
Seriously though, how the heck can a computer recognize what's in an image?
Grab a coffee ☕️, and let's talk about one of the core ideas that makes this possible.
(I'll try to stay away from the math, I promise.)
👇
Grab a coffee ☕️, and let's talk about one of the core ideas that makes this possible.
(I'll try to stay away from the math, I promise.)
👇
If you are a developer, spend a few minutes trying to think about a way to solve this problem:
→ Given an image, you want to build a function that determines whether it shows a person's face.
2/
→ Given an image, you want to build a function that determines whether it shows a person's face.
2/

It gets overwhelming fast, right?
What are you going to do with all of these pixels?
3/
What are you going to do with all of these pixels?
3/
Alright, you get the idea: this is a hard problem to solve, and we can't just develop our way out of it.
So let's talk about machine learning.
More specifically, let's talk about Convolutional Neural Networks.
4/
So let's talk about machine learning.
More specifically, let's talk about Convolutional Neural Networks.
4/
Well, I'm skipping like 300 layers of complexity here.
We should start talking about neural networks and build from that idea, but that'll be boring, and I'm sure you've heard of them before.
If you want a refresher, here is an amazing video:
5/
We should start talking about neural networks and build from that idea, but that'll be boring, and I'm sure you've heard of them before.
If you want a refresher, here is an amazing video:
5/
Fully connected networks are cool, but convolutional layers transformed the field.
I want to focus on them, so next time somebody mentions "convolution," you know exactly what's going on.
6/
I want to focus on them, so next time somebody mentions "convolution," you know exactly what's going on.
6/
Before getting too technical, let's try to break down the problem in a way that makes the solution a little bit more intuitive.
Understanding an image's contents is not about individual pixels but about the patterns formed by nearby pixels.
7/
Understanding an image's contents is not about individual pixels but about the patterns formed by nearby pixels.
7/
For instance, think about Lena's picture attached here.
You get a bunch of pixels that together form the left eye. Another bunch that makes up the right eye. You have the nose, mouth, eyebrows, etc.
Put them together, and you get her face.
8/
You get a bunch of pixels that together form the left eye. Another bunch that makes up the right eye. You have the nose, mouth, eyebrows, etc.
Put them together, and you get her face.
8/

Wave your magic wand and imagine you could build a function specializing in detecting each part of the face.
In the end, you run every function, and if you can find every piece, you would flag the image as being a face.
Easy, right?
9/
In the end, you run every function, and if you can find every piece, you would flag the image as being a face.
Easy, right?
9/
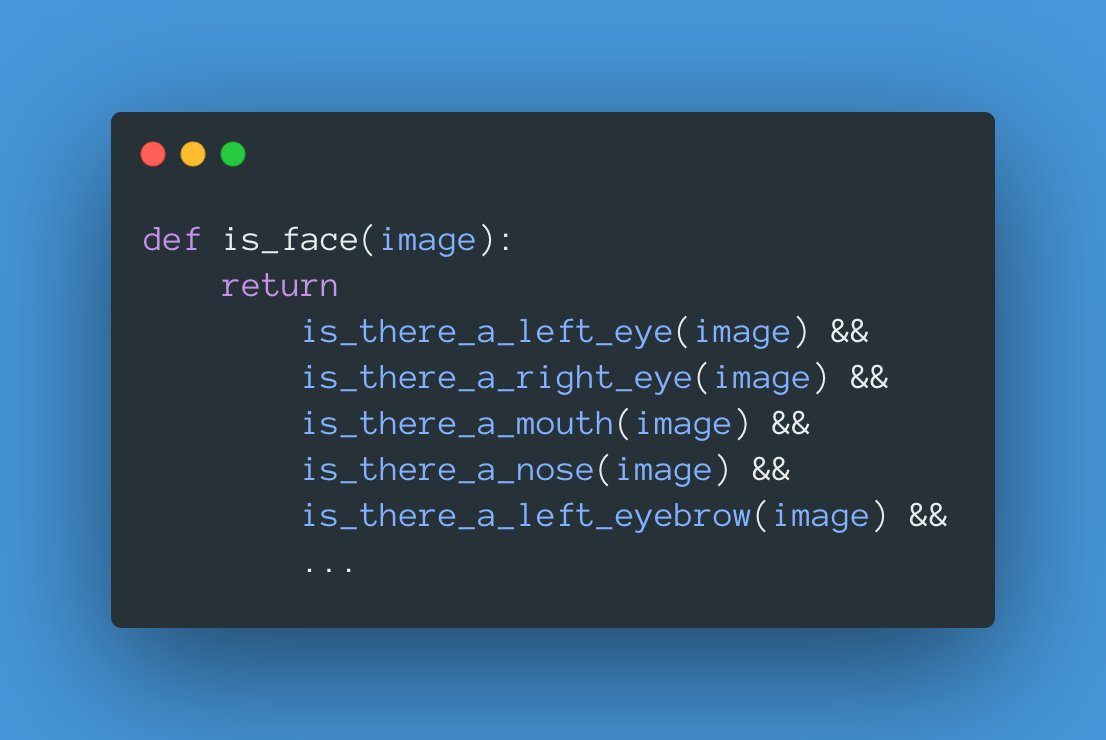
But, how do we find an eye on a picture?
