
A vital skill for a researcher is to be able to take a step back when you have an idea for solving an important problem that no one seems to have worked on, and figure out if it's because you know something that others don't or because they all know something that you don't.
1. Not all knowledge in a community is recorded formally. Networking fills the gap. (But the need for networking contributes to systemic biases and we must work against them.)
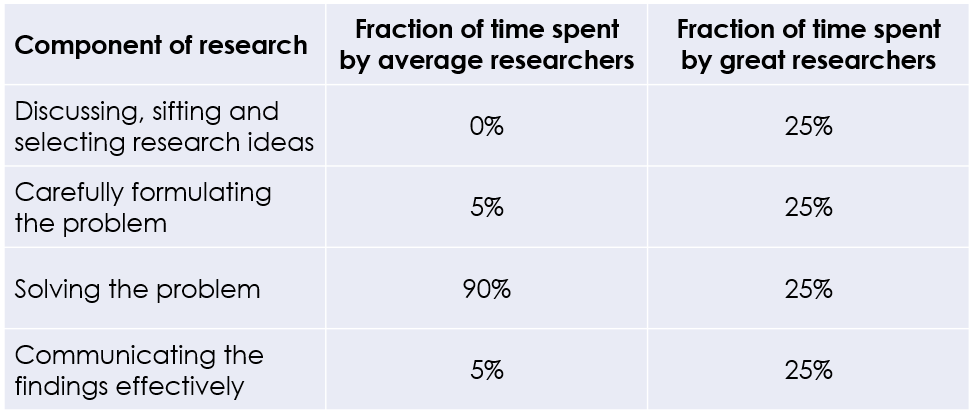
2. Spend time earlier in the research pipeline and be prepared to drop ideas.
2. Spend time earlier in the research pipeline and be prepared to drop ideas.
https://twitter.com/malekz4deh/status/1285643631261560833
3. Work with a mentor. Over time, people build up a repository of ideas and can tell which ones are truly new. As an advisor, much of what I offer is helping my mentees filter and prioritize their ideas.
4. Try many things, because any single idea is always risky.
4. Try many things, because any single idea is always risky.
5. Just because an idea has been tried many times doesn't mean it isn't worth another go. Ideas may finally succeed because the *environment* has changed — new tools and techniques may be available, or the community's biases may have changed to be more accepting of the idea.
Finally, let's work on sharing our informal knowledge more widely—such as by writing up negative results—and incentivizing people to do so. That would make much of the advice in this thread redundant (like the importance of networking), which would be a good thing!
• • •
Missing some Tweet in this thread? You can try to
force a refresh










{kind=link}