
Ок, вчерашний speech был про мой путь 👟 в IT и отношение к нему 🙂
А сегодня поговорим про А/B тесты 📊
А/B тесты - это важная часть работы над продуктом.
Тест позволяют сравнить несколько версий продукта и определить, как изменения влияют на целевые показатели, конверсию📏📉
А сегодня поговорим про А/B тесты 📊
А/B тесты - это важная часть работы над продуктом.
Тест позволяют сравнить несколько версий продукта и определить, как изменения влияют на целевые показатели, конверсию📏📉
Это эффективный способ проверки гипотез.
A/B тесты помогают принимать решения, основываясь на собранных данных и цифрах, используя мощь статистической теории, в противовес принятию решений, основанных на интуиции, домыслах
A/B тесты помогают принимать решения, основываясь на собранных данных и цифрах, используя мощь статистической теории, в противовес принятию решений, основанных на интуиции, домыслах

Помогают поставить точку, в случае наличия нескольких мнений, когда каждый продвигает свою точку зрения.
Они помогают измерять реальное поведение аудитории вашего продукта.
Защищают от того, чтобы выкатить в прод ухудщающие изменения
Они помогают измерять реальное поведение аудитории вашего продукта.
Защищают от того, чтобы выкатить в прод ухудщающие изменения

Кроме того, могут тестироваться не только гипотезы по улучшающим изменениям, но и просто гипотезы важности того или иного аспекта для продукта.
Речь идет про ухудшающие эксперименты😱😁
Например, ухудшение performance и замер результатов через эксперимент - быстрый способ проверить насколько performance важен для вашей аудитории.
Еще ухудшающие эксперименты помогают отделить чувствительные метрики от не чувствительных
Например, ухудшение performance и замер результатов через эксперимент - быстрый способ проверить насколько performance важен для вашей аудитории.
Еще ухудшающие эксперименты помогают отделить чувствительные метрики от не чувствительных
На чем же строится достоверность выводов экспериментов ?
Во-первых одновременность замера версии с изменениями и без. Нужно как можно сильнее исключить сторонние факторы.
Во-первых одновременность замера версии с изменениями и без. Нужно как можно сильнее исключить сторонние факторы.
Ведь если делать замер версии с изменениями и без в разное время - то есть много дополнительных факторов, которые могут влиять - влияние дня недели, количество праздников и выходных, политические, экономические новости, курс валюты и т.д.
Когда мы делаем замер одновременно, мы расчитываем, что единственное изменение - это то, которое мы заложили в эксперимент.
Вторая причина, из-за которой мы можем рассчитывать на достоверность вывода, сделанного по итогу эксперимента - статистическая теория проверки гипотез.
В общем, статистика предоставляет нам следующий порядок рассуждений для проверки гипотез 👇:
В общем, статистика предоставляет нам следующий порядок рассуждений для проверки гипотез 👇:
1) Определяем нашу генеральную совокупность (ГС)
2) Выбираем контрольную группу (выборка А) без изменений и группу с изменениями (выборка В)
3) Выдвигаем нашу нулевую гипотезу (H0): "выборка А и В принадлежат одной ГС, между ними нет разницы".
2) Выбираем контрольную группу (выборка А) без изменений и группу с изменениями (выборка В)
3) Выдвигаем нашу нулевую гипотезу (H0): "выборка А и В принадлежат одной ГС, между ними нет разницы".
4) Альтернативная гипотеза (H1) состоит в том, что между выборками есть статистически значимые различия (т.е. они не принадлежат одной генеральной совокупности)
По умолчанию считаем достоверной гипотезу H0.
Применяем относительно H0 правило: "Отклоняем тихо, оставляем громко".
Т.е. нулевая гипотеза верна, пока нет достаточных оснований ее опровергнуть.
Применяем относительно H0 правило: "Отклоняем тихо, оставляем громко".
Т.е. нулевая гипотеза верна, пока нет достаточных оснований ее опровергнуть.
5) Выбираем порог отклонения нулевой гипотезы (p-value).
Часто применяют порог 0,05 или 0,1.