Well, we could keep breaking the problem into smaller pieces.
There are lines, circles, colors, patterns that together make up an eye. We could build more functions that detect each one of those separately.
10/
Well, we could keep breaking the problem into smaller pieces.
There are lines, circles, colors, patterns that together make up an eye. We could build more functions that detect each one of those separately.
10/
See where I'm going here?
We could build hundreds of functions, each one specializing in a specific portion of the face. Then have them look at the entire picture.
We can then put them together like a giant puzzle to determine whether we are looking at a face.
🙃
11/
We could build hundreds of functions, each one specializing in a specific portion of the face. Then have them look at the entire picture.
We can then put them together like a giant puzzle to determine whether we are looking at a face.
🙃
11/
I'm happy with that idea because I think it makes sense!
But building hundreds of little functions looking for individual patterns in an image is still a huge hurdle.
😬
Where do we start?
12/
But building hundreds of little functions looking for individual patterns in an image is still a huge hurdle.
😬
Where do we start?
12/
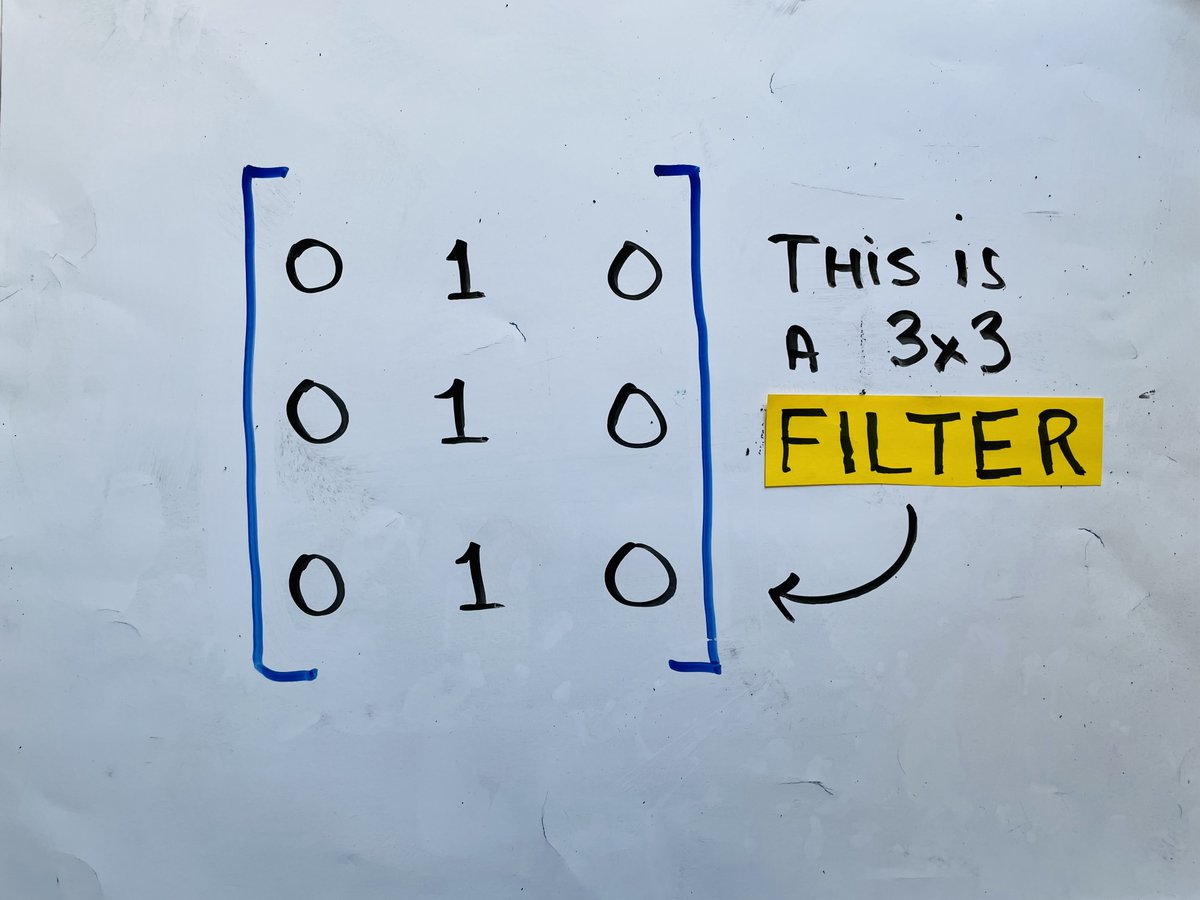
Enter the idea of a "filter," a small square matrix that we will move across the image from top left to bottom right.
Every time we do this, we compute a value using a "convolution" operation.
13/
Every time we do this, we compute a value using a "convolution" operation.
13/
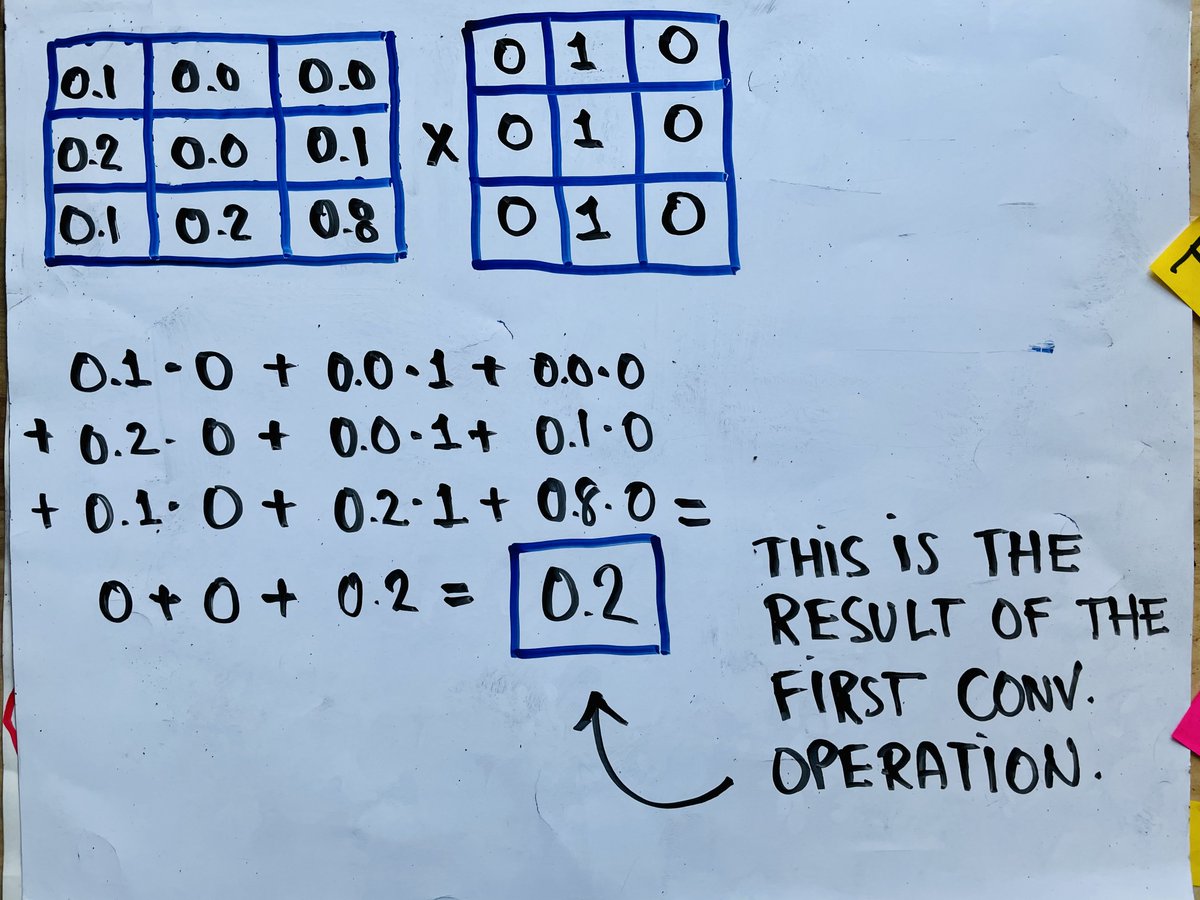
Look at this picture.
