
The Puzzle of Danish: a thread on taking linguistic diversity seriously to highlight the flexibility of human cognition.
1/n
1/n

TLDR: Danish has an unusual speech opacity (consonant reduction). Danish native speakers rely more strongly on context and top-down inference. They also create more redundant speech and repeat each other more: a richer context for top-down speech processing. 2/n
The Puzzle of Danish is a project funded by the Danish council for independent research involving (besides me) @MH_Christiansen, @kristian_tylen, Dorthe Bleses, Anders Højen, Christer Johansson, @ChrisDideriksen, @fabio_trecca and @byureka . 3/n

We observe huge variations across languages e.g. in number of phonemes, word and sentence structures, prosody (review: cambridge.org/core/services/…) 4/n
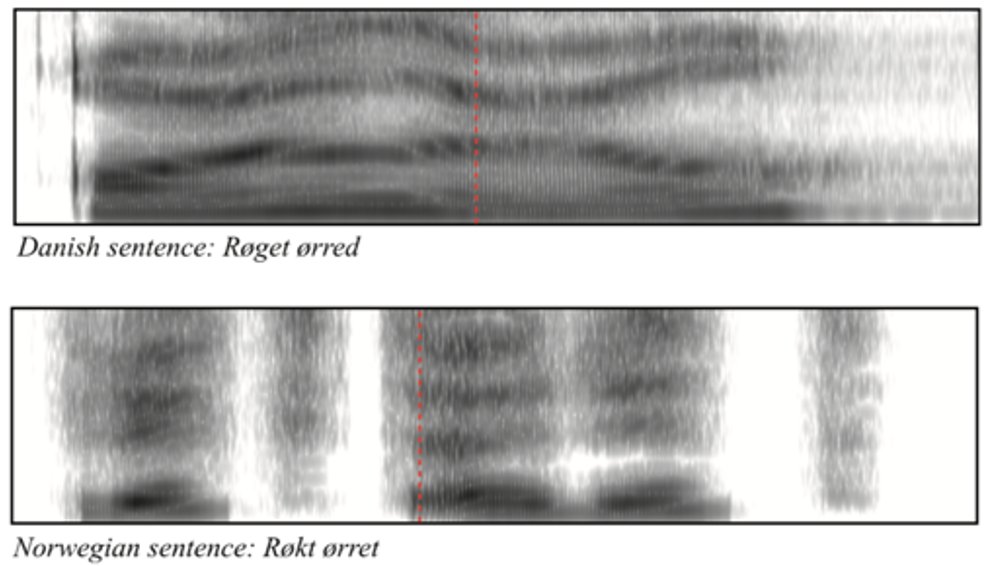
Danish in particular has a peculiar sound structure as the spectrogram below illustrates.
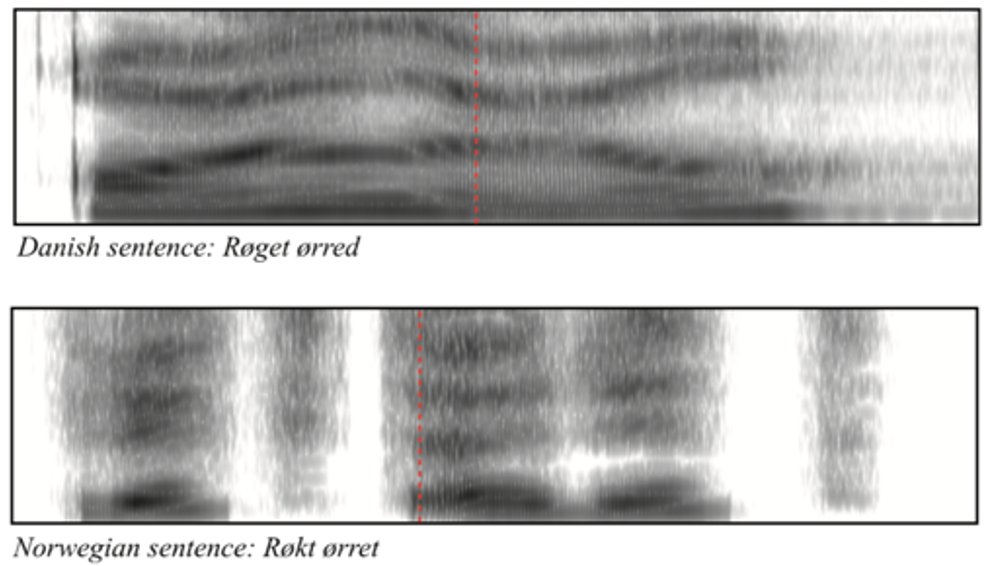
This is due to 1) a profusion of vowels: 16 full vowels and up to 40 phonemically distinctive vocalic sounds
2) the progressive reduction in pronunciation of consonants, which leads to many jokes especially from second language learners

