
Get ready. This is going to be an important thread. Election season will be over soon and hopefully more people will devote some attention to this...
I'm going to walk through a timeline of SARS2-related virus data published in the months after the outbreak. (1/30)
I'm going to walk through a timeline of SARS2-related virus data published in the months after the outbreak. (1/30)
Since the outbreak in late 2019, events have been unfolding at such a fast pace that it is difficult to keep track of what happened and in what order.
I use visualizations of the timeline to follow key events relating to the search for the animal host of SARS2. (2/30)
I use visualizations of the timeline to follow key events relating to the search for the animal host of SARS2. (2/30)

Even today, I still hear people saying that SARS-CoV-2 came from pangolins and a Seafood market in Wuhan. I hope this analysis will help to clear things up. It will refresh us on significant early pandemic events and major publications discussing the origins of the virus (3/30).
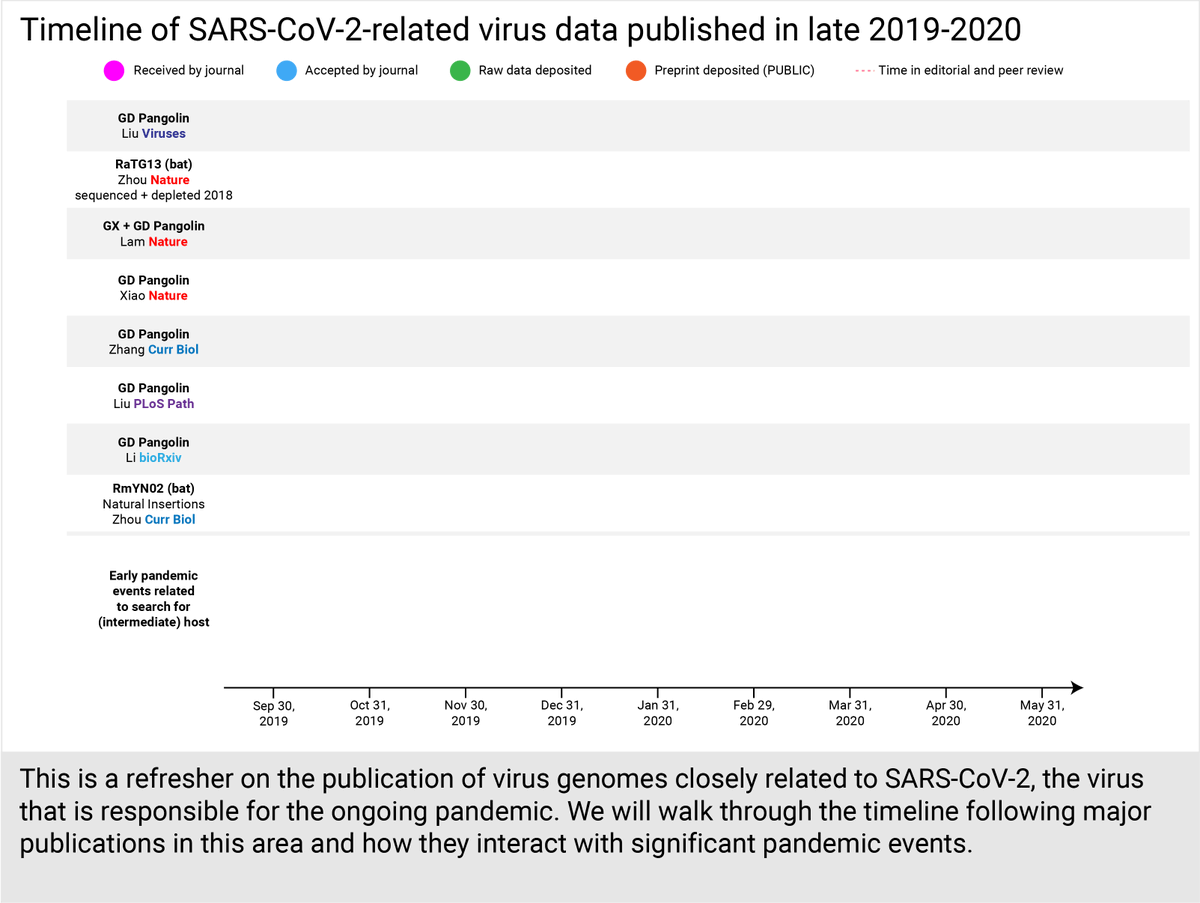
Notably, many of the key papers describing original data on bat or pangolin coronaviruses closely related to SARS-CoV-2 share co-authors.
The first of these was Liu et al. Viruses (top row). It was reviewed in 3 weeks, published October 24, 2019. (4/30)
The first of these was Liu et al. Viruses (top row). It was reviewed in 3 weeks, published October 24, 2019. (4/30)
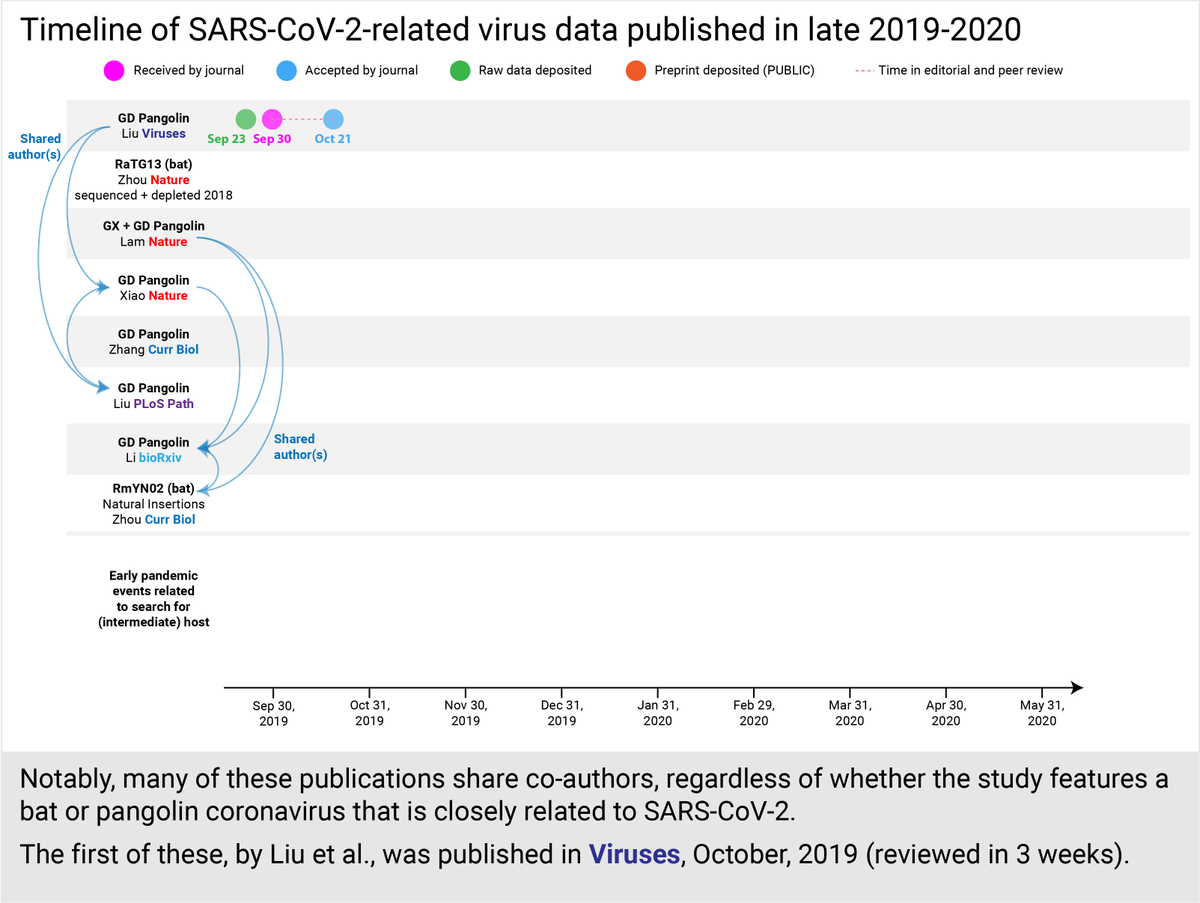
The first COVID cases were detected in mid-December 2019. Many were linked to the Huanan Seafood market, which was completely sanitized and shut down by Jan 1.