A convolution operation is a dot product (element-wise multiplication) between the filter and the input image patch. Then the result is summed to result in a single value.
After doing this, we move the filter over one position and do it again.
14/
A convolution operation is a dot product (element-wise multiplication) between the filter and the input image patch. Then the result is summed to result in a single value.
After doing this, we move the filter over one position and do it again.
14/
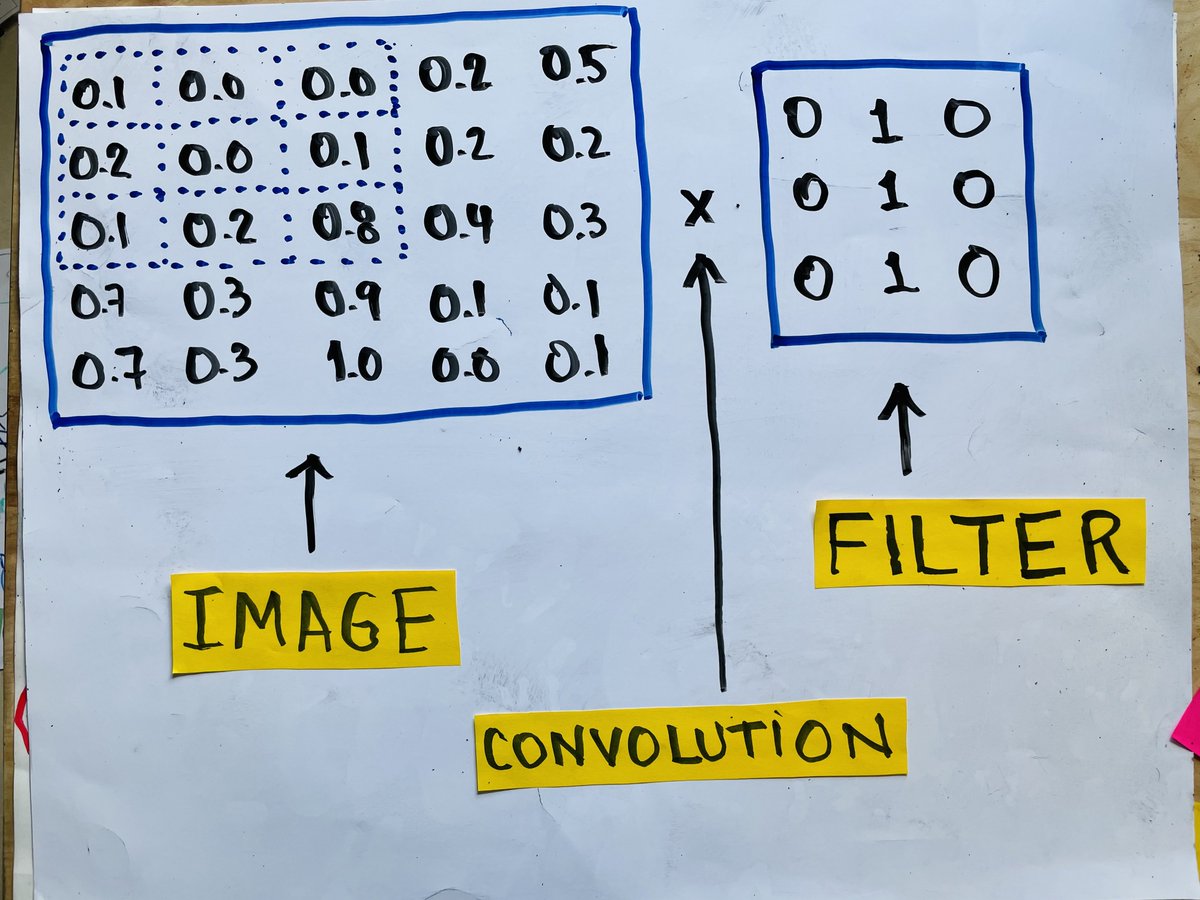
Here is the first convolution operation.