This Danish peculiarities (aka the grey wall of Danish) makes it arguably harder to process than otherwise comparable languages such as Norwegian Bokmål and Swedish.

In particular our Danish Opacity Hypothesis (DOH!) argues that Danish could be relatively harder to segment in structures like utterances, words, morphemes and syllables, the basic bricks we need to learn and understand a language.
Previous literature has highlighted that Danish children do present delays in language acquisition:
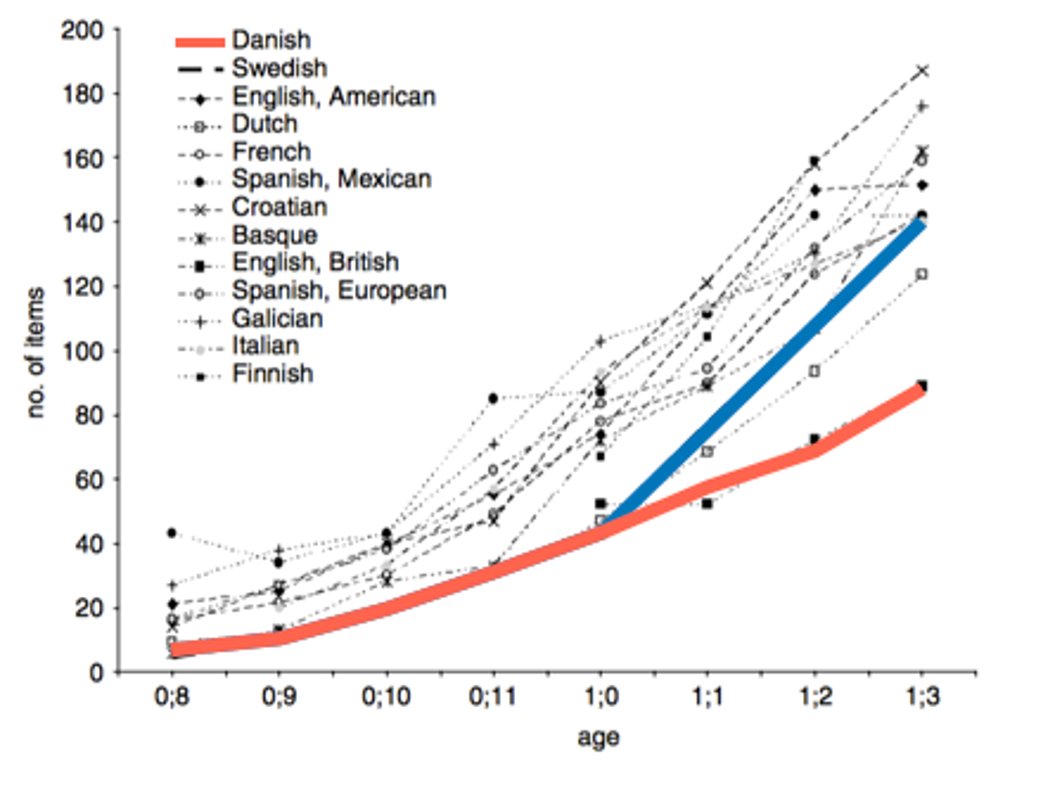
At 15 months, Danish children possess a median vocabulary of 90 words, compared to 140 for Norwegian kids and 150 for Swedish ones (pubmed.ncbi.nlm.nih.gov/18588717/)
At 15 months, Danish children possess a median vocabulary of 90 words, compared to 140 for Norwegian kids and 150 for Swedish ones (pubmed.ncbi.nlm.nih.gov/18588717/)
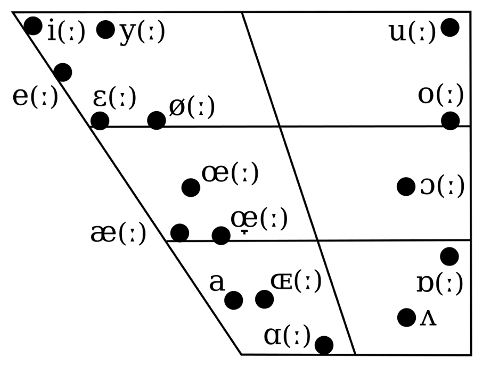
Up to 8 years of age, Danish children have more difficulties with inflectional morphology, e.g. declining regular and irregular verbs in simple past (often characterised by a -de ending, largely reduced in pronunciation). (doi.org/10.1080/016909…)