The Chinese lab that first published SARS2's genome was closed for rectification that same day (Jan 12).
(5/30)
The Chinese lab that first published SARS2's genome was closed for rectification that same day (Jan 12).
(5/30)
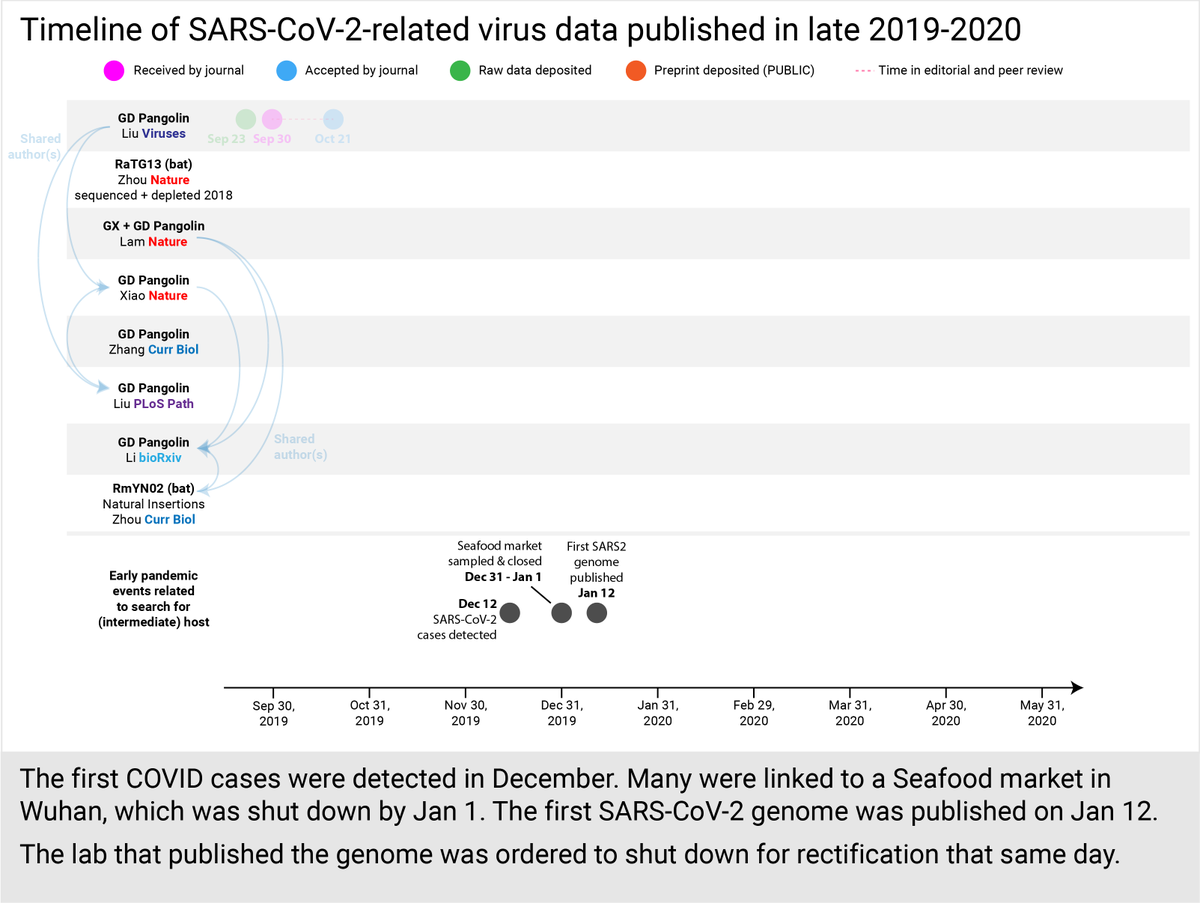
Jan 20, China finally confirms human-to-human transmission. Same day, WIV's paper is sent to @nature describing an unattributed bat virus 96% identical to SARS2.
Jan 22, China says the virus likely came from animals sold at the Seafood market.
Jan 23, WIV paper on bioRxiv.
Jan 22, China says the virus likely came from animals sold at the Seafood market.
Jan 23, WIV paper on bioRxiv.
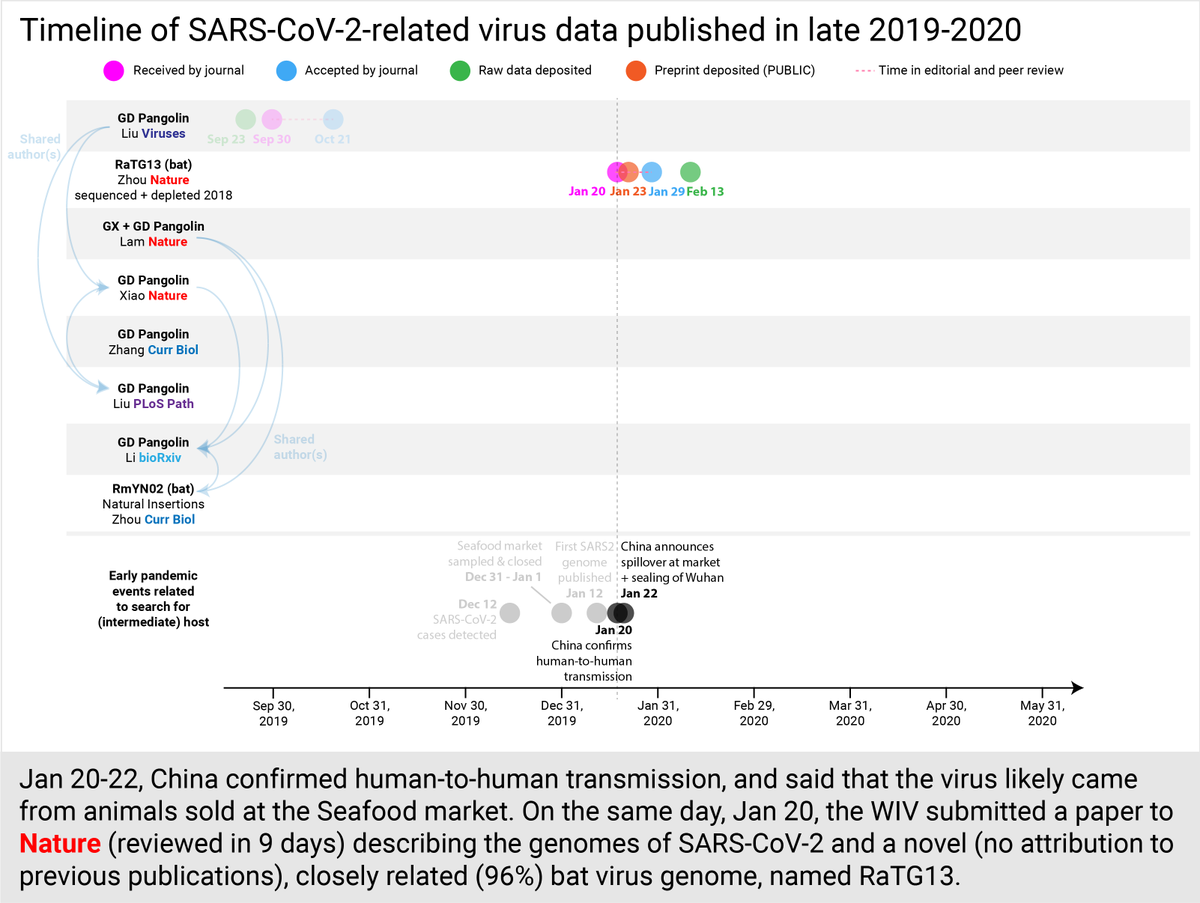
At the same time, on Jan 22, Liu et al. re-uploaded their September 2019 pangolin virus data onto @NCBI Why? Are the two datasets identical?
