
1/ First community meeting for Dagster users going through our biggest release yet, 0.8.0. Fantastic meeting with really great questions at end. This was for existing users so we jumped right into advanced stuff.
2/ Will be posting in detail about the release next week. But there are huge internal changes in addition to user-facing features. A little preview of some of the interesting bits below.
3/ Core architecture changes: Our system processes and tools are now totally separate from user code. They no longer share python deps and can even be on different python versions. You can also organize it so that teams can keep their deps/pipelines separate from each other.
4/ Dagit (frontend) revamp: Totally new organization for our frontend that is more "pipeline-centric" You have a landing page for your pipeline that in one screen that displays its shape, its schedule, its run history, and the assets it has produced. 

5/ We have a new capability called the Asset Manager, that allows you to link your computations and the assets that they produce. We believe that this is novel system of record for metadata in data applications, and we will invest a ton in this area going forward.
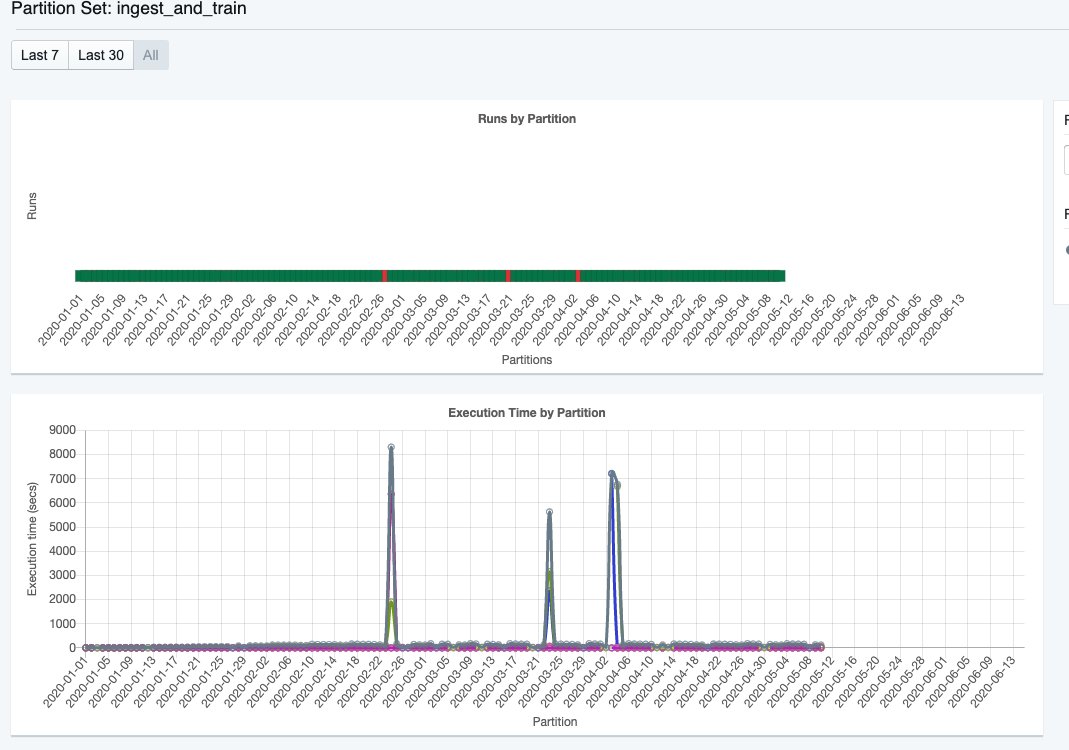
6/ New charting/graphing capabilities to view historical execution times and asset properties.
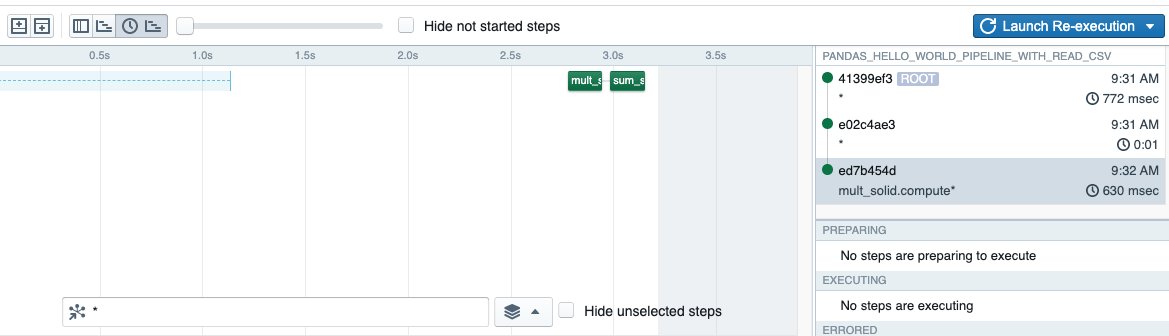
7/ We also have implemented lineage between runs (e.g. when you re-execute from a failure there are two runs linked together) and display those runs together.
8/ We have also improved our pyspark support to abstract away infrastructure concerns. You can write pyspark code and, without changing it, execute it on your laptop, EMR, and now -- with a community-provided integration -- Databricks. Really excited about this direciton.
9/ "Dagster-Native" Orchestration Cluster: We have a supported orchestration cluster that allows one to manage compute on k8s and using celery as a control plane.
10/ Airflow auto-ingestion: You can now take a set of Airflow DAGs and automatically ingest them into Dagster, using Dagster as an execution environment.
11/ You can read full release notes here: github.com/dagster-io/dag…. There's a lot of stuff in there.
12/ We'll be posting a more thorough blog post next week about these features and the direction of the project.
13/ Thanks to team for all the amazing work for to all the community members out there. The attendance at the meeting exceeded our expectations and the questions were great!
• • •
Missing some Tweet in this thread? You can try to
force a refresh




