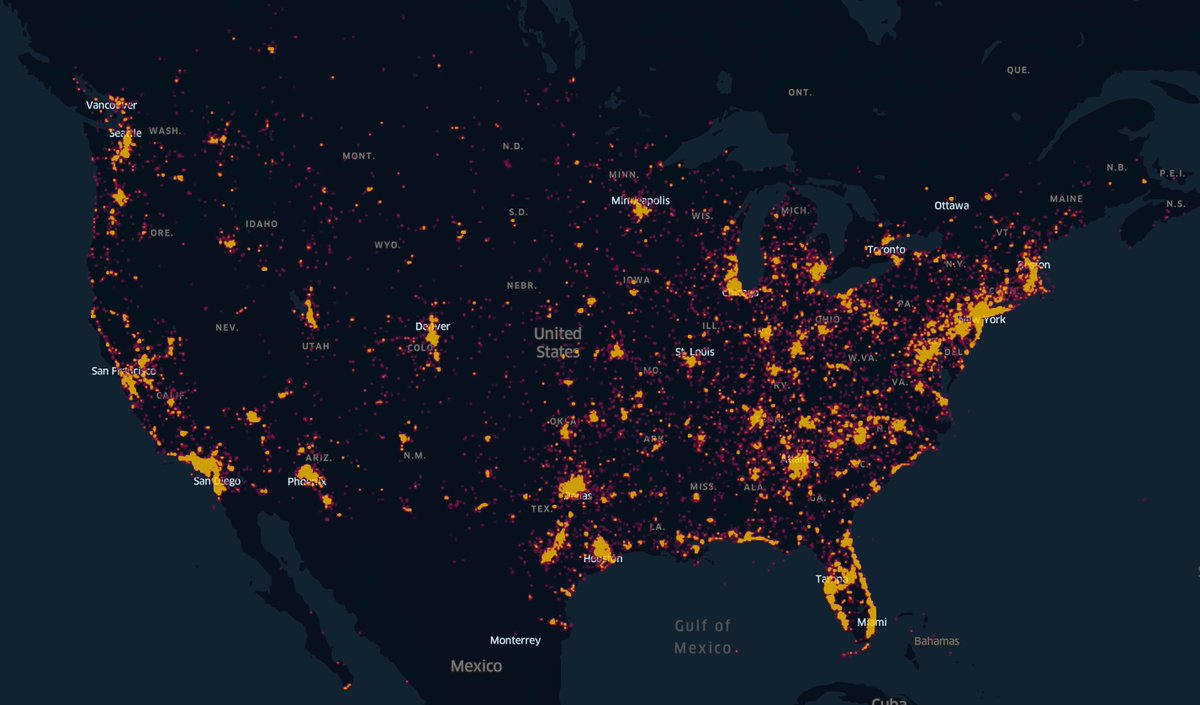
gps metadata of 68k videos uploaded to parler 
some parler users uploaded videos from US military bases. and one near the googleplex.
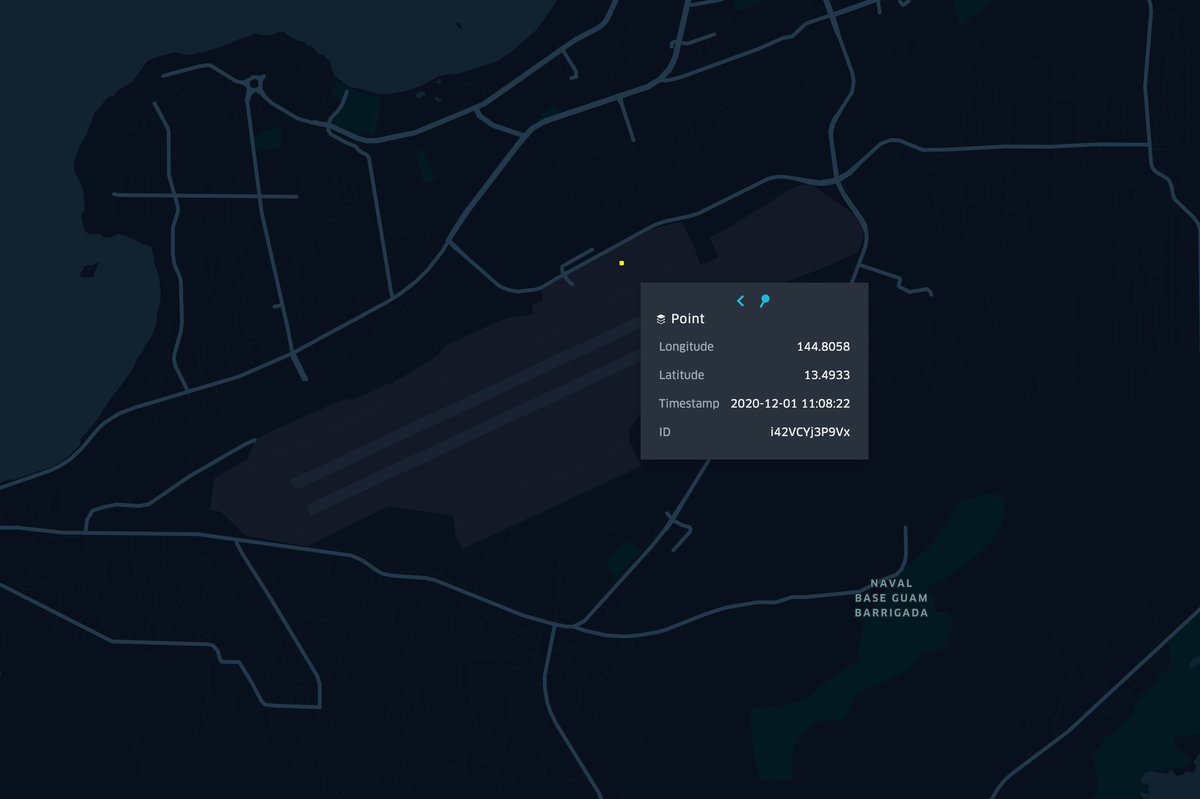
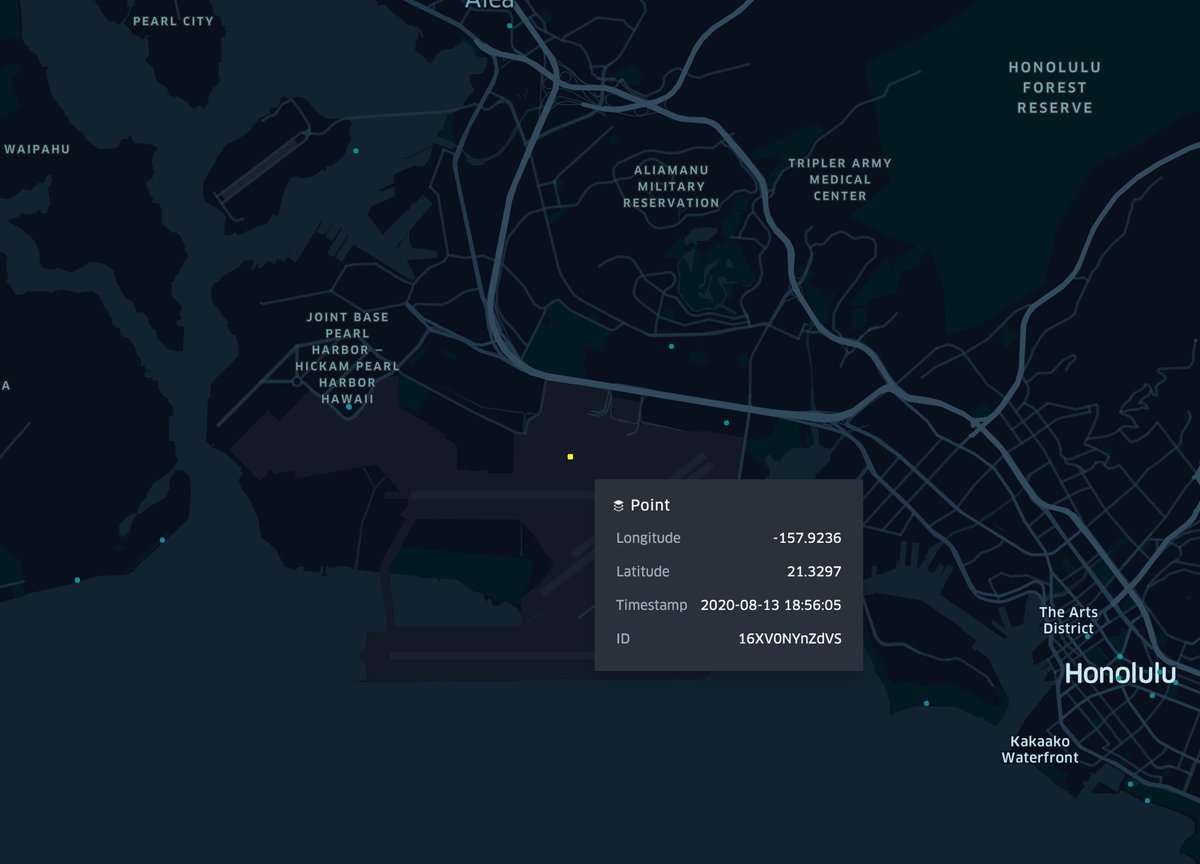
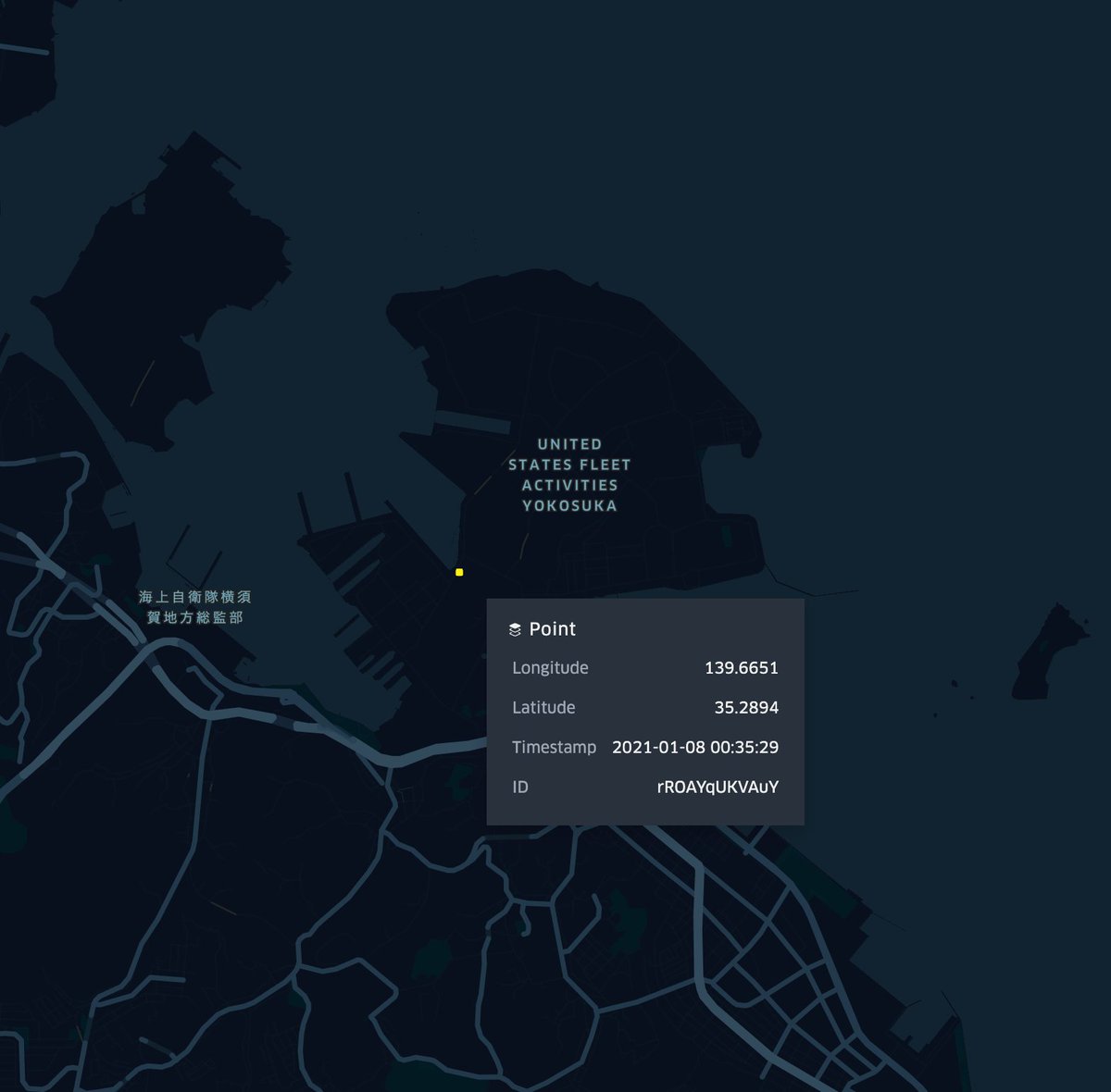