Jan 31, in a non-public meeting, China informs @OIEAnimalHealth that none of the market animal samples were positive for the virus. (7/30)
Jan 31, in a non-public meeting, China informs @OIEAnimalHealth that none of the market animal samples were positive for the virus. (7/30)

This is where it gets even more interesting.
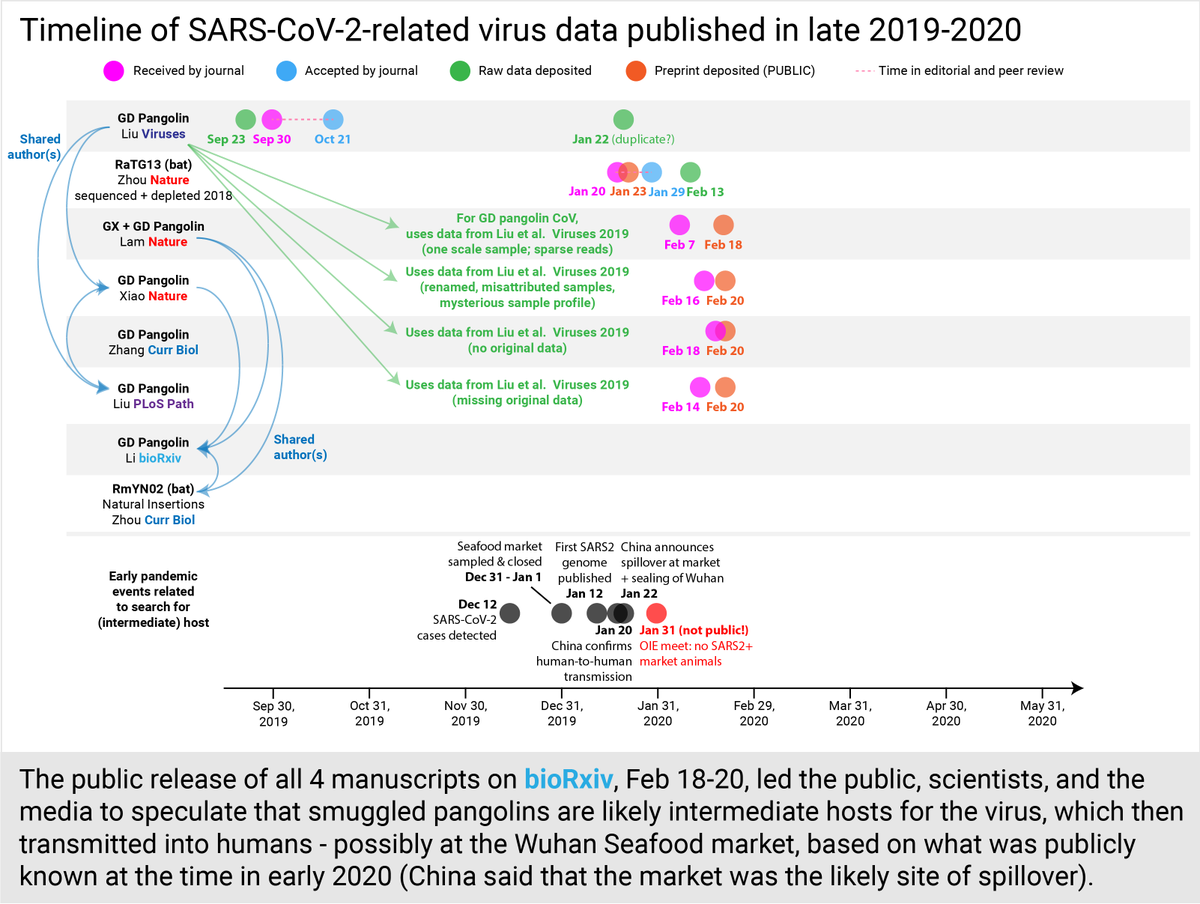
Within weeks, 4 manuscripts describing a pangolin virus with a similar spike RBD to SARS2 were submitted to journals (2 went to @nature); 3 were preprinted @biorxivpreprint the same day (Feb 20).
Remember the shared authors. (8/30)
Within weeks, 4 manuscripts describing a pangolin virus with a similar spike RBD to SARS2 were submitted to journals (2 went to @nature); 3 were preprinted @biorxivpreprint the same day (Feb 20).
