THREAD: How does the scheduler work in Kubernetes?
The scheduler is in charge of deciding where your pods are deployed in the cluster.
It might sound like an easy job, but it's rather complicated!
Let's dive into it.
The scheduler is in charge of deciding where your pods are deployed in the cluster.
It might sound like an easy job, but it's rather complicated!
Let's dive into it.

1/8
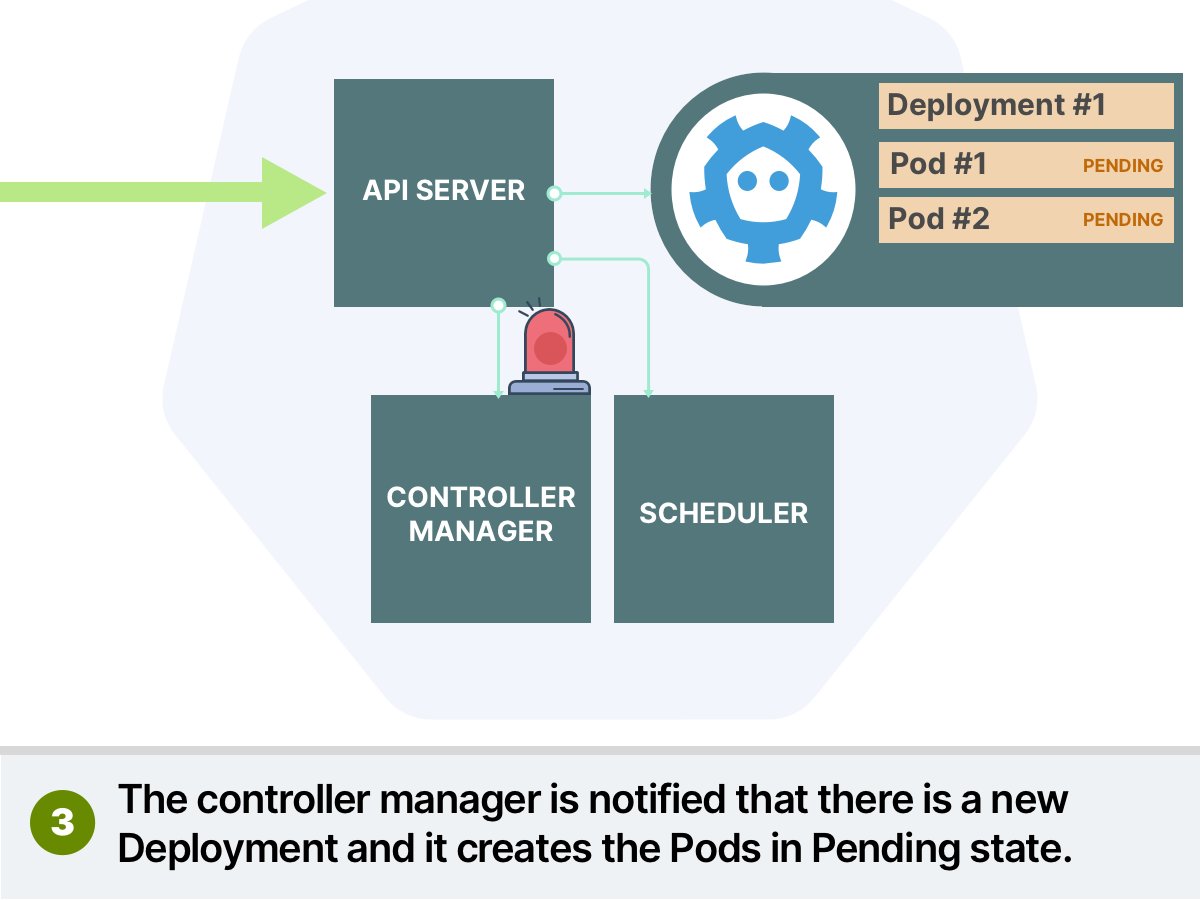