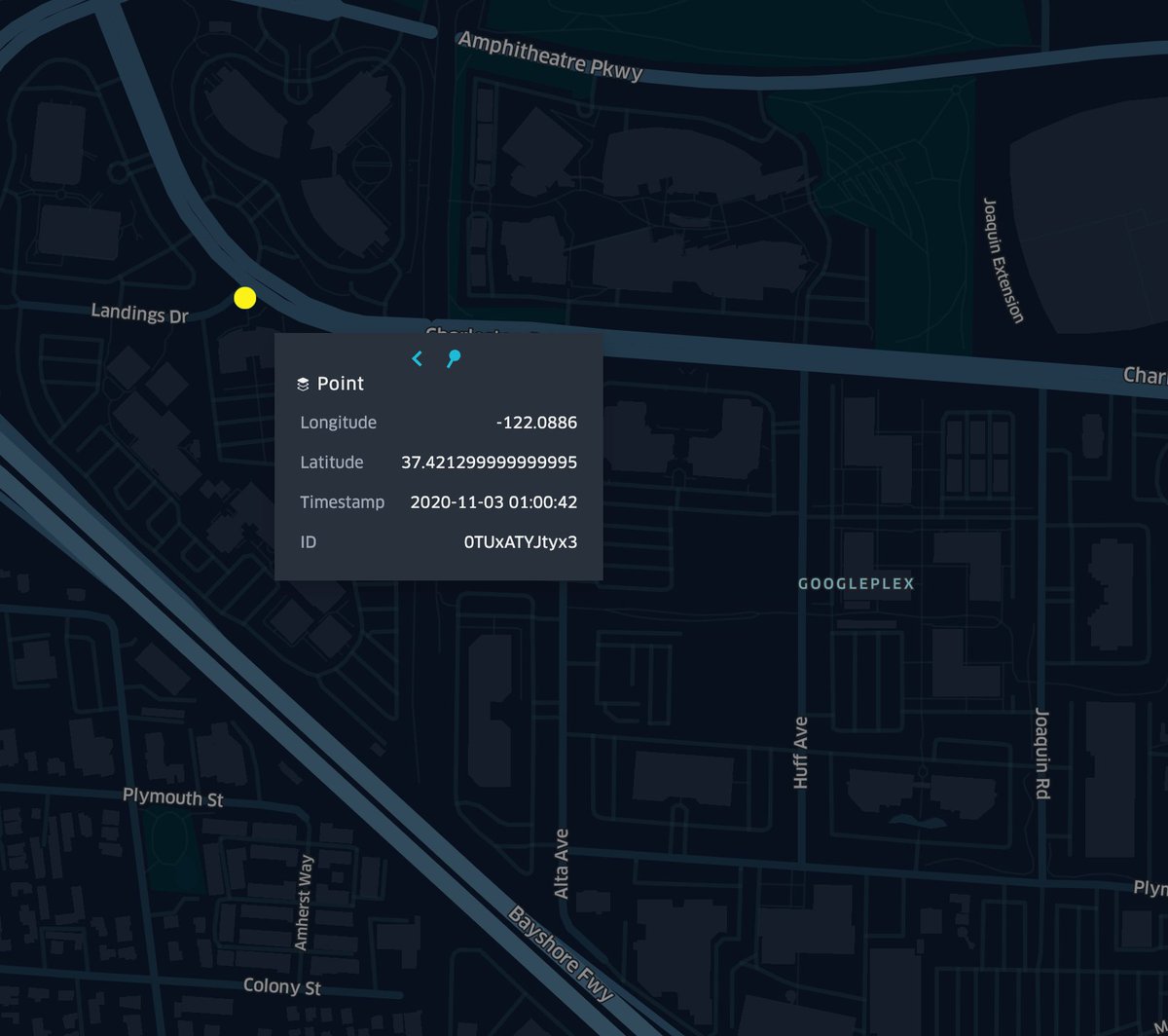
normalized by county thanks to @PeterCBlack
https://twitter.com/PeterCBlack/status/1348859919445807106?s=20
here is the csv data and the process behind creating this heatmap of parler video GPS locations gist.github.com/kylemcdonald/8…
here is an interactive map for all the geocoded parler videos. you can look into specific cities and countries, and check timestamps and video ids kylemcdonald.net/parler/map/
a short tutorial on how to view the remaining parler videos by editing your DNS records. many have been made inaccessible, but some are still available gist.github.com/kylemcdonald/d…
you can see people moving from the white house (bottom) to the capitol (top), if you plot the video metadata with time on the x axis and longitude on the y axis. it looks like almost every second is covered from at least one angle.