Remember the shared authors. (8/30)
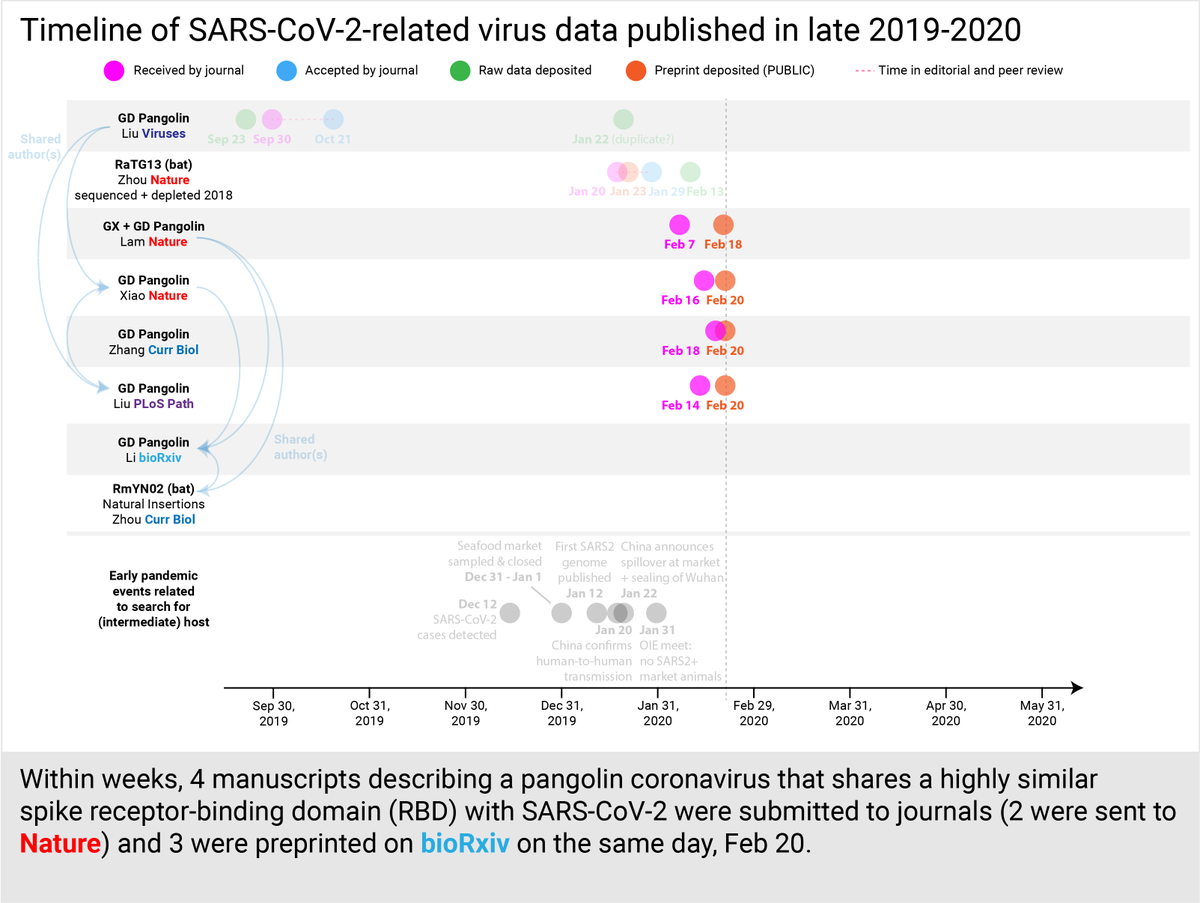
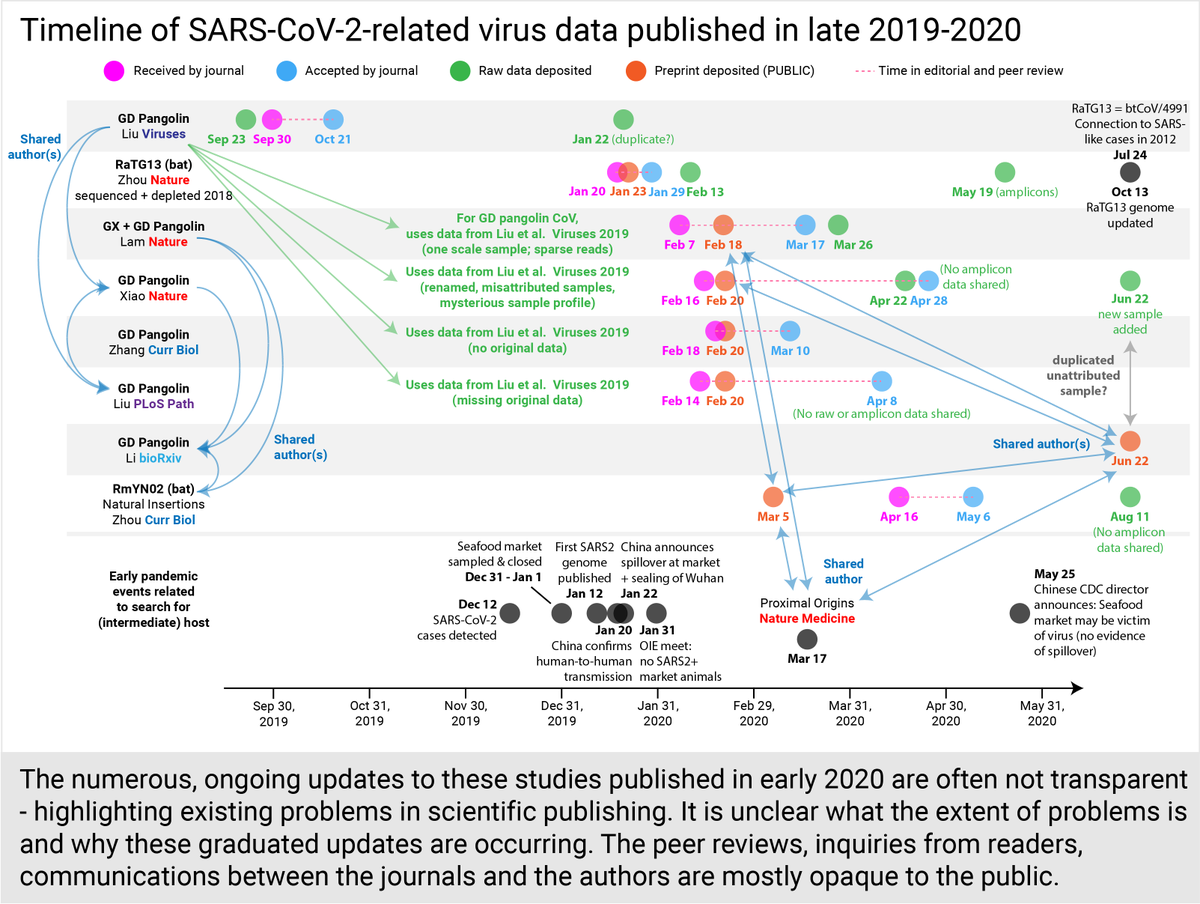
Notably, all 4 manuscripts relied heavily or solely on the Liu et al. Viruses paper. Xiao et al. @nature renamed samples, failed to attribute them properly, produced a profile that did not match any sample in their paper. Liu et al. @PLOSPathogens is still missing data. (9/30)
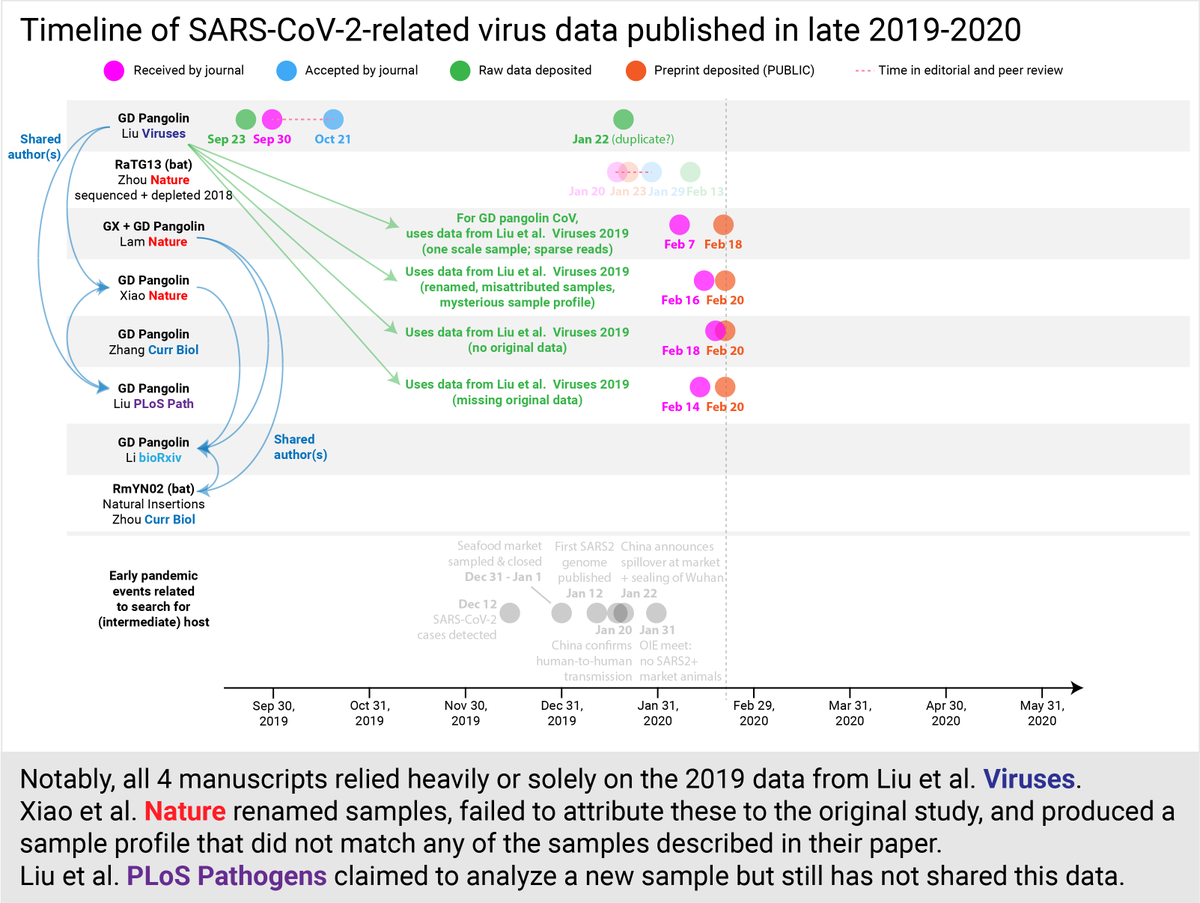
The public release of all 4 manuscripts on @biorxivpreprint between Feb 18-20 sent the public into a frenzy, speculating that pangolins were the intermediate hosts who had given SARS2 to humans in a Wuhan wet market - particularly based on the prevailing public info at the time.
