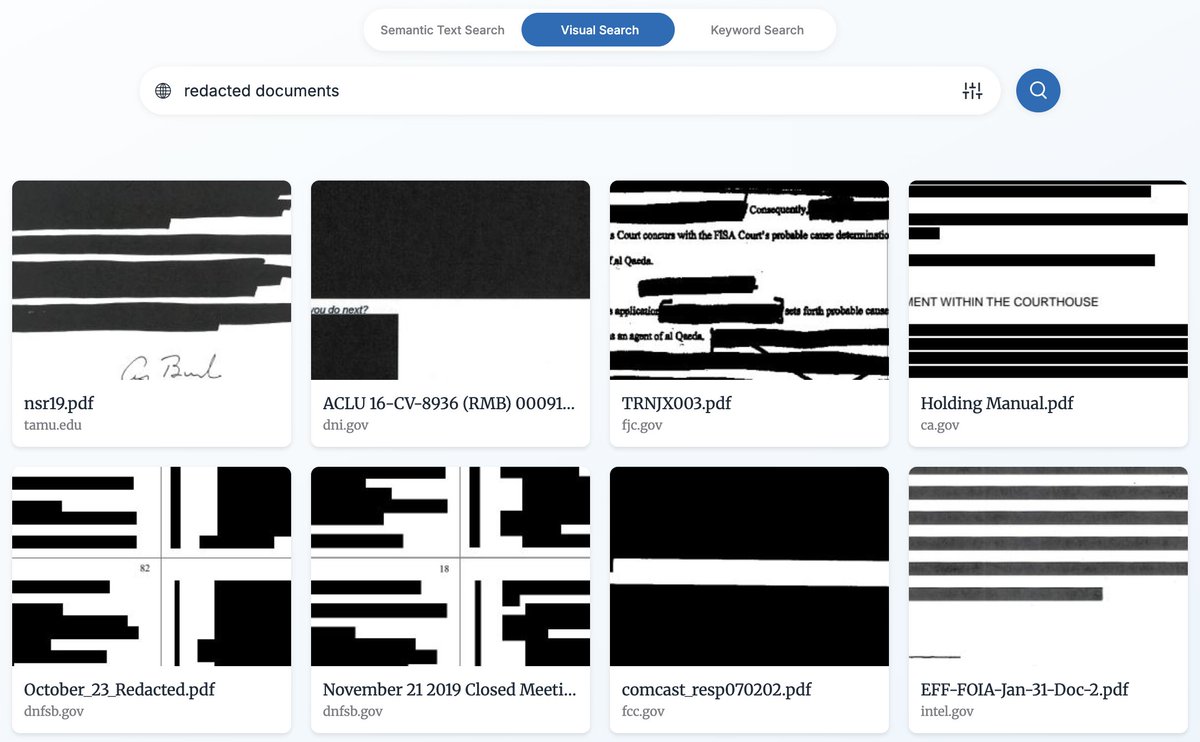
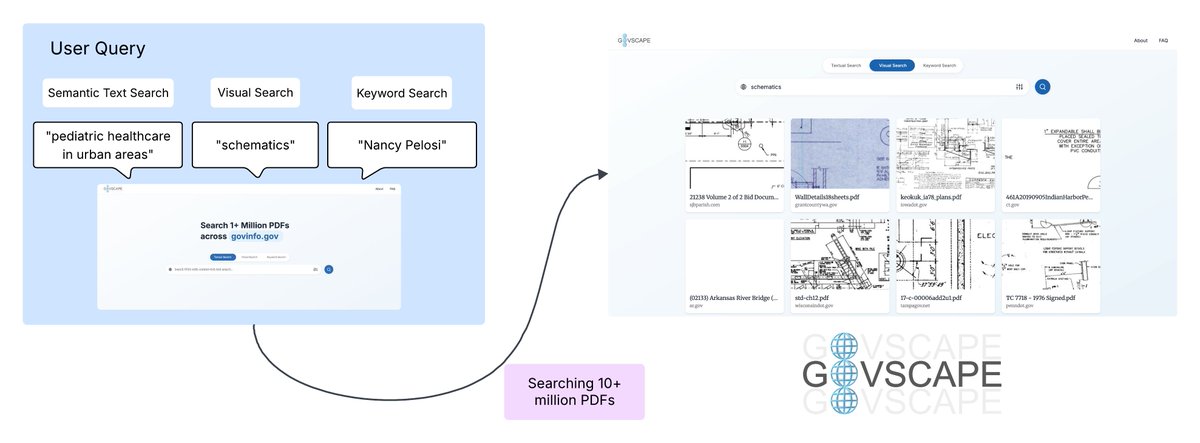
1/ With @LC_Labs, #NDNP, and @dsweld, I’m excited to share the Newspaper Navigator search app: train your own AI navigators to search over 1.5 million historic newspaper photos by visual similarity! (desktop viewing recommended) #ChronAm
news-navigator.labs.loc.gov/search
news-navigator.labs.loc.gov/search