Читается это так - если p-value ниже 0,05 порога то можно с 95 %-ной вероятностью утверждать, что есть статистически значимые отличия между выборками.
Для 0.1 это соответственно 90%.
Часто применяют порог 0,05 или 0,1.
Читается это так - если p-value ниже 0,05 порога то можно с 95 %-ной вероятностью утверждать, что есть статистически значимые отличия между выборками.
Для 0.1 это соответственно 90%.
Где-нибудь в физике и других сферах, где важна супер уверенность, могут применять и более точный порог, например 0,01.
В тоже время бывают варианты и с меньшей степенью вероятности, например 0,2.
Иногда готовые системы аналитики и a/b тестирования предлагают такие.
В тоже время бывают варианты и с меньшей степенью вероятности, например 0,2.
Иногда готовые системы аналитики и a/b тестирования предлагают такие.
Более низкий порог дает большую уверенность, но требует и большую статистическую мощность. Более высокий порог - меньшую уверенность.
Статистическая мощность зависит от размера выборок и силе различий между ними
Статистическая мощность зависит от размера выборок и силе различий между ними
6) Проводим тест и проверяем статистическую значимость.
Разница называется статистически значимой, когда достигнутая разница между выборками маловероятна, если предположить, что обе выборки принадлежат одной генеральной совокупности (т.е. верна H0).
Разница называется статистически значимой, когда достигнутая разница между выборками маловероятна, если предположить, что обе выборки принадлежат одной генеральной совокупности (т.е. верна H0).
Для оценки маловероятности полученного отклонения, как раз и используется порог, который мы определили выше.
Можно либо напрямую рассчитать p-value, либо построить доверительный интервал.
Можно либо напрямую рассчитать p-value, либо построить доверительный интервал.
Доверительные интервалы - это то, что чаще всего можно увидеть в готовых сервисах для проведения экспериментов.
Взглянув на два интервала - достаточно понять включает ли в себя один интервал среднее значение другого. Если не включает - то можно отклонять нулевую гипотезу (H0)
Взглянув на два интервала - достаточно понять включает ли в себя один интервал среднее значение другого. Если не включает - то можно отклонять нулевую гипотезу (H0)
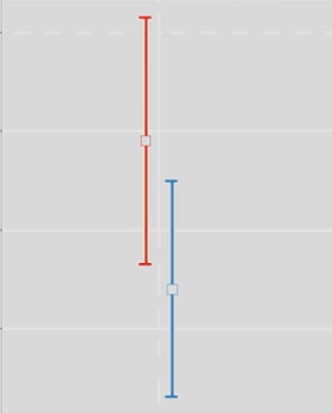
Но стоит отдельно отметить, что статистическая значимость говорит только о вероятности получения различий между выборками, при условии, что H0 верна, но ничего не говорит о величине разницы между выборками
Просто вероятность разницы
Насколько большая разница - не говорит ❕
Просто вероятность разницы
Насколько большая разница - не говорит ❕
Также стоит отметить, что приведенный алгоритм, не единственный шаблон проверки гипотез. Скорее просто хороший базис, чтобы начать понимать основы статистической проверки.
А так бывают еще разные виды экспериментов, поправки к данным, есть байесовский метод и т.д.
А так бывают еще разные виды экспериментов, поправки к данным, есть байесовский метод и т.д.
Что же делать, если мы не получили стат. значимость ?
А ничего - просто мы не смогли подтвердить H1
Большинство экспериментов не показывают результат, это нормально
Нужно настроиться на это заранее и не расстраиваться потом😀
А ничего - просто мы не смогли подтвердить H1
Большинство экспериментов не показывают результат, это нормально
Нужно настроиться на это заранее и не расстраиваться потом😀
Чтобы уменьшить количество таких результатов - можно более осмысленно подходить к выбору изменений для замера экспериментом.
Не тестировать все подряд, а только реальные гипотезы, которые как-то логически обоснованно могут повлиять на целевые метрики.
Не тестировать все подряд, а только реальные гипотезы, которые как-то логически обоснованно могут повлиять на целевые метрики.
Не проводить тест там, где маленькая выборка, изменение будет незначительно или тест может затянуться надолго
Получится ли набрать необходимую статистическую мощность - лучше считать заранее.