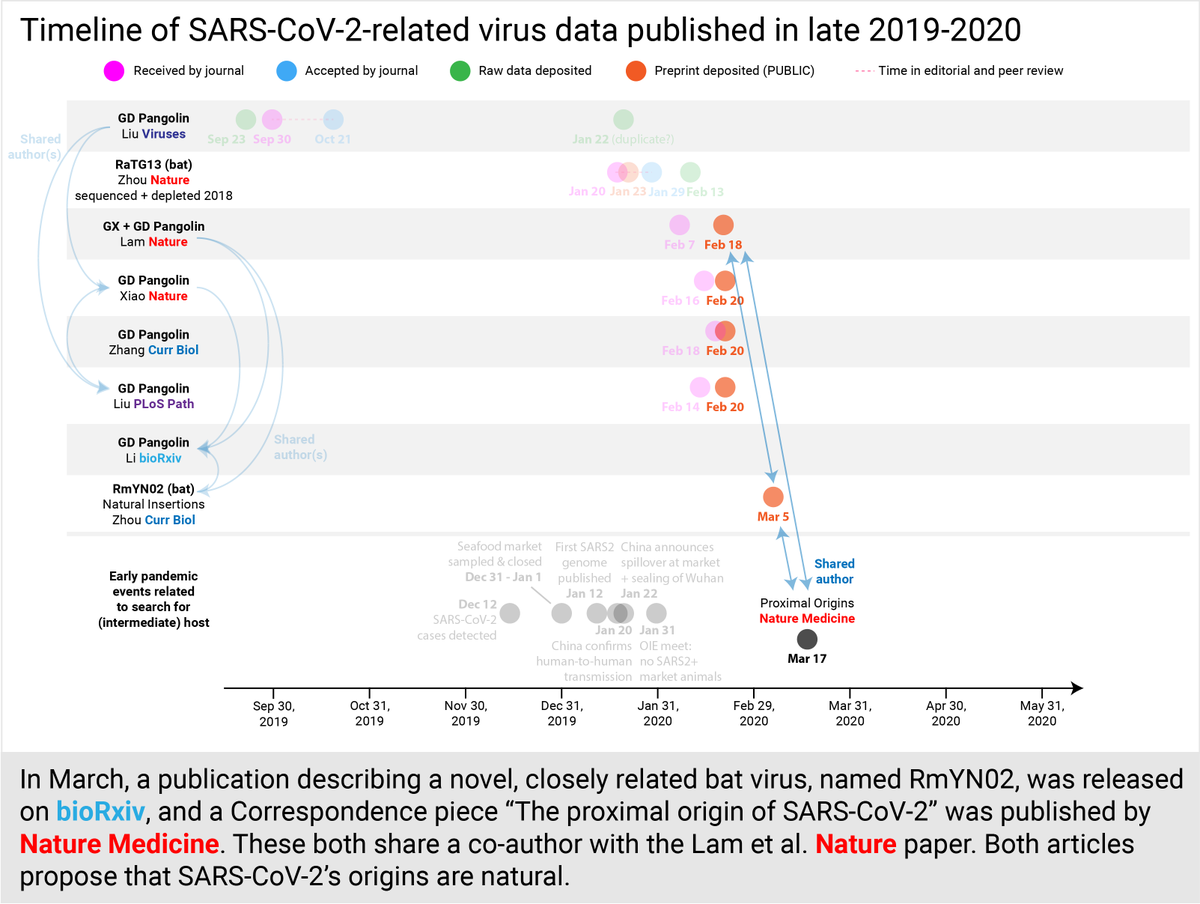
Soon, another preprint describing a closely related bat virus, RmYN02, and a @NatureMedicine correspondence "The proximal origins of SARS-CoV-2" were published. These both share an author with Lam et al. @nature and both proposed that SARS2's origins are natural. (11/30)
The manuscripts each passed journal+peer review in 2.5 months max (the fastest took only 9 days @nature).
However, none of the papers shared amplicon data. Some didn't even share raw data. It was impossible for scientists to independently assemble the published genomes. (12/30)
However, none of the papers shared amplicon data. Some didn't even share raw data. It was impossible for scientists to independently assemble the published genomes. (12/30)

May 19, amplicon data for RaTG13, the most closely related virus genome to SARS2, was quietly deposited onto @NCBI without explanation by Zhou et al. @nature This data revealed that the sample had been sequenced in 2017/2018 and not post-COVID as the paper suggested... (13/30)

Furthermore, the data do not match the original RaTG13 published genome. No explanation for how this could've happened. Or, more importantly, which private virus database the sequences and data had been stored in for years, and if there are other SARS viruses we don't know about.
Meanwhile, studies were pointing out that there was zero evidence of SARS2 spillover from animals into humans at the Wuhan Seafood market. By May 25, the Chinese CDC director announced that the market may have been a victim and not the site of spillover as they first thought.

June 22, a new pangolin virus preprint appears. On the same day, data from a new pangolin sample was added to the already published Xiao et al. @nature bioproject, but the sample was not described in any text/figure of the paper. Its profile instead resembled one in the preprint.