2/ For the first phase of my @librarycongress Innovator in Residence project, I created the #NewspaperNavigator dataset: extracted visual content from 16+ million newspaper pages in #ChronAm. This search app provides new ways of searching the dataset.
news-navigator.labs.loc.gov
news-navigator.labs.loc.gov
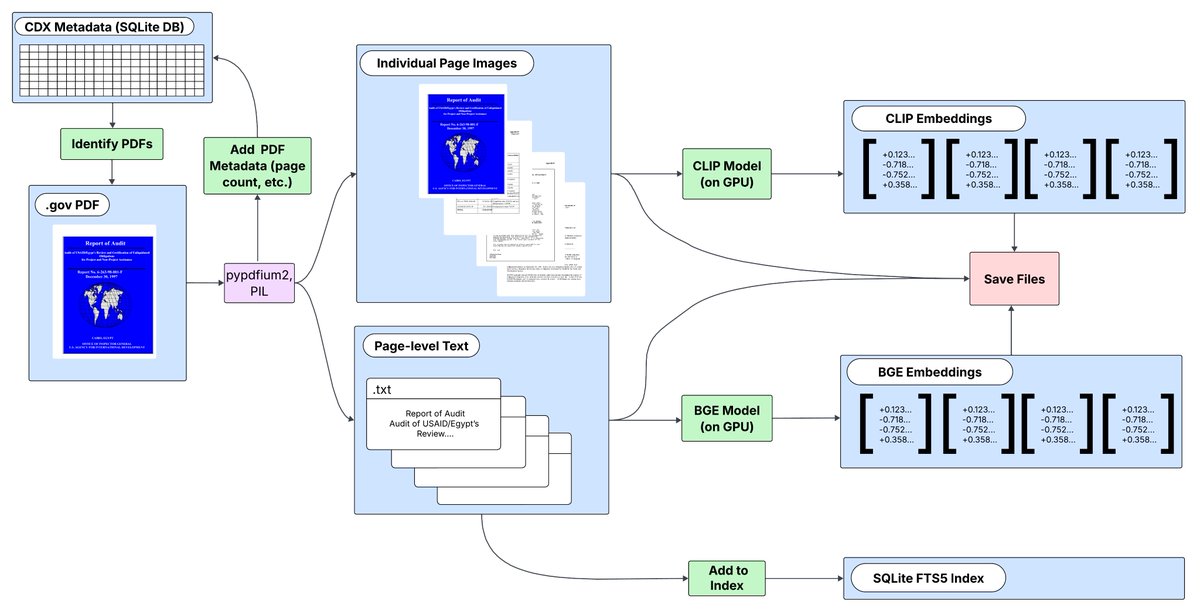
3/ In addition to supporting keyword search, the Newspaper Navigator app leverages image embeddings to support on-the-fly training and re-training of AI navigators in just a couple of seconds. Here is an example of training an AI navigator to retrieve photos of sailboats:

4/ As with the Newspaper Navigator dataset and #ChronAm, the full search app is in the public domain, from the photos to the code. You can find all code for Newspaper Navigator at this GitHub repo: github.com/LibraryOfCongr…
5/ Because machine learning has a fraught history with perpetuating marginalization, I wrote a data archaeology investigating the ways in which machine learning mediates our interactions with the visual content in the Newspaper Navigator dataset and app.
hcommons.org/deposits/item/…
hcommons.org/deposits/item/…
6/ In the data archaeology, I study the digitization journeys of 4 reproductions of the same photo of W.E.B. Du Bois, as found in the pages of 3 Black newspapers in #ChronAm.

7/ This afternoon, I’m presenting with the amazing scholars @SarahHSalter @jimcasey1 and @jgob at the public #NDNP panel discussion “Seeing Editors: Metadata, Machine Learning, and the Shapes of Social Justice"! @NEH_PresAccess
neh.gov/blog/seeing-ed…
neh.gov/blog/seeing-ed…
8/ If you’re interested in learning more about #NewspaperNavigator, #ChronAm, or @LC_Labs, here are some additional resources:
NN press release: go.usa.gov/xG58n
NN dataset paper: arxiv.org/abs/2005.01583
Chronicling America: chroniclingamerica.loc.gov
@LC_Labs
NN press release: go.usa.gov/xG58n
NN dataset paper: arxiv.org/abs/2005.01583
Chronicling America: chroniclingamerica.loc.gov
@LC_Labs
9/ I want to thank @LC_Labs, #NDNP, @librarycongress, @NEH_PresAccess, and my Ph.D. advisor @dsweld @uwcse for collaborating with me on #NewspaperNavigator and making the project possible!
10/ Lastly, please feel free to reach out to me on Twitter or by email with any questions about #NewspaperNavigator!
• • •
Missing some Tweet in this thread? You can try to
force a refresh