These delays have been more directly associated to the phonetic reduction typical of Danish in clever studies by Fabio Trecca, showing that sentences with pronounced phonetic reduction lead to lower and slower referent identification and lower lexical learning.
However, adult native speakers of Danish do NOT seem to have issues with Danish (notwithstanding the opinion of Norwegians: )
We build on the Danish Opacity Hypothesis (DOH!) to further argue that this might be due to compensatory cognitive strategies: learning and understanding Danish does not simply take longer (or more exposure), it requires different cognitive strategies.
The speech signal does not get clearer as Danish native speakers grow up, so we hypothesized that they learn to put increased focus on additional sources of information (e.g. context)
This is where the Puzzle of Danish project comes in. We investigate in native Danish and Norwegian (Bokmål) speakers how much context matters in categorical perception (@byureka), sentence processing (@fabio_trecca ) and conversational interactions (@ChrisDideriksen)
Context in categorical context has its own thread:
https://twitter.com/fusaroli/status/1290975959106105349?s=20and you can find preprint, data and code at: psyarxiv.com/jpbtw/
The conclusion is that Danish native speakers are equally affected by near and distant sentential context in their disambiguation of words and phonemes, while Norwegians just won't wait for distant contexts and will make their decisions earlier.
Forcing them to wait makes them more similar to Danish native speakers (Make Norwegians Danes Again!)
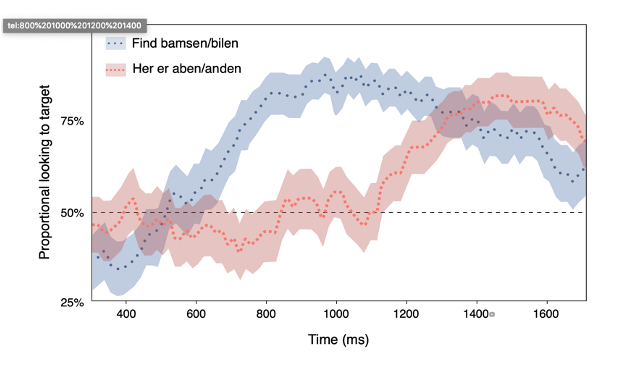
In the second study we use a sentence matching picture, where participants hear a story and have to associate a target sentence with one of four drawings (as in the picture below).

We manipulate the SEMANTIC context (pre-existing knowledge of world): a semantically incongruent sentence would be "the mailman bit the dog", a congruent one "the dog bit the mailman".
We manipulate the PRAGMATIC context (cotextual information): a pragmatically incongruent story would lead with the elderly lady being a biter, but the target sentence having the mailman biting.
We measures errors in matching due to incongruent semantic and pragmatic contexts, but we also measure the attraction towards incorrect matchings, although the response is correct, via mouse and eye-tracking.