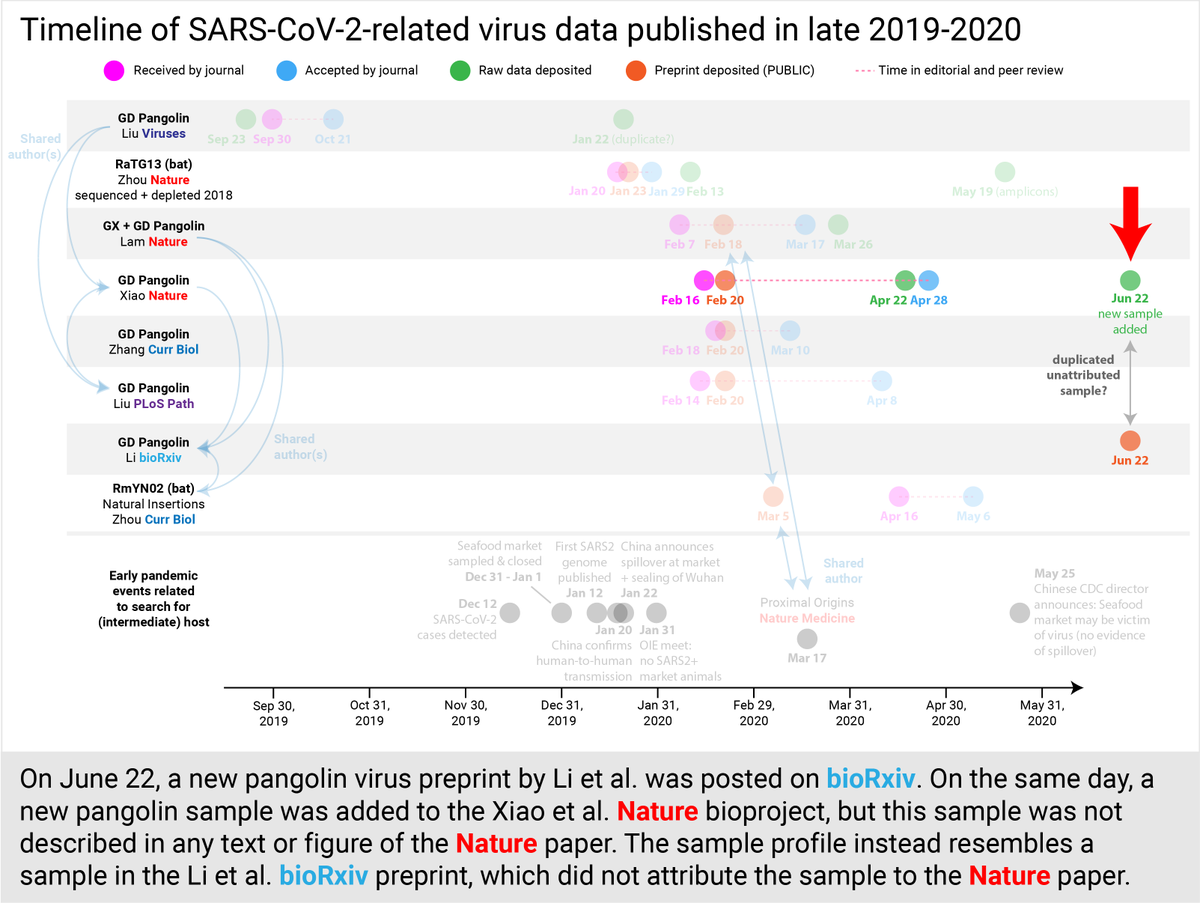
@nature had been notified in May that the core data in Xiao et al.'s paper was (and still is) not accurately reported. The mysterious sample profile in their extended fig 4 is still unaccounted for, even with the addition of the new sample. (17/30)

The story gets more complicated by this new preprint Li et al. @biorxivpreprint because it shares author(s) with Proximal Origins @NatureMedicine, Natural Insertions/RmYN02 @CurrentBiology, both pangolin CoV @nature papers, and thereby the original Liu et al. Viruses. (18/30)
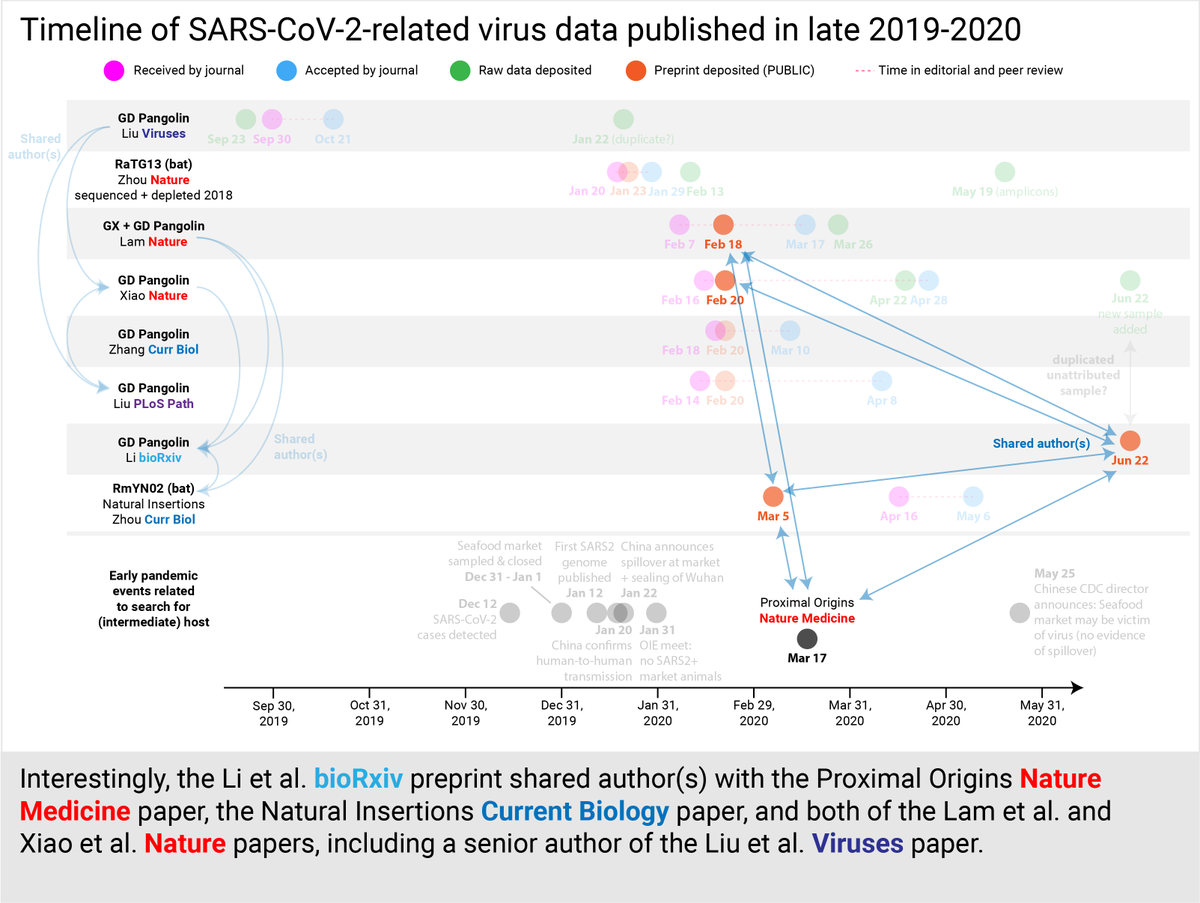
On July 7, @shingheizhan and I preprinted our finding that the Guangdong pangolin virus genomes by the 4 papers primarily used data/samples from the same batch of pangolins, and that key data was inaccurately reported by Xiao @nature and Liu @PLOSPathogens biorxiv.org/content/10.110…

We submitted our manuscript to a journal in May and tweeted about these findings to raise awareness about these problems. After 21 weeks in review, we received a very disappointing decision from the editor. However, we have updated our preprint. Separate thread to come. (20/30)
Separately, on July 24, the WIV confirmed suspicions that RaTG13 was not a novel virus, but actually had been published in 2016 (then named btCoV/4991) and that the sample was sequenced and depleted in 2018 (not post-COVID). Nothing left for independent verification. (21/30)
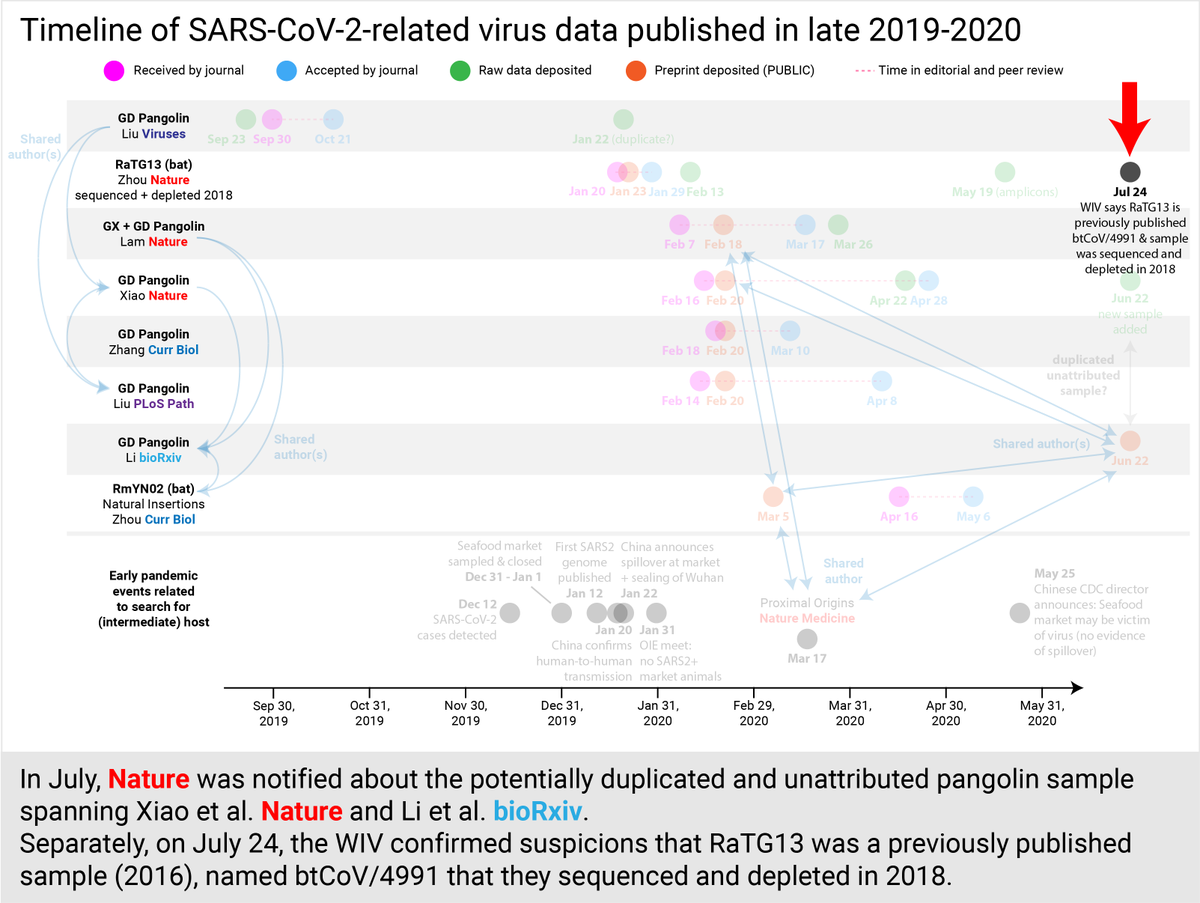
More troublingly, this raised questions about why RaTG13 had been inaccurately reported+unattributed in Zhou et al. @nature and even in the recent review by Shi in @NatureRevMicro. As well as its connections to mysterious SARS-like cases in 2012 investigated by top Chinese labs.