1200+ videos uploaded to parler in the DC area on 1/6

wasn’t glenn the guy on backup vocals for poitras and snowden? really taking a new direction for his sophomore album.
https://twitter.com/ggreenwald/status/1348619731734028293
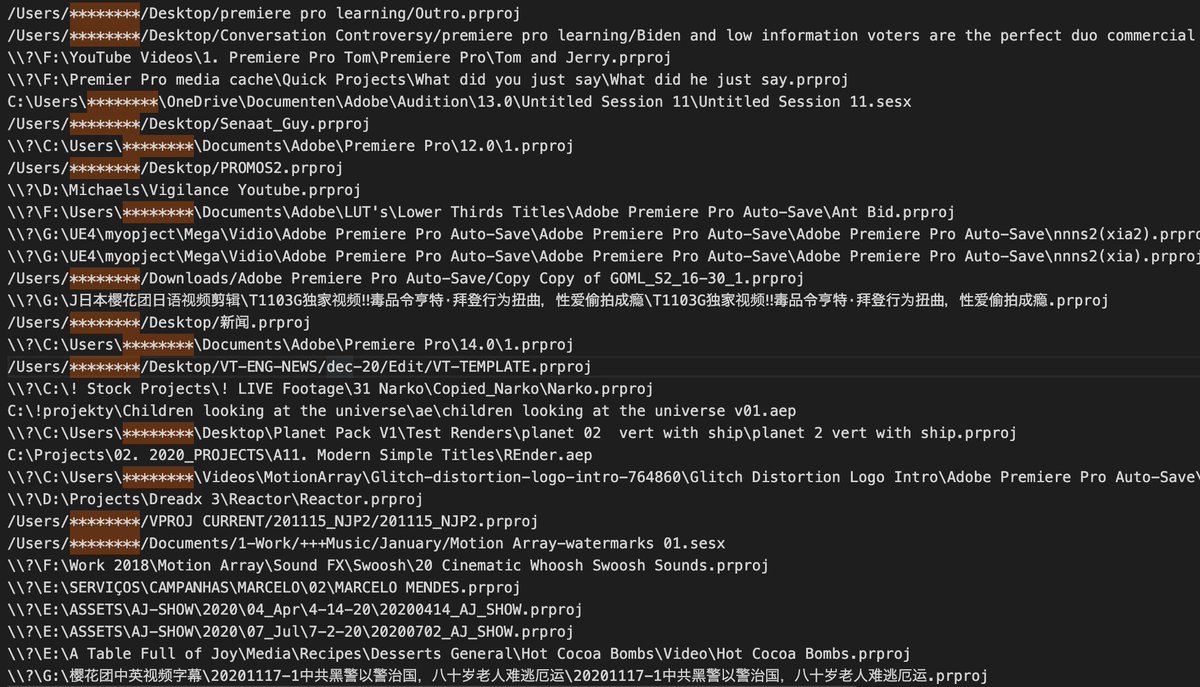
there are around 14,000 parler videos that include personal computer usernames in the video metadata. these videos are typically edited with adobe products. (i replaced identifiable names with asterisks.)
• • •
Missing some Tweet in this thread? You can try to
force a refresh