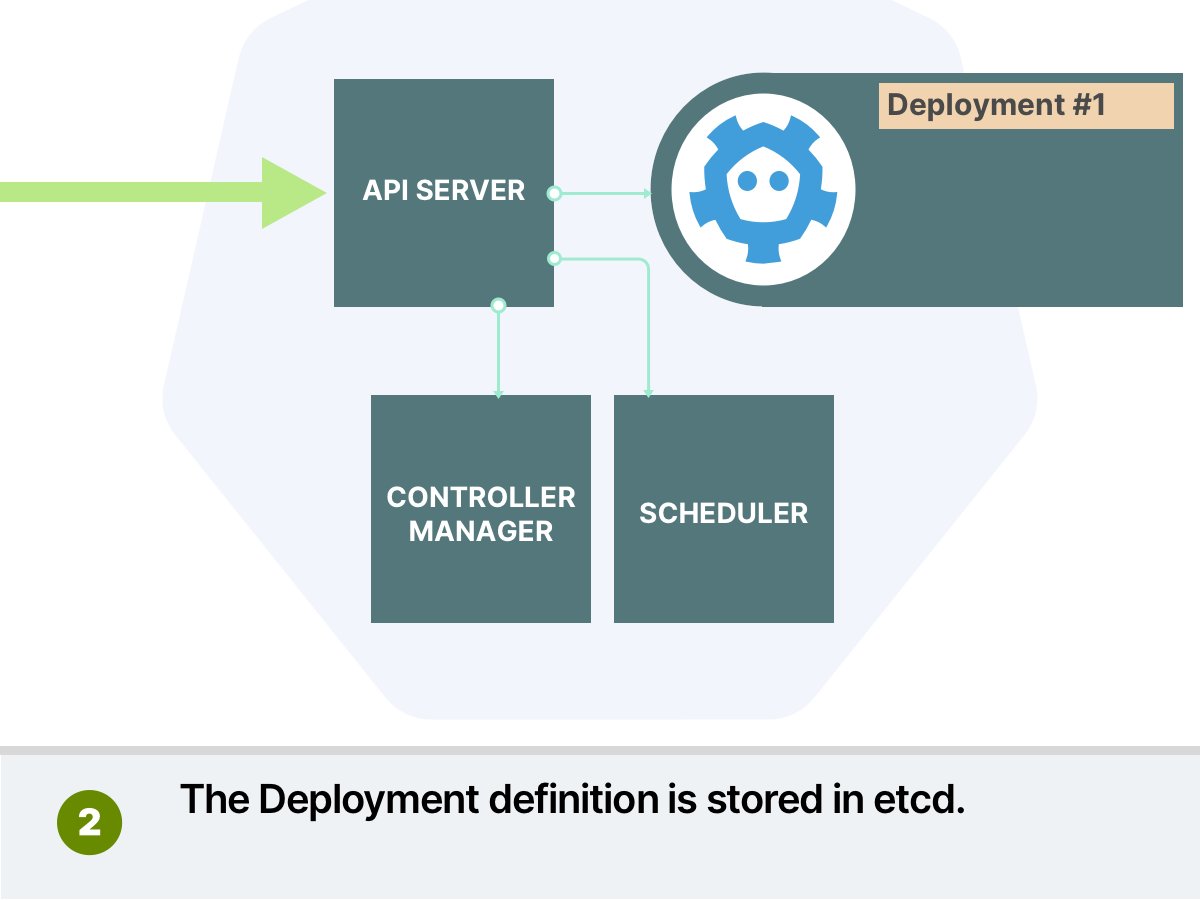
Every time a Pod is created, it also added to the Scheduler queue.
The scheduler process Pods 1 by 1 through two phases:
1. Scheduling phase (what node should I pick?)
2. Binding phase (let's write to the database that this pod belongs to that node)
Every time a Pod is created, it also added to the Scheduler queue.
The scheduler process Pods 1 by 1 through two phases:
1. Scheduling phase (what node should I pick?)
2. Binding phase (let's write to the database that this pod belongs to that node)


2/8
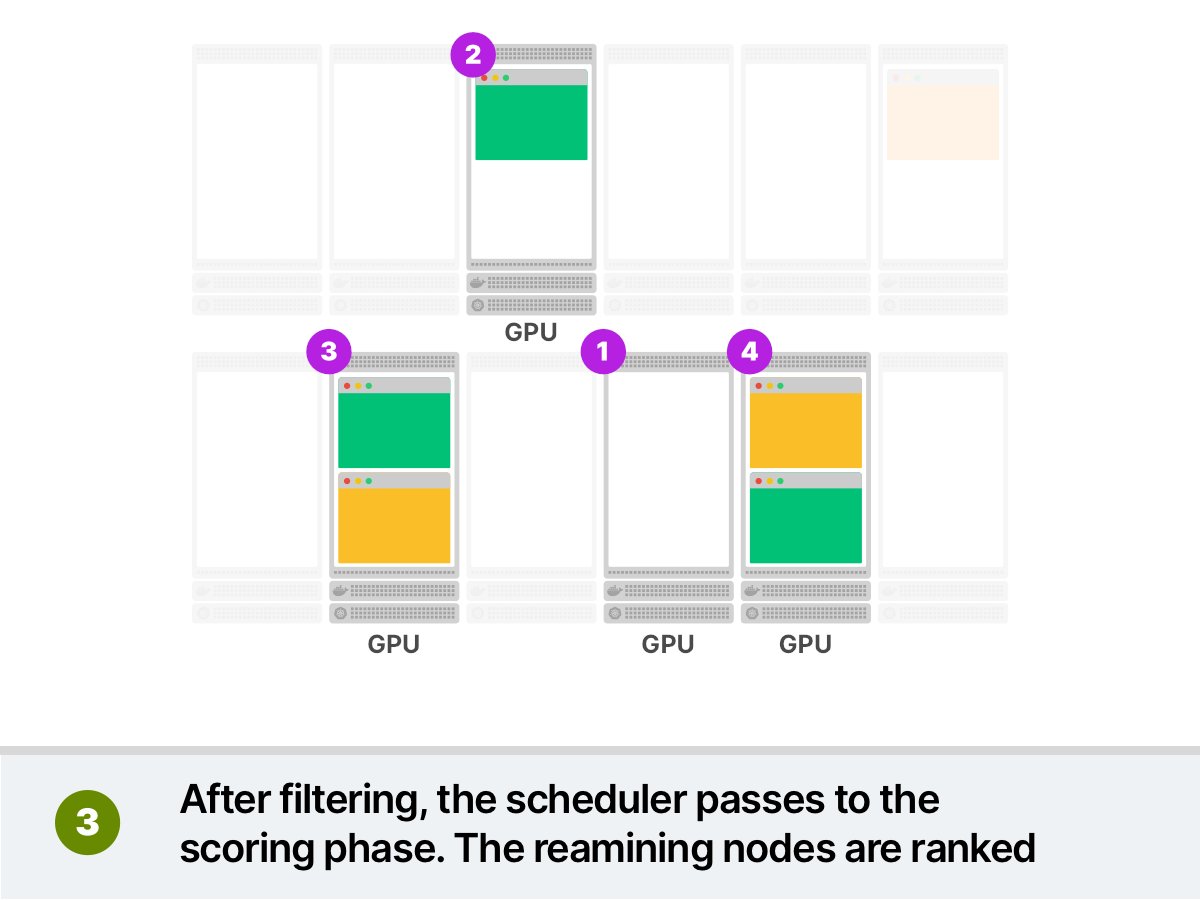
The Scheduler phase is divided into two parts. The Scheduler:
1. Filters relevant nodes (using a list of functions call predicates)
2. Ranks the remaining nodes (using a list of functions called priorities)
Let's make an example.
The Scheduler phase is divided into two parts. The Scheduler:
1. Filters relevant nodes (using a list of functions call predicates)
2. Ranks the remaining nodes (using a list of functions called priorities)
Let's make an example.
3/8
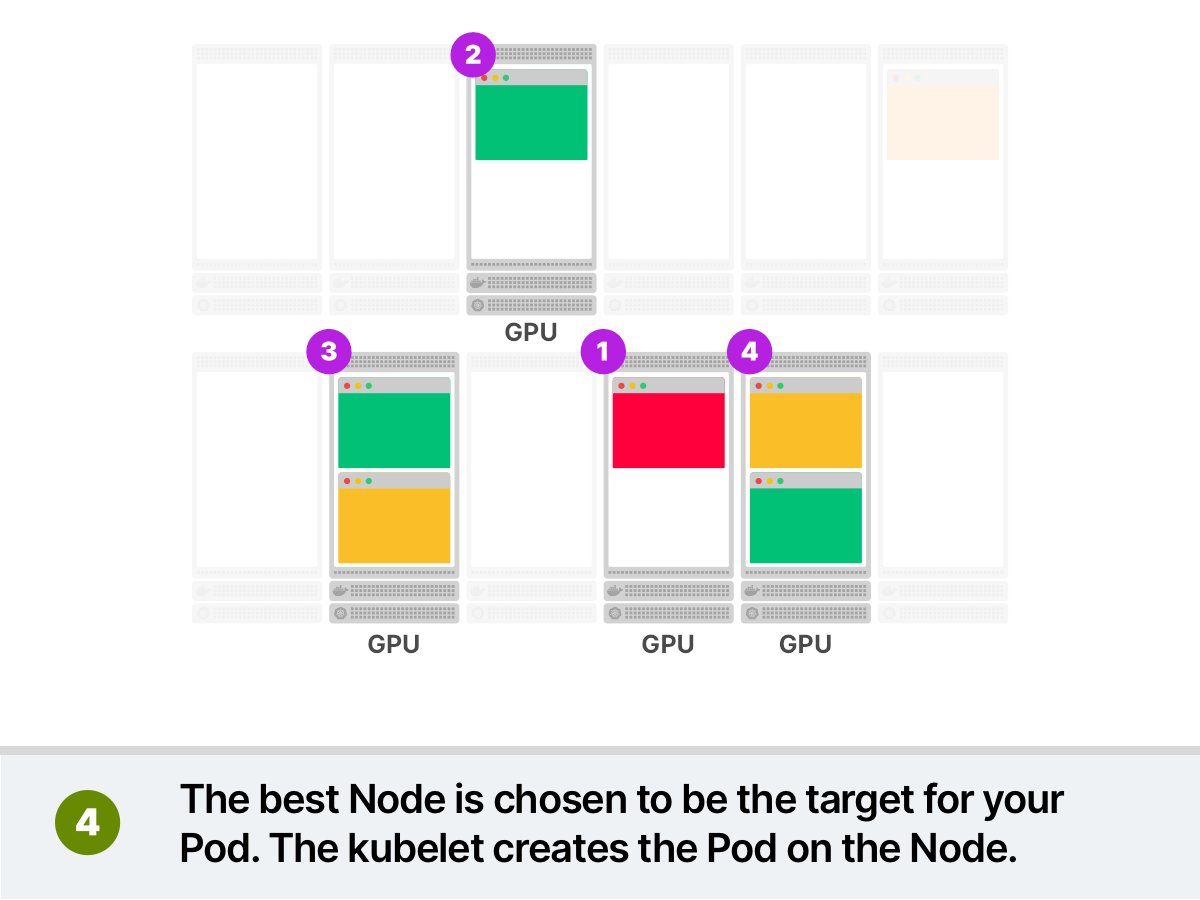
You want to deploy a Pod that requires some GPU. You submit the pod to the cluster and:
1. The scheduler filters all Nodes that don't have GPUs
2. The scheduler ranks the remaining nodes and picks the least utilised node
3. The pod is scheduled on the node
You want to deploy a Pod that requires some GPU. You submit the pod to the cluster and:
1. The scheduler filters all Nodes that don't have GPUs
2. The scheduler ranks the remaining nodes and picks the least utilised node
3. The pod is scheduled on the node


4/8
At this moment, the filtering phase has 13 predicates.
That's 13 functions to decide whatever the scheduler should discard the node as a possible target from the pod.
Even the scoring phase has 13 priorities.
Those are 13 functions to decide how to score and rank nodes.
At this moment, the filtering phase has 13 predicates.
That's 13 functions to decide whatever the scheduler should discard the node as a possible target from the pod.