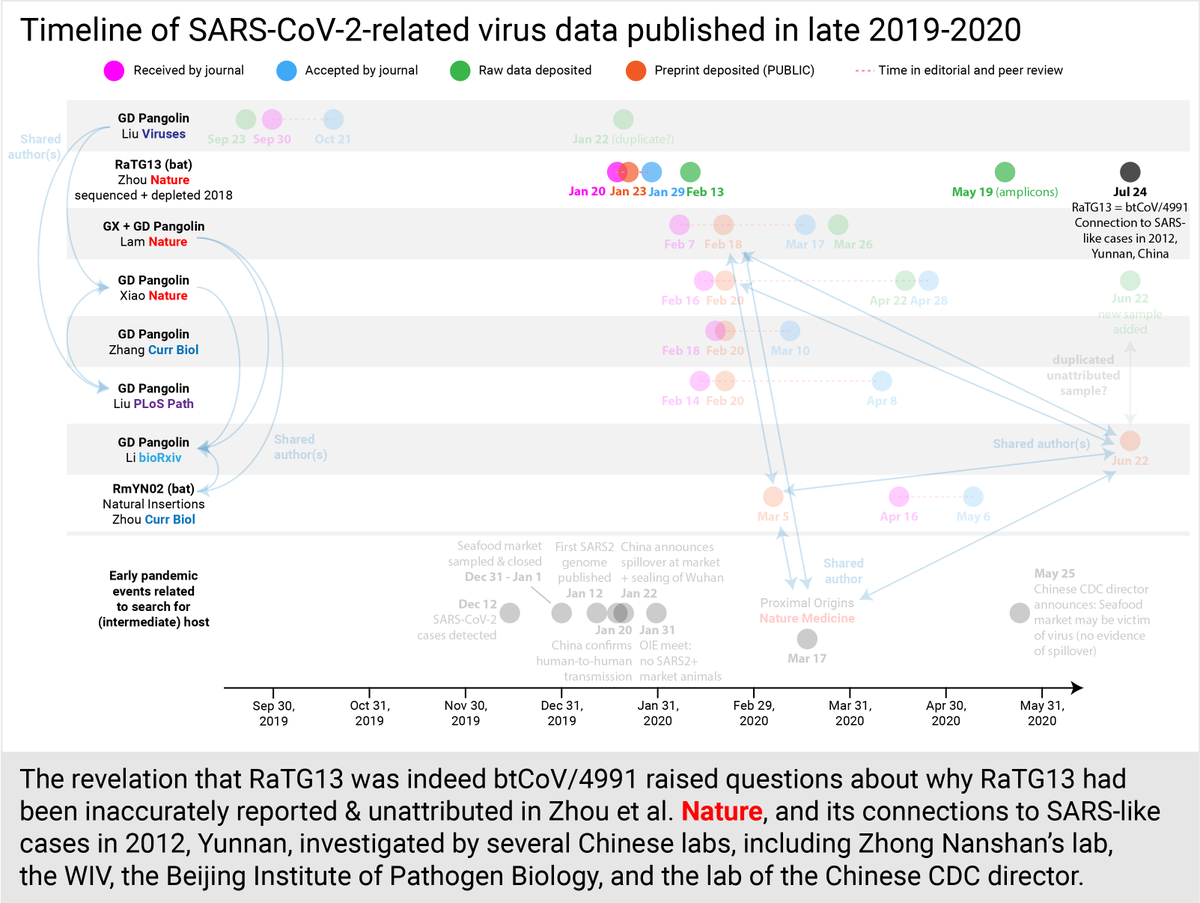
By September, scientists were pointing out the mismatched RaTG13 published genome vs the raw+amplicon data. Oct 13, the RaTG13 genome was quietly updated on @NCBI again no explanation by Zhou et al. @nature -how the mismatch occurred, how the sample was processed exactly. (23/30)
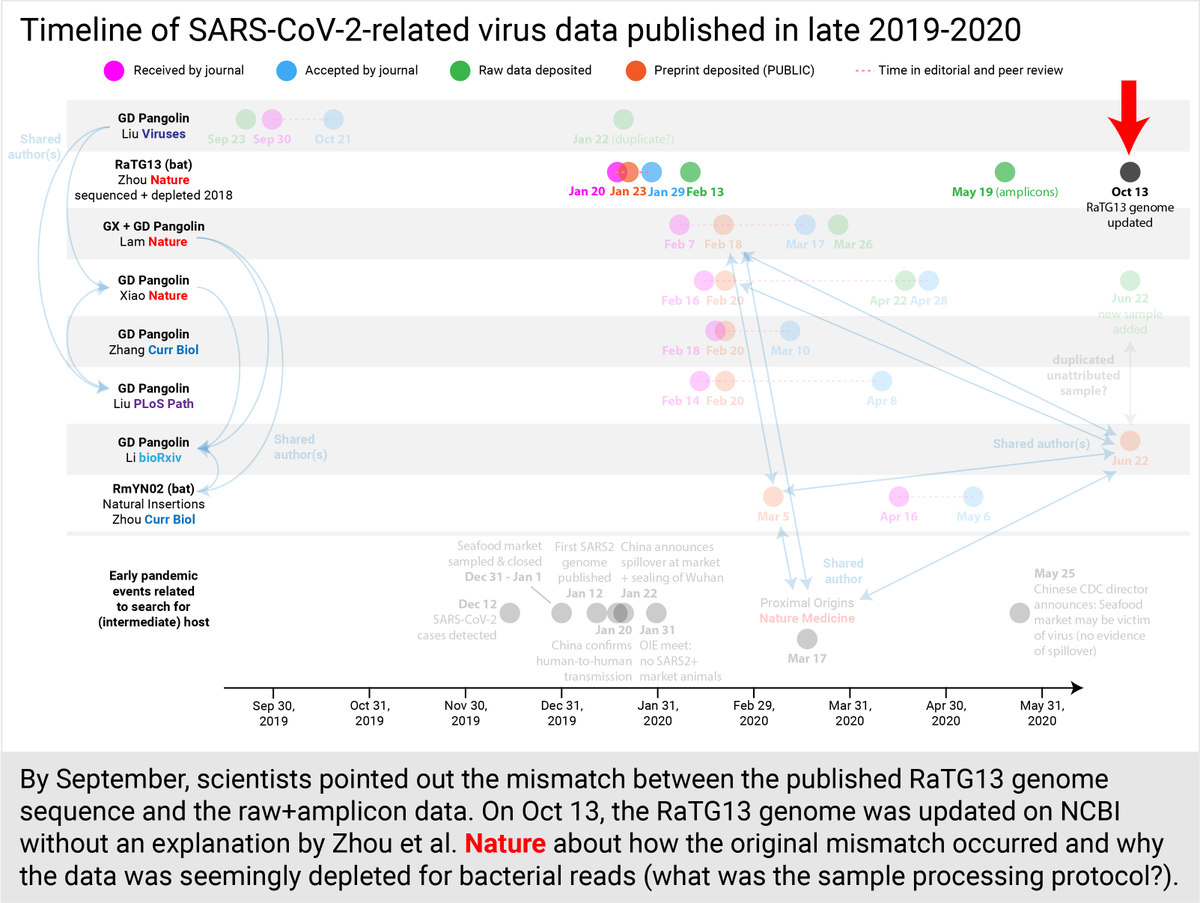
In parallel, in August, @CurrentBiology was notified about the missing raw+amplicon data for RmYN02. Thankfully, they made the authors share the raw data on a secure site, but the amplicon data is still missing; the published genome cannot be independently assembled. (24/30)

So, just putting all of these events back on the timeline. It's very frustrating that critical information on SARS2 origins is coming out almost on a need-to-know basis. And we have no idea what's going on behind the scenes among the journals, authors, peer reviewers. (25/30)
@shingheizhan and I have just spent 21+ weeks in review for 1 manuscript pointing out the major inaccuracies in key papers describing the Guangdong pangolin virus with a SARS2-like RBD. There's a lot of stuff going on that I think the public needs to demand to hear about. (26/30)
Where are we today?
The published GD pangolin CoV genome and RmYN02 genome still cannot be independently assembled because of data not shared with the public. @nature @PLOSPathogens @CurrentBiology
Isn't it important to get this data from the authors? (27/30)
The published GD pangolin CoV genome and RmYN02 genome still cannot be independently assembled because of data not shared with the public. @nature @PLOSPathogens @CurrentBiology
Isn't it important to get this data from the authors? (27/30)
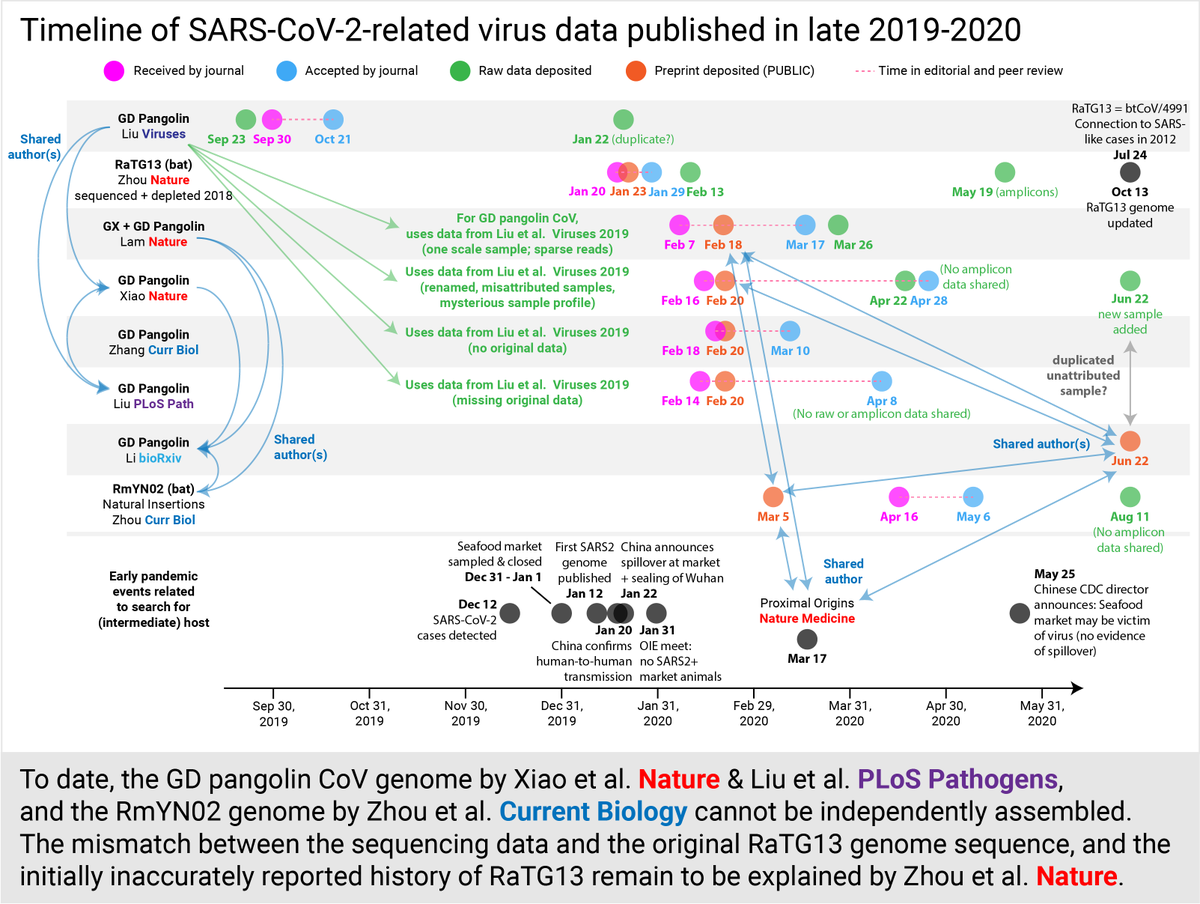
We still don't understand how the original RaTG13 genome did not match the raw+amplicon data. More importantly, why RaTG13 sample history was inaccurately reported by Zhou et al. @nature and why a correction to the paper hasn't been issued despite public admission RaTG13=4991.
I welcome public peer review by non-anonymous experts & fact-checking of the analysis above. After collecting your valuable feedback, I will edit the images into an animated gif, and prepare to write a short article about what we know and don't know about SARS-CoV-2 origins.
Saved the last tweet (30/30) to link my other tweets/threads pertaining to this issue:
Who am I?
bostonmagazine.com/news/2020/09/0…
Our first preprint
Furin cleavage site
RaTG13
Who am I?
https://twitter.com/Ayjchan/status/1303016315603558400
bostonmagazine.com/news/2020/09/0…
Our first preprint
https://twitter.com/Ayjchan/status/1256942320068542465
Furin cleavage site
https://twitter.com/Ayjchan/status/1266805310313967617
RaTG13
https://twitter.com/Ayjchan/status/1279755695382986757
Popular request: top points.
1. Public has little idea what happened/is happening behind the scenes with journals x authors of SARS2rCoV papers.
2. The closest related virus genomes to SARS2 cannot be independently assembled due to missing data/have unexplained indiscrepancies.
1. Public has little idea what happened/is happening behind the scenes with journals x authors of SARS2rCoV papers.
2. The closest related virus genomes to SARS2 cannot be independently assembled due to missing data/have unexplained indiscrepancies.
More questions coming in.
1. Is this a giant conspiracy.
No?
2. Does this mean SARS2 was from a lab?
We don't know. There's no sign of an independent investigation of origins right now. Plus, so much time has passed.
3. Is SARS2 an intentionally released bioweapon?
Unlikely!
1. Is this a giant conspiracy.
No?
2. Does this mean SARS2 was from a lab?
We don't know. There's no sign of an independent investigation of origins right now. Plus, so much time has passed.
3. Is SARS2 an intentionally released bioweapon?
Unlikely!
Also, several people asking me about what I think about Dr. Yan's reports. So I will link my threads:
1st report
2nd report
1st report
https://twitter.com/Ayjchan/status/1306393772985638913
2nd report
https://twitter.com/Ayjchan/status/1315282140574015488
I'll add to this, in case those threads tldr, that I don't doubt Dr. Yan's qualifications. I believe who she says she is - she has years of virology, scientific+medical training, one of the earliest to work on SARS2. I believe her about the cover-up on human-to-human transmission
I support whistleblowers. That being said, I will not automatically endorse Yan's reports. I do think there are massive problems identified by these reports that should be addressed by the scientific community. But, these are overshadowed by biased claims in the reports.
Next day update: I'm getting quite a bit of emails and tweets from people I don't know with links to papers and pdfs.
I apologize but I'm not going to click on any of these links or reply to these emails. It's not personal. I just cannot take the risk right now. Thank you.
I apologize but I'm not going to click on any of these links or reply to these emails. It's not personal. I just cannot take the risk right now. Thank you.
• • •
Missing some Tweet in this thread? You can try to
force a refresh





