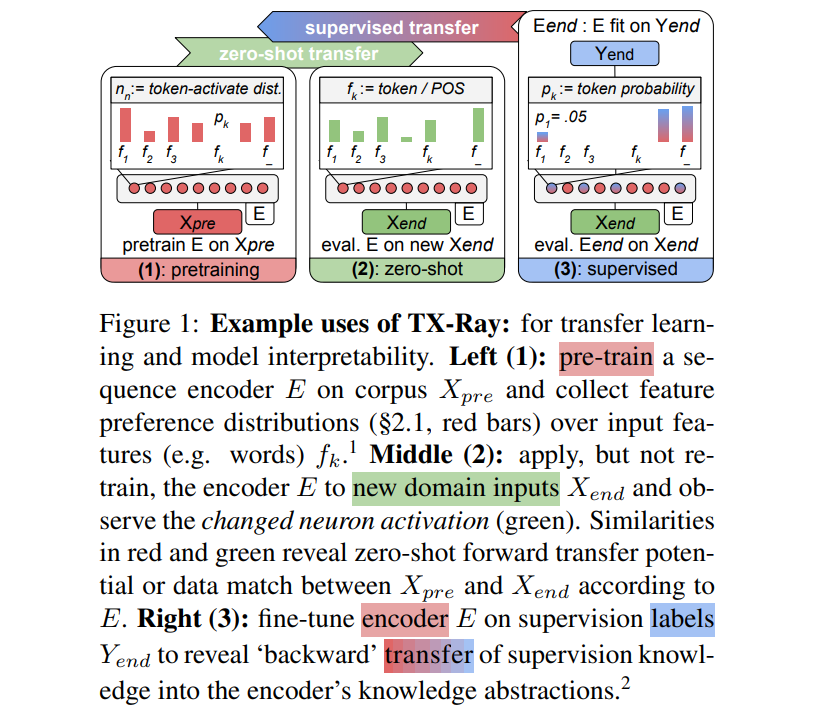
TX-Ray adapts the activation maximization idea of "visualizing a neuron's preferred inputs" to discrete inputs - NLP. With a neuron as an 'input preference distribution' we can measure neuron input-preference adaptation or transfer. This works for self- & supervised models alike.

We analyzed how neuron preferences are build and adapted during: (a) pretraining, (b) 'zero-shot' application to a new domain, and (c) by supervised fine-tuning.
(a) Confirms that: pretraining learns POS first, as @nsaphra showed, and that preferences converge like perplexity.
(a) Confirms that: pretraining learns POS first, as @nsaphra showed, and that preferences converge like perplexity.

(b) We then apply the pretrained language model to new domain texts absent retraining (zero-shot), telling us which neurons transfer - i.e. show similar preference on the new and pretrained corpora. Differing preference marks unknown inputs and 'unhelpful' pretrained neurons.

(c) When fine-tuning the pretrained LM to a supervised task, we see that: (i) many pretrained neurons are forgotten (deactivated) and that (ii) previously unpreferred, specialized neurons are added.
Pruning deactivated (i)-neurons raises generalization - i.e. XAI guides pruning.
Pruning deactivated (i)-neurons raises generalization - i.e. XAI guides pruning.

In summary, our method (named TX-Ray) allows one to explore (knowledge abstraction) transfer at neuron-level, which works for (self)-supervised models and even if annotated probing tasks are unavailable.
Implementation details and examples can be found at github.com/copenlu/tx-ray
Implementation details and examples can be found at github.com/copenlu/tx-ray
• • •
Missing some Tweet in this thread? You can try to
force a refresh