Even the scoring phase has 13 priorities.
Those are 13 functions to decide how to score and rank nodes.


5/8
How can you influence the scheduler's decisions?
- nodeSelector
- Node affinity
- Pod affinity/anti-affinity
- Taints and toleration
And what if you want to customise the scheduler?
How can you influence the scheduler's decisions?
- nodeSelector
- Node affinity
- Pod affinity/anti-affinity
- Taints and toleration
And what if you want to customise the scheduler?
6/8
You can write your plugins for the scheduler. You can customise any block in the Scheduling phase.
The binding phase doesn't expose any public API, though.
You can write your plugins for the scheduler. You can customise any block in the Scheduling phase.
The binding phase doesn't expose any public API, though.

7/8
You can learn more about the scheduler here:
- Kubernetes scheduler kubernetes.io/docs/concepts/…
- Scheduling policies kubernetes.io/docs/reference…
- Scheduling framework kubernetes.io/docs/concepts/…
You can learn more about the scheduler here:
- Kubernetes scheduler kubernetes.io/docs/concepts/…
- Scheduling policies kubernetes.io/docs/reference…
- Scheduling framework kubernetes.io/docs/concepts/…
8/8
Did you like this thread?
You might enjoy the previous threads too! You can find all of them here:
What would you like to see next? Please reply and let me know!
Did you like this thread?
You might enjoy the previous threads too! You can find all of them here:
https://twitter.com/danielepolencic/status/1298543151901155330
What would you like to see next? Please reply and let me know!
• • •
Missing some Tweet in this thread? You can try to
force a refresh