It produces a single value (0.2)
After doing this, we will convolve the filter with the next patch from the image and repeat this until we cover the whole picture.
Ok, this is as much math as I want you to endure.
15/
It produces a single value (0.2)
After doing this, we will convolve the filter with the next patch from the image and repeat this until we cover the whole picture.
Ok, this is as much math as I want you to endure.
15/
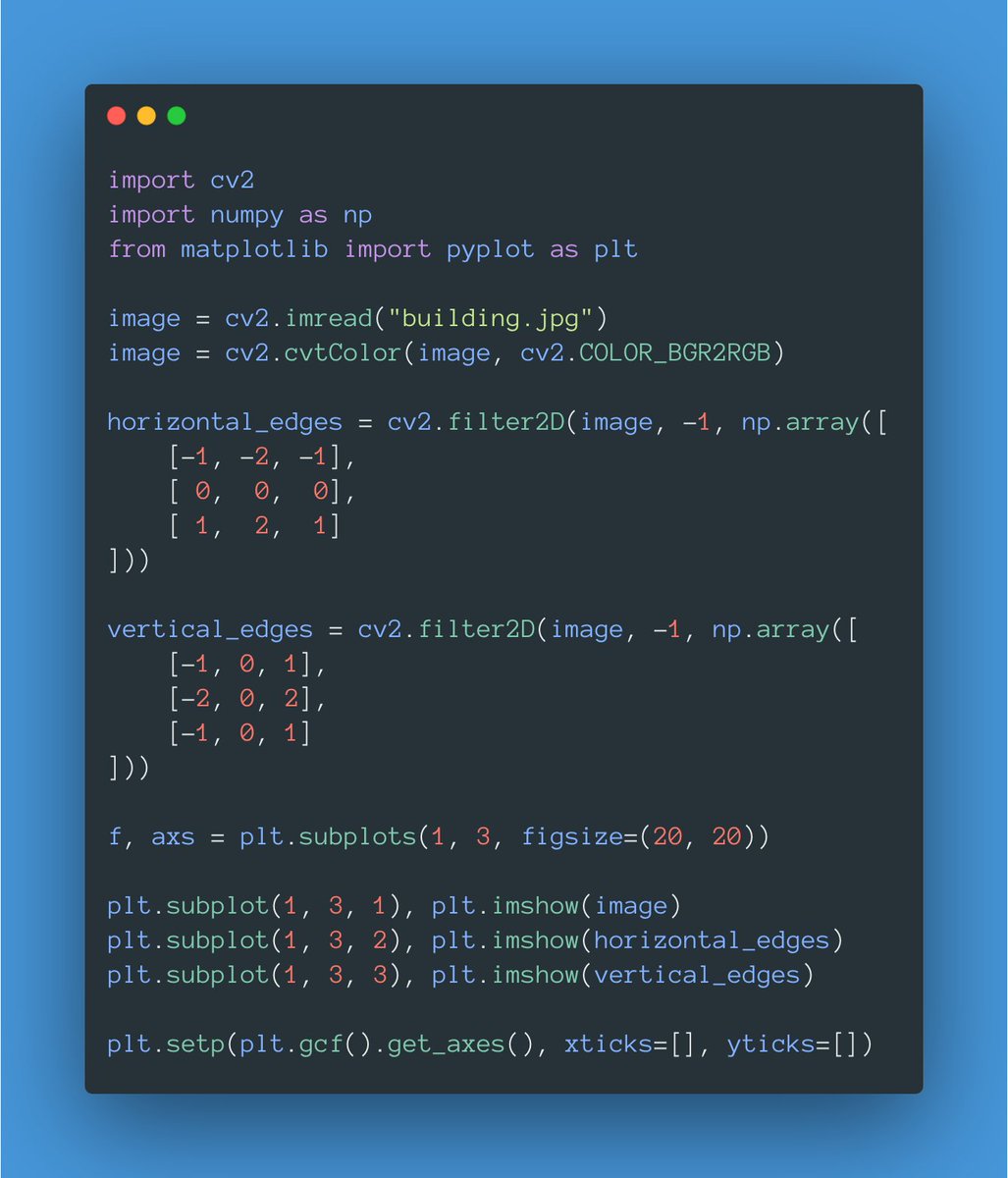
Here's what's cool about this: convolving an image with different filters will produce different outputs!