Напомню, что на нее влияет как размер выборки, так и чувствительность целевой метрики.
Получится ли набрать необходимую статистическую мощность - лучше считать заранее.
Напомню, что на нее влияет как размер выборки, так и чувствительность целевой метрики.
Ищите более чувствительную метрику и как можно точнее отбирайте сегмент.
Если эксперимент нацелен только на проверку поведения не зарегистрированных пользователей или только платящих, то и в сегмент отбирайте только их, а не всех подряд.
Если эксперимент нацелен только на проверку поведения не зарегистрированных пользователей или только платящих, то и в сегмент отбирайте только их, а не всех подряд.
Для нормального распределения значений можно сказать, что важно не только среднее значение выборки, но и размах значений. Выбирая более точно сегмент, мы уменьшаем размах
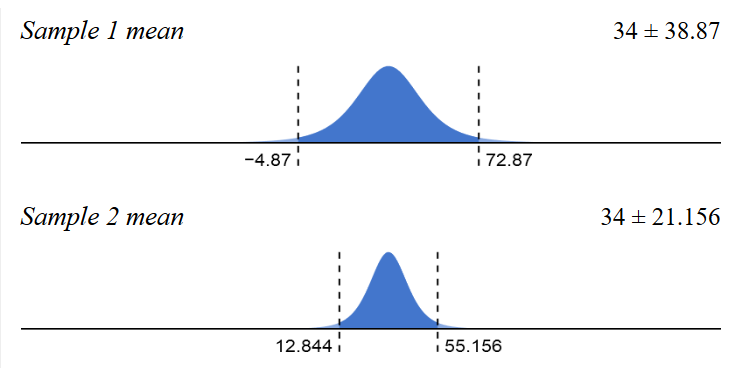
В целом нужно настроиться на то, что эксперименты требуют больше сил и времени, и увеличивают длительность релизного цикла фичи. Зато дают дополнительную уверенность
Может потребоваться провести разные статистические проверки - проверить на выбросы (сильно отклоняющиеся значения), проверить на характер распределения, выполнить некоторые поправки 😁
Проведение многофакторного эксперимента (сразу несколько изменений влияют на целевой показатель) или многовариантного (А/B/C/D/….) усложняет подсчет статистической значимости. По хорошему нужно проверять корреляции признаков и делать статистические поправки
Но хорошая новость в том, что есть готовые инструменты проведения экспериментов, которые сами все считают за нас 😁

Но при работе с ними, держите в голове идею про простой дизайн эксперимента (однофакторный А/В - одно изменение один вариант с изменением) - ибо эти инструменты вряд ли делают поправки на более сложный дизайн.
Обращайте внимание и на используемое значение p-value
Обращайте внимание и на используемое значение p-value
Готовые инструменты тестирования хороши, чтобы начать, особенно для экспериментов с простым дизайном. Но все равно иногда лучше включать здравый смысл и здоровое недоверие.
Часто если тест определяет победителя довольно быстро - то просто подождите еще) Он еще может поменяться
Часто если тест определяет победителя довольно быстро - то просто подождите еще) Он еще может поменяться
Для более точных рассчетов, большой уверенности и покрытия разных ситуаций - большие компании заводят in-house аналитику, систему сплита пользователей для эксперимента и доставки фиче тогглов.
Вообщем A/B тесты довольно хороший инструмент, если правильно им пользоваться)
До недавнего времени у нас их еще не было.
Поразмыслив с @tereznikof (наш продакт), решили что пора начинать что-то пробовать
До недавнего времени у нас их еще не было.
Поразмыслив с @tereznikof (наш продакт), решили что пора начинать что-то пробовать
Самое простое и очевидное - Firebase A/B Testing.
С него и начали.
К тому же Firebase одна из аналитик, которой мы пользуемся. Уже настроена куча ивентов, по которым можно мерять конверсию и User Property, по которым можно сегментировать пользователей.
С него и начали.
К тому же Firebase одна из аналитик, которой мы пользуемся. Уже настроена куча ивентов, по которым можно мерять конверсию и User Property, по которым можно сегментировать пользователей.