Context affects the error mades, but does not credible differentially affect Danish and Norwegian native speakers

However, contextual information does attract Danish native speakers to the wrong drawings more than it does Norwegian ones. Danes look more at the pragmatically/semantically plausible but incorrect drawings

Can we make Norwegians Danes again? It turns out that if we make parsing the speech stimuli harder by introducing background noise, Norwegians look like Danes do (or even more so)
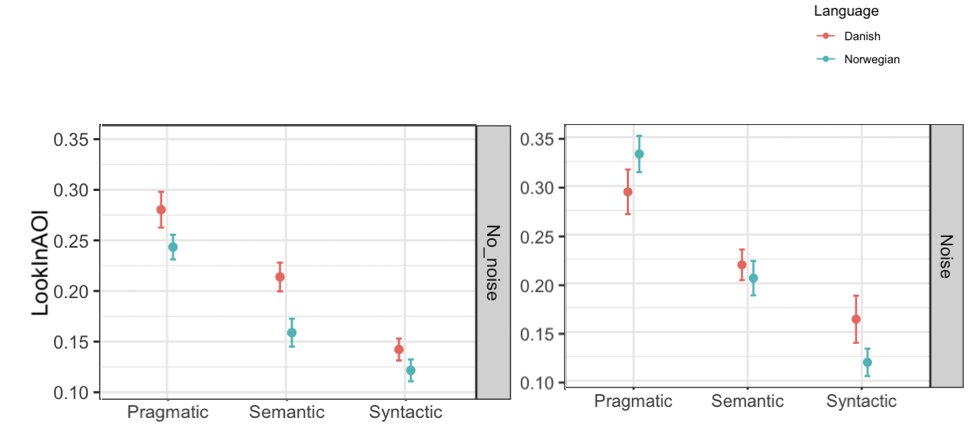
Quick overview: 1) Danish speakers weight context more than Norwegians at the word and sentence disambiguation level. 2) This is grounded in different preferred cognitive strategies, more than hard-coded
Indeed, Norwegian speakers can be made Danes again
by making them wait before reacting and blasting continuous noise against them.
by making them wait before reacting and blasting continuous noise against them.
However, this depicts language processing as an individual process performed in isolation on pre-existing speech signals. Instead, we learn and process language as part of rich interactions. How does the Danish Opacity Hypothesis (DOH!) play out here?
In the third study (involving also the excellent @DingemanseMark) we elicited various types of conversations from Danish and Norwegian native speakers (preprint coming soon, so this is just a sneak peek).

Our hypothesis was that Danes would use more backchannels (signaling monitoring mutual understanding via "hmms" and "okay"), conversational repairs (checking for and repairing misunderstanding: "what do you mean?") and
linguistic alignment (reusing each other's words, syntactic structures and semantics aka word embeddings, thus ensuring higher redundancy and easier top-down processing). This would be especially true for conversations where precision is important (Task Oriented Conversations)
No difference in backchannels

Fewer conversational repairs

Higher lexical, syntactic and semantic alignment all over the place, but especially in Task Oriented Conversations

We interpret this as a careful (but probably implicit) construction of redundancy, which makes repairs less relevant (as fewer misunderstandings are likely to happen).
Take home message: Danish is peculiar, and this affects cognitive processing, making it less signal- and more context-dependent. Crucially, processing and production are interrelated: production has adapted to make the context more redundant (both within and btw interlocutors)
These are not radical changes in the cognitive system, but different preferred strategies, which can flexibly be changed given the contextual demands.
This opens up a lot of questions: how general (i.e. beyond linguistic processing) are these strategies? Is infant directed speech in Danish and Norwegian also showing different strategies? How far can we identify similar dimensions to test across a broader range of languages?
Finally, this is basic research, but it has already produced concrete outputs: we contributed sorely missed conversational transcripts and speech recordings to Danish NLP projects (e.g. Gigaword DK: gigaword.dk) and
we are updating the ALIGN package (dx.doi.org/10.1037/met000…) to automatically deal with linguistic alignment in languages beyond English, and
we are working w @andreaskirkedal to highlight how even these noise-free clear conversations pose fundamental challenges to state-of-the-art automated speech recognition (aka the problem is not solved!)
The whole project was run in an open cumulative science spirit, releasing data and scripts, using former literature to generate informed priors (critically tested against weakly informative ones), and relying on the always excellent #brms and @mcmc_stan for Bayesian analyses.
• • •
Missing some Tweet in this thread? You can try to
force a refresh