The attached code uses the filter2d() function from OpenCV to convolve an image with two different filters.
Code: gist.github.com/svpino/be7ba9b…
16/
The attached code uses the filter2d() function from OpenCV to convolve an image with two different filters.
Code: gist.github.com/svpino/be7ba9b…
16/
Look at the results here.
Notice how one of the pictures shows all the horizontal edges, while the other only shows the vertical edges.
Pretty cool, huh?
17/
Notice how one of the pictures shows all the horizontal edges, while the other only shows the vertical edges.
Pretty cool, huh?
17/

Even better: since we are convolving each filter with the entire input image, we can detect features regardless of where they are located!
This is a crucial characteristic of Convolutional Neural Networks. Smart people call it "translation invariance."
18/
This is a crucial characteristic of Convolutional Neural Networks. Smart people call it "translation invariance."
18/
Quick summary so far:
▫️ We have a bunch of filters
▫️ Each one worries about a specific pattern
▫️ We convolve them with the input image
▫️ They can detect patterns wherever they are
Do you see where this is going?
19/
▫️ We have a bunch of filters
▫️ Each one worries about a specific pattern
▫️ We convolve them with the input image
▫️ They can detect patterns wherever they are
Do you see where this is going?
19/
The functions that we talked about before are just different filters that highlight different patterns from our image!
We can then combine each filter to find larger patterns to uncover whether we have a face.
20/
We can then combine each filter to find larger patterns to uncover whether we have a face.
20/
One more thing: how do we come up with the values that we need for each filter?
Horizontal and vertical edges aren't a big deal, but we will need much more than that to solve our problem.
21/
Horizontal and vertical edges aren't a big deal, but we will need much more than that to solve our problem.
21/
Here is where the magic happens!
Our network will learn the value of the filters during training!
We'll show it many faces, and the network will come up with useful filters that will help detect faces.
🤯
22/
Our network will learn the value of the filters during training!
We'll show it many faces, and the network will come up with useful filters that will help detect faces.
🤯
22/
None of this would be possible without everything you already know about neural networks.
I also didn't talk about other operations that make Convolutional Networks work.
But hopefully, this thread highlights the main idea: convolutions rock!
23/
I also didn't talk about other operations that make Convolutional Networks work.
But hopefully, this thread highlights the main idea: convolutions rock!
23/
If you enjoy my attempts to make machine learning a little more intuitive, stay tuned and check out @svpino for more of these threads.
There's no way to tell what specific features the filters will learn.
The expectation is that they'll focus on the face but they may learn useless features as well.
Hence the importance of validating the results and properly curating the dataset.
The expectation is that they'll focus on the face but they may learn useless features as well.
Hence the importance of validating the results and properly curating the dataset.
https://twitter.com/miraculixxs/status/1359112647753543691?s=20
Great question!
In this particular case, the resultant images have the same dimensions because filter2d() uses cv2.BORDER_DEFAULT to replicate the border.
But you are right: the result of a pure convolution operation will give us smaller dimensions.
In this particular case, the resultant images have the same dimensions because filter2d() uses cv2.BORDER_DEFAULT to replicate the border.
But you are right: the result of a pure convolution operation will give us smaller dimensions.
https://twitter.com/rafaelmarch3/status/1359120522190192649?s=20
Speaking about patterns and generalization, here is the natural continuation of this thread:
https://twitter.com/svpino/status/1360462217829900290?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh







