
We have a major incident on SBG2. The fire declared in the building. Firefighters were immediately on the scene but could not control the fire in SBG2. The whole site has been isolated which impacts all services in SGB1-4. We recommend to activate your Disaster Recovery Plan.
Update 5:20pm. Everybody is safe.
Fire destroyed SBG2. A part of SBG1 is destroyed. Firefighters are protecting SBG3. no impact SBG4.
Fire destroyed SBG2. A part of SBG1 is destroyed. Firefighters are protecting SBG3. no impact SBG4.
Update 7:20am
Fire is over. Firefighters continue to cool the buildings with the water.
We don’t have the access to the site. That is why SBG1, SBG3, SBG4 won’t be restarted today.
Fire is over. Firefighters continue to cool the buildings with the water.
We don’t have the access to the site. That is why SBG1, SBG3, SBG4 won’t be restarted today.
Update 10am. (I’m there).
We finished to shutdown the UPS in SBG3. Now they are off. We are looking to enter into SBG3 and check the servers. The goal is to create a plan to restart , at least SBG3/SBG4, maybe SBG1. To do so, we need to check the network rooms too.
We finished to shutdown the UPS in SBG3. Now they are off. We are looking to enter into SBG3 and check the servers. The goal is to create a plan to restart , at least SBG3/SBG4, maybe SBG1. To do so, we need to check the network rooms too.
Update 11:20am
All servers in SBG3 are okey. They are off, but not impacted. We create a plan how to restart them and connect to the network. no ETA.
Now, we will verify SBG1.
All servers in SBG3 are okey. They are off, but not impacted. We create a plan how to restart them and connect to the network. no ETA.
Now, we will verify SBG1.
Update 11:40am
The network room in SBG1 is okey. 4 rooms destroyed. 8 rooms are okey.
The network room in SBG1 is okey. 4 rooms destroyed. 8 rooms are okey.
Update 1pm
Plan for the next 1-2 weeks:
1) rebuilding 20KV for SBG3
2) rebuilding 240V in SBG1/SBG4
3) verifying DWDM/routers/switchs in the network room A (SBG1). checking the fibers Paris/Frankfurt
4) rebuilding the network room B (in SBG5). checking fibers Paris/Frankfurt
Plan for the next 1-2 weeks:
1) rebuilding 20KV for SBG3
2) rebuilding 240V in SBG1/SBG4
3) verifying DWDM/routers/switchs in the network room A (SBG1). checking the fibers Paris/Frankfurt
4) rebuilding the network room B (in SBG5). checking fibers Paris/Frankfurt
Update 4pm
We plan to restart SBG1+SBG4+the network by Monday March,15 and SBG3 by Friday March,19.
In RBX+GRA we have the stock of new servers, pcc, pci ready to be delivered for all the impacted customers. Of course for free. We will add 10K servers in the next 3-4 weeks.
We plan to restart SBG1+SBG4+the network by Monday March,15 and SBG3 by Friday March,19.
In RBX+GRA we have the stock of new servers, pcc, pci ready to be delivered for all the impacted customers. Of course for free. We will add 10K servers in the next 3-4 weeks.
Update 9:30pm
The teams are working to fix the issue on APIv6, Manager, Support etc. restoring the emails services hosted in SBG2.
The teams are working to fix the issue on APIv6, Manager, Support etc. restoring the emails services hosted in SBG2.
Many thanks for all the empathy messages you sent us today ! I want to thank the teams who have been working all night/day.
It’s been the worst day for the last 22y and there is no word strong enough to say how sorry I feel today.
We keep working hard to restart SBG1/3/4 asap!
It’s been the worst day for the last 22y and there is no word strong enough to say how sorry I feel today.
We keep working hard to restart SBG1/3/4 asap!
Update 3pm
1/3
From yesterday, we had the meetings with Police, DREAL, Experts and Insurance. Also, we started to clean up the site. The goal is to have the full and secured access to SBG1, SBG3 and SBG4.
1/3
From yesterday, we had the meetings with Police, DREAL, Experts and Insurance. Also, we started to clean up the site. The goal is to have the full and secured access to SBG1, SBG3 and SBG4.
2/3
The optical network from Network Room A (SBG1) to Paris + Frankfurt works.
Working on the power SBG1 option based on the generators.
The SBG3’ generators work. Good option to use if the network is UP before we finished to rebuild SBG3’s 20KV.
The optical network from Network Room A (SBG1) to Paris + Frankfurt works.
Working on the power SBG1 option based on the generators.
The SBG3’ generators work. Good option to use if the network is UP before we finished to rebuild SBG3’s 20KV.
3/3
In 1H I will post a short (8m) video with more informations / more details.
In 1H I will post a short (8m) video with more informations / more details.
Update 11 mars 16h40
C'est trop lent de vous communiquer tous ces détails via 280 caractères de Twitter. Voici un concentré de 8min qui résume la situation à ce jour.
(English version is coming)
ovh.com/fr/images/sbg/…
C'est trop lent de vous communiquer tous ces détails via 280 caractères de Twitter. Voici un concentré de 8min qui résume la situation à ce jour.
(English version is coming)
ovh.com/fr/images/sbg/…

Update 11 mars 16h40
It's too slow to give you all the information with just 280 chars. Here, my video with 8min of information we have today.
ovh.com/fr/images/sbg/…
It's too slow to give you all the information with just 280 chars. Here, my video with 8min of information we have today.
ovh.com/fr/images/sbg/…

Update March 12, 8am
https://twitter.com/goodmorning_biz/status/1370267547359141890
Update March,12 11am
1/4
This afternoon, we will send the email to each customer with his specific situation and the options. In any case, we recommand to restart the service in our others DC (RBX/GRA) where we are adding the additional resources. Free months will be applied asap
1/4
This afternoon, we will send the email to each customer with his specific situation and the options. In any case, we recommand to restart the service in our others DC (RBX/GRA) where we are adding the additional resources. Free months will be applied asap
Update March,12 11am
2/4
We are working with the insurance’s experts to repower SBG1/3/4 today from the generators. The goal is to verify, room by room, equipment by equipment, that infra works.
We don’t expect to restart the servers before next week.
2/4
We are working with the insurance’s experts to repower SBG1/3/4 today from the generators. The goal is to verify, room by room, equipment by equipment, that infra works.
We don’t expect to restart the servers before next week.
Update March,12 11am
3/4
New network room (B) + 20KV for SBG3 are assembled and will be on the road this night, on the side tomorrow. Then, we start pluging them. It will take over the generators SBG3 by Fri.
We verify 20KV + 240V in SBG1/SBG4 to take over the generators by Tue
3/4
New network room (B) + 20KV for SBG3 are assembled and will be on the road this night, on the side tomorrow. Then, we start pluging them. It will take over the generators SBG3 by Fri.
We verify 20KV + 240V in SBG1/SBG4 to take over the generators by Tue
Update March,12 11am
4/4
We will start repowering SBG1/SBG4 by the end of the next week, Fri, 19. It will take 2 days to have all servers UP.
We will start repowering SBG3 by the mid of the next week, Wed, 17, it will take 6-8 days to have all servers UP.
4/4
We will start repowering SBG1/SBG4 by the end of the next week, Fri, 19. It will take 2 days to have all servers UP.
We will start repowering SBG3 by the mid of the next week, Wed, 17, it will take 6-8 days to have all servers UP.
State of Backup Service (Free or Paid) for the SBG customers:
1/5
- FTP Backup in SBG (Free/Paid) for VPS and Baremetal : the datas are in RBX. You have full access.
1/5
- FTP Backup in SBG (Free/Paid) for VPS and Baremetal : the datas are in RBX. You have full access.
State of Backup Service (Free or Paid) for the SBG customers:
2/5
- pCS in SBG: We hope to restore the pCS cluster in SBG next week. The servers are in SBG1 + SBG3. We may have some bad news, this is why the final status has to be confirmed in the next days.
2/5
- pCS in SBG: We hope to restore the pCS cluster in SBG next week. The servers are in SBG1 + SBG3. We may have some bad news, this is why the final status has to be confirmed in the next days.
State of Backup Service (Free or Paid) for the SBG customers:
3/5
- Paid Backup VPS & PCI: 80% of the data are on pCS in SBG. please read the previous tweet about the state of pCS in SBG. 20% of the data was on pCA which was in SBG2.
3/5
- Paid Backup VPS & PCI: 80% of the data are on pCS in SBG. please read the previous tweet about the state of pCS in SBG. 20% of the data was on pCA which was in SBG2.
State of Backup Service (Free or Paid) for the SBG customers:
4/5
- Free/Paid Backup pCC in SBG1 was hosted in an separated room of SBG1. Both rooms are destroyed.
- Free/Paid Backup pCC in SBG3: all datas seems to be safe.
4/5
- Free/Paid Backup pCC in SBG1 was hosted in an separated room of SBG1. Both rooms are destroyed.
- Free/Paid Backup pCC in SBG3: all datas seems to be safe.
State of Backup Service (Free or Paid) for the SBG customers:
5/5
We recommand to restart the service in our other DC (RBX or GRA). Free months will be applied asap.
5/5
We recommand to restart the service in our other DC (RBX or GRA). Free months will be applied asap.
Update March,13 / 3:30am
Last emails are in the process to be sent to all customers, with the current information, about the state of the primaire data and the backup (if the service was subscribed) for Baremetal, Public Cloud (pCI pCS pCA K8S..), Hosted Private Cloud (pCC),NAS..
Last emails are in the process to be sent to all customers, with the current information, about the state of the primaire data and the backup (if the service was subscribed) for Baremetal, Public Cloud (pCI pCS pCA K8S..), Hosted Private Cloud (pCC),NAS..
Update March, 13 / 3pm
We are creating a page for
- the services hosted in SBG
- the service backups (FTP Backup, VPS Automated Backup, VPS Snapshot SSD/Cloud, Instance Backup/Snapshot, Volume Snapshot/Backup)
- the internal backup
- the state of the backups
- next steps / ETA
We are creating a page for
- the services hosted in SBG
- the service backups (FTP Backup, VPS Automated Backup, VPS Snapshot SSD/Cloud, Instance Backup/Snapshot, Volume Snapshot/Backup)
- the internal backup
- the state of the backups
- next steps / ETA
Update March 14, 1pm
1/3
Still working on restarting of the A optical network in SBG1. We hope to have the network A UP today. It will allow us to redeploy the internal tools locally.
Reconstruction of the B optical network will take 2 days. Lot of fibers have to connected.
1/3
Still working on restarting of the A optical network in SBG1. We hope to have the network A UP today. It will allow us to redeploy the internal tools locally.
Reconstruction of the B optical network will take 2 days. Lot of fibers have to connected.
Update March 14, 1pm
2/3
240V in SBG1 is ready to be tested. Tomorrow 20KV for SBG1 will be UP.
The 20KV is SBG3 is in progress. 2 days.
Watercooling SBG1/3/4 checked and protected.
Cleaning and drying are in progress.
2/3
240V in SBG1 is ready to be tested. Tomorrow 20KV for SBG1 will be UP.
The 20KV is SBG3 is in progress. 2 days.
Watercooling SBG1/3/4 checked and protected.
Cleaning and drying are in progress.
Update March 14, 1pm
3/3
60 tech work on the site. Still lot of to do, but it’s going faster that expected. We keep the same ETA and maybe we will be faster.
A webpage with the final state of:
- primary data
- internal backup (not contractual)
- service backup
is in progress.
3/3
60 tech work on the site. Still lot of to do, but it’s going faster that expected. We keep the same ETA and maybe we will be faster.
A webpage with the final state of:
- primary data
- internal backup (not contractual)
- service backup
is in progress.
Update March,15 0:30am
Here, the URL with
- the state of the each service in each DC
- the state of our Internal Backup (no contractual)
- the state of the Service Backup (if cust took the service)
EN:
ovhcloud.com/en/lp/status-s…
FR:
ovhcloud.com/fr/lp/status-s…
Here, the URL with
- the state of the each service in each DC
- the state of our Internal Backup (no contractual)
- the state of the Service Backup (if cust took the service)
EN:
ovhcloud.com/en/lp/status-s…
FR:
ovhcloud.com/fr/lp/status-s…
Update March,15 / 1pm
1/5
Power:
- 20KV in SBG1 is UP. 240V is UP.
- We are restarting UPS3 for the network room A (SBG1).
- We are working on UPS2+UPS4 for SBG4
1/5
Power:
- 20KV in SBG1 is UP. 240V is UP.
- We are restarting UPS3 for the network room A (SBG1).
- We are working on UPS2+UPS4 for SBG4
Update March,15 / 1pm
2/5
Power:
- still working on 20KV in SBG3. Will be UP tomorrow.
- check of the UPS in SBG3 has started
2/5
Power:
- still working on 20KV in SBG3. Will be UP tomorrow.
- check of the UPS in SBG3 has started
Update March,15 / 1pm
3/5
Network:
- fibers Room A<>B ongoing
- fibers Room A<>SBG1/SBG4 will be started asap
- fibers Room A<>SBG3 Floor 1/2/3/4/5 ongoing
- fibers Room B<>SBG3 Floor 1/2/3/4/5 ongoing
3/5
Network:
- fibers Room A<>B ongoing
- fibers Room A<>SBG1/SBG4 will be started asap
- fibers Room A<>SBG3 Floor 1/2/3/4/5 ongoing
- fibers Room B<>SBG3 Floor 1/2/3/4/5 ongoing
Update March,15 / 1pm
4/5
Network:
- Optical network FRA<>SBG is UP
- Optical network PAR<>SBG is ongoing
- Routers in Network A are UP
- Routers in Network B are there. waiting for power.
4/5
Network:
- Optical network FRA<>SBG is UP
- Optical network PAR<>SBG is ongoing
- Routers in Network A are UP
- Routers in Network B are there. waiting for power.
Update March,15 / 1pm
5/5
Restarting of the servers
- the servers in some rooms have to be cleaned up because of the smoke: at least SBG3/Floor4+5, SBG1/61E+62E
- all others servers have to be inspected for the pollution risks
- check of the watercooling and then we start booting
5/5
Restarting of the servers
- the servers in some rooms have to be cleaned up because of the smoke: at least SBG3/Floor4+5, SBG1/61E+62E
- all others servers have to be inspected for the pollution risks
- check of the watercooling and then we start booting
Update March,17 1pm
1/4
Power SBG1/3/4:
20KV: OK
Tranfo: OK
TGBT: OK
UPS: OK
Fuses: OK
Go ! :)
Network:
We restarted the network in SBG3. We need to rebuild a part of the internal network destroyed in SBG2.
We restarted first rack in SBG1. It works fine. We will continue.
1/4
Power SBG1/3/4:
20KV: OK
Tranfo: OK
TGBT: OK
UPS: OK
Fuses: OK
Go ! :)
Network:
We restarted the network in SBG3. We need to rebuild a part of the internal network destroyed in SBG2.
We restarted first rack in SBG1. It works fine. We will continue.
Update March,17 1pm
2/4
Clean up of the servers:
We tested the servers in SBG3 : 1/3 of them have to be clean up. 2/3 can be restarted asap.
Cleaning up processus takes 12-16H per server. We will execute it on all 5 floors, in parallel. The tests start now.
2/4
Clean up of the servers:
We tested the servers in SBG3 : 1/3 of them have to be clean up. 2/3 can be restarted asap.
Cleaning up processus takes 12-16H per server. We will execute it on all 5 floors, in parallel. The tests start now.
Update March,17 1pm
3/4
We need to work on the network in SBG4.
We are looking for a special process to clean up the servers in SBG1/61E-62E. Some servers in SBG3/Floor 5 have the same issue.
3/4
We need to work on the network in SBG4.
We are looking for a special process to clean up the servers in SBG1/61E-62E. Some servers in SBG3/Floor 5 have the same issue.
Update March,17 1pm
4/4
To restart pCC/HPC, we need the pCC-Master that manages the vSphere. 1/3 are there, 2/3 have to be rebuilt. It’s a long process that we are looking to accelerate.
To restart OpenStack, we need to rebuild OS’s control plane : <24H.
4/4
To restart pCC/HPC, we need the pCC-Master that manages the vSphere. 1/3 are there, 2/3 have to be rebuilt. It’s a long process that we are looking to accelerate.
To restart OpenStack, we need to rebuild OS’s control plane : <24H.
Update March,17 4:30pm
First rack with the cust’ servers is UP !
First rack with the cust’ servers is UP !
Update March,17 11:30pm
Few racks are UP.
Few racks are UP.

Update March,18 2am
23 racks (5%) are UP
23 racks (5%) are UP
Update March,18 / 9am
Yesterday, we tested the process of the restart of the racks with a small-agile team. Today, we are starting to ramp up with more people on the site. People 24/24. Tomorrow, we will be at full speed.
Today we are testing the clean up the process in SBG3
Yesterday, we tested the process of the restart of the racks with a small-agile team. Today, we are starting to ramp up with more people on the site. People 24/24. Tomorrow, we will be at full speed.
Today we are testing the clean up the process in SBG3
Update March,18 / 12am
All network is setup in SBG4. The racks are restarting.
All network is setup in SBG4. The racks are restarting.

Update March,18 / 1pm
SBG4
today we restart the network. first step. Tomorrow, we will finish the work on the power in SBG4 then we will start restarting the servers.
SBG4
today we restart the network. first step. Tomorrow, we will finish the work on the power in SBG4 then we will start restarting the servers.
Update March,18 / 2pm
SBG1/61E,62E
Disk, CPU, RAM works well, but we need to remplace the motherboard of all servers. To do that quickly, we will change all of them to just 1 standard motherboard with Atom and allow the custom to get & to migrate the data to an another server.
SBG1/61E,62E
Disk, CPU, RAM works well, but we need to remplace the motherboard of all servers. To do that quickly, we will change all of them to just 1 standard motherboard with Atom and allow the custom to get & to migrate the data to an another server.
Update March,18 9:30pm
First ETA for each service. Will be improved, but it gives first idea.
EN:
ovhcloud.com/en/lp/status-s…
FR:
ovhcloud.com/fr/lp/status-s…
First ETA for each service. Will be improved, but it gives first idea.
EN:
ovhcloud.com/en/lp/status-s…
FR:
ovhcloud.com/fr/lp/status-s…
Update March,15 10:30pm
SBG4:
all servers are UP.
SBG4:
all servers are UP.
Update March,19 7:30pm
We shutdown SBG1+SBG4. We need verify SBG1.
We shutdown SBG1+SBG4. We need verify SBG1.
Update March,19 8:30pm
We keep SBG1+SBG4 down this night. We will restart it tomorrow afternoon.
We keep SBG1+SBG4 down this night. We will restart it tomorrow afternoon.
Update March,15 9pm
We had the smoke in an unused room in SBG1. We shutdown SBG1+SBG4 & we called the firefighters to identify the root cause. The firefighter stopped the smoke which came from the batteries that we don’t use. More info tomorrow. We stop the operation this night.
We had the smoke in an unused room in SBG1. We shutdown SBG1+SBG4 & we called the firefighters to identify the root cause. The firefighter stopped the smoke which came from the batteries that we don’t use. More info tomorrow. We stop the operation this night.
Update March,19 9:30pm
The batteries were in unused room, not used, not connected. We didn’t have the fire, but we had lot of smoke. The situation is under control now. Everybody is safe.
We stop the operation in SBG for this night. We will take the decision tomorrow.
The batteries were in unused room, not used, not connected. We didn’t have the fire, but we had lot of smoke. The situation is under control now. Everybody is safe.
We stop the operation in SBG for this night. We will take the decision tomorrow.
Update March,19 10pm
The unused room with the unused batteries was in SBG1 in front of SBG2. The fire in SBG2 has probably damaged the batteries but the smoke started only 10 days after ..
Tomorrow, we start removing everything that is not needed on the site.
The unused room with the unused batteries was in SBG1 in front of SBG2. The fire in SBG2 has probably damaged the batteries but the smoke started only 10 days after ..
Tomorrow, we start removing everything that is not needed on the site.
Update March,19 11pm
Sorry for french.
Juste pour redire ce que j’ai déjà écrit.
ovh.com/fr/news/presse…
Sorry for french.
Juste pour redire ce que j’ai déjà écrit.
ovh.com/fr/news/presse…
Update March,20 10:30am
SBG1/SBG4:
We don’t plan to restart SBG1 today. We want to remove all what is not needed. In parallel, we are working on the optional plan to move physically the servers from SBG1/4 to RBX.
SBG3:
We are restarting the operations in 1 hour.
SBG1/SBG4:
We don’t plan to restart SBG1 today. We want to remove all what is not needed. In parallel, we are working on the optional plan to move physically the servers from SBG1/4 to RBX.
SBG3:
We are restarting the operations in 1 hour.
Update March,20 3pm
1/2
SBG1:
We don’t plan to restart SBG1. Ever.
Servers in 61A/D+62A/D will be moved to SBG4.
Servers in 61E/62E will be moved to Croix and clean up then restart in RBX/GRA.
SBG4:
working on the power + the network from SBG3. Then we restart SBG4.
1/2
SBG1:
We don’t plan to restart SBG1. Ever.
Servers in 61A/D+62A/D will be moved to SBG4.
Servers in 61E/62E will be moved to Croix and clean up then restart in RBX/GRA.
SBG4:
working on the power + the network from SBG3. Then we restart SBG4.
Update March,20 3pm
2/2
SBG3:
60 tech works in the DC. we clean up the servers & we restart.
All the authorities (firefighters, préfet, police, insurances, experts, etc) are very supportive and understand the importance of restarting DCs. Everybody is doing the best. Thanks !
2/2
SBG3:
60 tech works in the DC. we clean up the servers & we restart.
All the authorities (firefighters, préfet, police, insurances, experts, etc) are very supportive and understand the importance of restarting DCs. Everybody is doing the best. Thanks !
Update March,20 6pm
SBG3:
More racks are UP. 60 simu tech working in SBG3. 24/24. 2 companies, expert in cleaning the servers after the fire, helping us.
SBG4:
A new power cable will be connected from SBG3 to SBG4.
SBG1:
working on plan to move the servers to RBX/GRA + SBG4.
SBG3:
More racks are UP. 60 simu tech working in SBG3. 24/24. 2 companies, expert in cleaning the servers after the fire, helping us.
SBG4:
A new power cable will be connected from SBG3 to SBG4.
SBG1:
working on plan to move the servers to RBX/GRA + SBG4.

Update March,21 9:30am
SBG3:
40% of VPS are UP. Working hard 24/24 to restart the remain’s VPS. Working on pCS where we store the SBG2 backup service for VPS.
SBG4:
We need 3 days to dig & connect power from SBG4 to SBG3.
SBG1:
Building / moving a new A network room in SBG5.
SBG3:
40% of VPS are UP. Working hard 24/24 to restart the remain’s VPS. Working on pCS where we store the SBG2 backup service for VPS.
SBG4:
We need 3 days to dig & connect power from SBG4 to SBG3.
SBG1:
Building / moving a new A network room in SBG5.


Update March,21 10:30pm
SBG3:
pCI: 60% of VPS: UP. 100% CEPH: UP. We continue to clean up pCS data + metadata.
pCC: clean up. tomorrow we hope to restart 40%.
BM: 25% UP
SBG4:
ETA: Wed,24
SBG1:
61AD/62AD in SBG4: Fri,26/Sun,28
61E/62E in RBX/GRA: no ETA yet because clean up.
SBG3:
pCI: 60% of VPS: UP. 100% CEPH: UP. We continue to clean up pCS data + metadata.
pCC: clean up. tomorrow we hope to restart 40%.
BM: 25% UP
SBG4:
ETA: Wed,24
SBG1:
61AD/62AD in SBG4: Fri,26/Sun,28
61E/62E in RBX/GRA: no ETA yet because clean up.

Update March,22 1pm
SBG3:
OS:
VPS host 79% UP
VPS VM 72% UP
PCI host 86% UP
API for your pCI is open at 6pm (once the vRack is UP)
pCC/HPC: We start booting the VMs today.
BM: 50% UP
SBG4:
ETA: Wed,24
SBG1:
61AD/62AD in SBG4: Fri,26/Sun,28
61E/62E in RBX/GRA: from Fri,26
SBG3:
OS:
VPS host 79% UP
VPS VM 72% UP
PCI host 86% UP
API for your pCI is open at 6pm (once the vRack is UP)
pCC/HPC: We start booting the VMs today.
BM: 50% UP
SBG4:
ETA: Wed,24
SBG1:
61AD/62AD in SBG4: Fri,26/Sun,28
61E/62E in RBX/GRA: from Fri,26

Update March,23 2pm
1/2
SBG4:
The servers will be UP by tomorrow.
SBG1:
Tomorrow we started to move SBG1 61AD-62AD to SBG4. 2-3 days of work.
All 61E are moved to Croix. 62E today. A long clean up process is starting. First ETA: 20 people = 10 days. We are working to reduce it
1/2
SBG4:
The servers will be UP by tomorrow.
SBG1:
Tomorrow we started to move SBG1 61AD-62AD to SBG4. 2-3 days of work.
All 61E are moved to Croix. 62E today. A long clean up process is starting. First ETA: 20 people = 10 days. We are working to reduce it
Update March,23 2pm
2/2
All easy racks are UP. The remains racks are in the process to be cleaned up. 80 people work just on clean up !!
I will give you later more details about specificity pCI pCC and BM. Because of the cleaning process, it’s hard to have the ETA.
2/2
All easy racks are UP. The remains racks are in the process to be cleaned up. 80 people work just on clean up !!
I will give you later more details about specificity pCI pCC and BM. Because of the cleaning process, it’s hard to have the ETA.
Update March,23 2pm
3/3
vRack in SBG3:
pCC:
Today we are rebuilding the gateway vRack. then the team will resetup the vRack in the Area & between the Areas/DCs.
Baremetal
we are rebuilding 1 of 4 gateway from BM today. The last part of the vRack will be UP.
pCI
All UP.
3/3
vRack in SBG3:
pCC:
Today we are rebuilding the gateway vRack. then the team will resetup the vRack in the Area & between the Areas/DCs.
Baremetal
we are rebuilding 1 of 4 gateway from BM today. The last part of the vRack will be UP.
pCI
All UP.
Update March,24 10pm
pCS: we hope have all the servers cleaned and UP by Friday. We need 24h to restart the whole cluster and resync some data. Then we will give the RO access to pCS on Saturday. Full RW from Sunday. Can be faster.
pCS: we hope have all the servers cleaned and UP by Friday. We need 24h to restart the whole cluster and resync some data. Then we will give the RO access to pCS on Saturday. Full RW from Sunday. Can be faster.
Update March,24 3pm
SBG4:
We are restarting the DC. Also, we started to move the servers from SBG1 61AD/62AD
SBG4:
We are restarting the DC. Also, we started to move the servers from SBG1 61AD/62AD
Update March,24 6:30pm
The cleaning takes time. We have 80 people (SBG3) + 20 people (Croix). On the left, a motherboard with the smoke pollution on the CPU socket. It’s very corrosive ! If we power up, it’s dead. Same the disk. On the right, the same device 24h after cleaned up
The cleaning takes time. We have 80 people (SBG3) + 20 people (Croix). On the left, a motherboard with the smoke pollution on the CPU socket. It’s very corrosive ! If we power up, it’s dead. Same the disk. On the right, the same device 24h after cleaned up


Update March,25 10:30am
pCS:
Metadata:
We cleaned up with success enough disks for the metadata. Now we are able to rebuild the rings. Photo: before vs after.
Data:
We have 20% of data with just 1 copy. First we rebuild the redundancy of data. Then, we give RO access. Then RW.
pCS:
Metadata:
We cleaned up with success enough disks for the metadata. Now we are able to rebuild the rings. Photo: before vs after.
Data:
We have 20% of data with just 1 copy. First we rebuild the redundancy of data. Then, we give RO access. Then RW.


Update March,26 7am
1/6
SBG4:
all servers in SBG4 are UP again. Now, we started to move the servers from SBG1 to SBG4. That is why, you will see green flashing in SBG4, like on that video:
1/6
SBG4:
all servers in SBG4 are UP again. Now, we started to move the servers from SBG1 to SBG4. That is why, you will see green flashing in SBG4, like on that video:
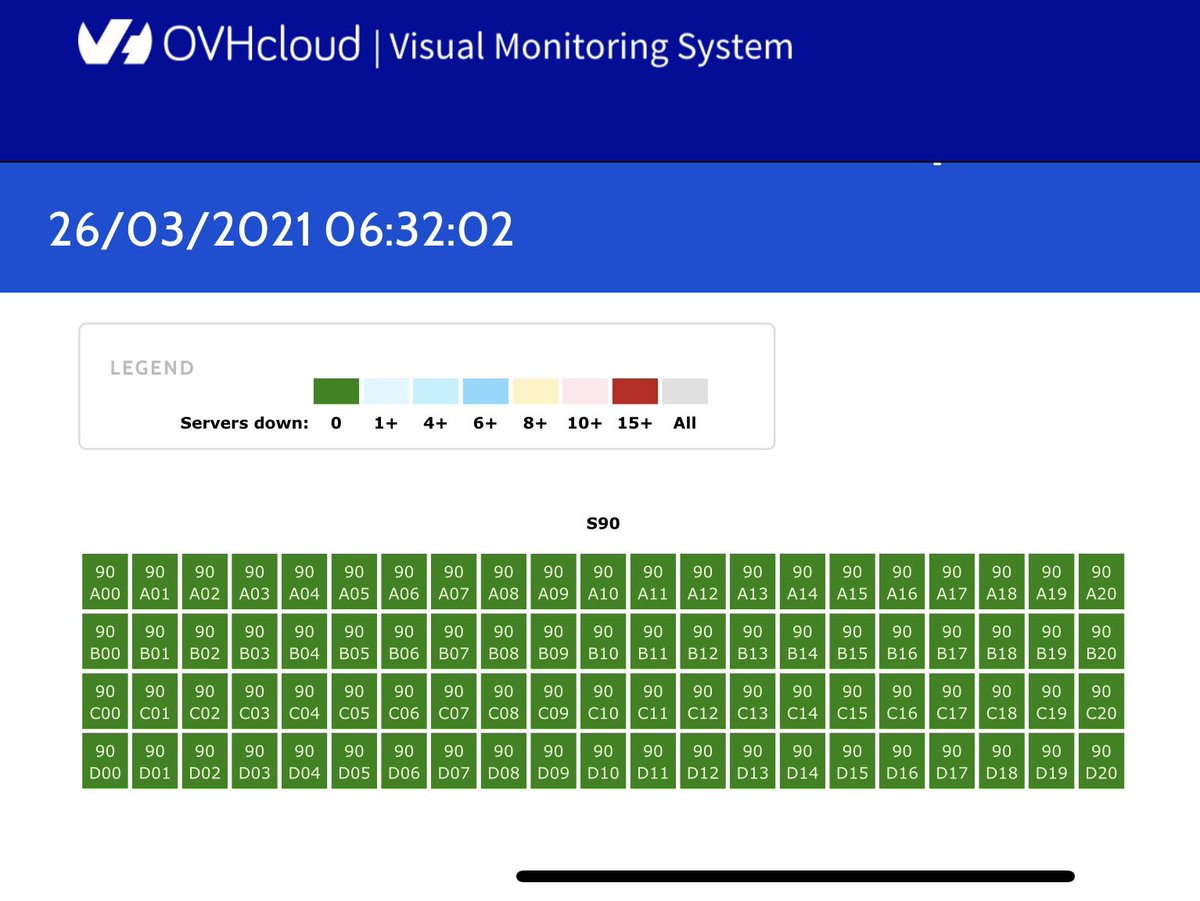
Update March,26 7am
226
SBG3:
We are cleaning up.
As soon as we have a rack UP, the team start working on the servers then on the services. We are working on the ETA per rack but honestly it’s complexe to get one that we are sure to respect because of the cleaning process.
226
SBG3:
We are cleaning up.
As soon as we have a rack UP, the team start working on the servers then on the services. We are working on the ETA per rack but honestly it’s complexe to get one that we are sure to respect because of the cleaning process.

Update March,26 7am
3/6
SBG3:
pCC/HPC:
Restarting is ongoing. It was 20 cust / day. Now it’s 20 cust / 3h. It’s still too slow. We need clear ETA. We add new racks in SBG3 to deliver all cust. Some custs just want data since they moved to RBX. Lot of differents cases ..
3/6
SBG3:
pCC/HPC:
Restarting is ongoing. It was 20 cust / day. Now it’s 20 cust / 3h. It’s still too slow. We need clear ETA. We add new racks in SBG3 to deliver all cust. Some custs just want data since they moved to RBX. Lot of differents cases ..
Update March,26 7am
4/6
OS:
pCS:
We added missed servers in the cluster and we started to copy data to get 3 copies of each data. We hope it will be done today. Anyway, asap it’s done, we put the cluster in RO and we start rebuilding 30% of SBG2 VPS from paid backup.
4/6
OS:
pCS:
We added missed servers in the cluster and we started to copy data to get 3 copies of each data. We hope it will be done today. Anyway, asap it’s done, we put the cluster in RO and we start rebuilding 30% of SBG2 VPS from paid backup.
Update March,26 7am
5/6
We are cleaning up the remains racks in SBG3 of the servers with the VPS. The same with pCI. Not yet clear ETA.
5/6
We are cleaning up the remains racks in SBG3 of the servers with the VPS. The same with pCI. Not yet clear ETA.
Update March,26 7am
6/6
The servers SBG1 61E/62E are in the cleaning up process. The speed is 3 racks per day. We have 32 racks. We are looking how to speed up it. Some racks have already been shipped back to DC.
Last step of the process is detecting remains «chlorure».
6/6
The servers SBG1 61E/62E are in the cleaning up process. The speed is 3 racks per day. We have 32 racks. We are looking how to speed up it. Some racks have already been shipped back to DC.
Last step of the process is detecting remains «chlorure».




Update March,27 9am
1/3
SBG3
Cleaning up of all servers in PROD will be done by Tue.
pCS:
We didn’t get the last servers to rebuild the cluster. It’s ongoing but it takes more time that expected to rerack servers after cleaning up. The new ETA for RO is Mon-Tue.
1/3
SBG3
Cleaning up of all servers in PROD will be done by Tue.
pCS:
We didn’t get the last servers to rebuild the cluster. It’s ongoing but it takes more time that expected to rerack servers after cleaning up. The new ETA for RO is Mon-Tue.
Update March,27 9am
2/3
VPS
We are reracking the servers after cleaning up. It’s slow. 90% by Sun
BM
Same. 85% by Sun
pCC
We just restart 30 custs per day since we need all the services UP (host, storage) to restart the vSphere. Also we copy data for cust who restarted in RBX
2/3
VPS
We are reracking the servers after cleaning up. It’s slow. 90% by Sun
BM
Same. 85% by Sun
pCC
We just restart 30 custs per day since we need all the services UP (host, storage) to restart the vSphere. Also we copy data for cust who restarted in RBX
Update March,27 9am
SBG1/AD to SBG4
will be done by Tue
SBG1/E to Croix
Cleaning up will be de by Tue. All servers will be in the DC by Tue/Wed. Then it will be powered up & restart the network. Servers will be UP by Tue - Fri.
SBG1/AD to SBG4
will be done by Tue
SBG1/E to Croix
Cleaning up will be de by Tue. All servers will be in the DC by Tue/Wed. Then it will be powered up & restart the network. Servers will be UP by Tue - Fri.
Update 28, 10am
1/3
pCS:
We finished to duplicate the « 1-copy-data ». We are racking last 2 racks of servers with few PB of disk and we are ready to restart.
vRack:
the servers which are UP but have vRack down: we need to double-checking the cables & the setup.
1/3
pCS:
We finished to duplicate the « 1-copy-data ». We are racking last 2 racks of servers with few PB of disk and we are ready to restart.
vRack:
the servers which are UP but have vRack down: we need to double-checking the cables & the setup.
Update 28, 10am
2/3
Racking back the servers takes more time that expected. Going too fast, made us too many mistakes. Sometimes we had to unrack servers and rack them again.
Now, we have the right process but it takes more time. Much more. We are looking how to reduce the ETA
2/3
Racking back the servers takes more time that expected. Going too fast, made us too many mistakes. Sometimes we had to unrack servers and rack them again.
Now, we have the right process but it takes more time. Much more. We are looking how to reduce the ETA
Update 28, 10am
3/4
Full recovery of pCC/HPC is slow since we need to assemble all the services (which are in 100 racks/3 floors) for each customer. It looks like we assemble hundreds puzzles of 6-12 pieces with some pieces unavailable since some racks are cleaning up.
3/4
Full recovery of pCC/HPC is slow since we need to assemble all the services (which are in 100 racks/3 floors) for each customer. It looks like we assemble hundreds puzzles of 6-12 pieces with some pieces unavailable since some racks are cleaning up.
Update 28, 10am
4/4
SBG3/Floor 5 is a new floor with only new servers ready for a launch of new product we planned in .. 10 days. We’ve been working on for 18 months and now all has to be cleaned up
But first we focus on all cust’s services to make them UP.
We are on it !
4/4
SBG3/Floor 5 is a new floor with only new servers ready for a launch of new product we planned in .. 10 days. We’ve been working on for 18 months and now all has to be cleaned up
But first we focus on all cust’s services to make them UP.
We are on it !
Update March,29 11pm
Here, the current status. We are facing lot of blockers and the unpredictable issues that should have been fixed but are not yet. Exemple: the elevator in SBG3 is not fixed yet. Consequence: we have to use the stairway for all servers coming from Croix 1by1.
Here, the current status. We are facing lot of blockers and the unpredictable issues that should have been fixed but are not yet. Exemple: the elevator in SBG3 is not fixed yet. Consequence: we have to use the stairway for all servers coming from Croix 1by1.
https://twitter.com/OVHcloud_FR/status/1376607236294905859
Update March, 29 11:30pm
pCS is UP in RO.
On our side, we are working on restarting of the SBG2’s VPS from the paid backup. We are working on the code and then we will start. Probably from tomorrow.
pCS is UP in RO.
On our side, we are working on restarting of the SBG2’s VPS from the paid backup. We are working on the code and then we will start. Probably from tomorrow.
Update March,30 10:30pm
1/2
We started to rebuild the VPS from the paid backup SBG2. We are still working on the code improvement to speed up.
Also, we are working on the restart of all the SBG2’s VPS / PCI in GRA. Same IP. Some image (debian, ubuntu, windows, ..).
1/2
We started to rebuild the VPS from the paid backup SBG2. We are still working on the code improvement to speed up.
Also, we are working on the restart of all the SBG2’s VPS / PCI in GRA. Same IP. Some image (debian, ubuntu, windows, ..).
Update March,30 10:30pm
Still working hard to restart all BM in SBG3, with the vRack UP. Lot of work but it’s going faster now.
SBG1/E > Croix > SBG3: tomorrow all the servers will be cleaned up and shipped to DC.
SBG1/AD > SBG4: lot of work, but step by step we will get there
Still working hard to restart all BM in SBG3, with the vRack UP. Lot of work but it’s going faster now.
SBG1/E > Croix > SBG3: tomorrow all the servers will be cleaned up and shipped to DC.
SBG1/AD > SBG4: lot of work, but step by step we will get there
Update March,30 10:30pm
We accelerated the restart of pCC. It’s still not fast enough, but in 48H we will have all racks UP. Then it will be faster.
Lot of cust restarted in RBX and ask us to move data. We added 400Gbps encrypted network to accelerate the migrations of data.
We accelerated the restart of pCC. It’s still not fast enough, but in 48H we will have all racks UP. Then it will be faster.
Lot of cust restarted in RBX and ask us to move data. We added 400Gbps encrypted network to accelerate the migrations of data.
Update March,30 10:30pm
4/4
We delivered > 7K servers. Still 3K in the backlog. Everyday we add 450-500 servers. 5-10 days ? depends on the type of the server.
Also, we plan to deliver in GRA+RBX all the remains services that was destroyed in SBG2 and apply 6m for free.
4/4
We delivered > 7K servers. Still 3K in the backlog. Everyday we add 450-500 servers. 5-10 days ? depends on the type of the server.
Also, we plan to deliver in GRA+RBX all the remains services that was destroyed in SBG2 and apply 6m for free.
Update March,31 1:30pm
We started to refund all the services SBG(1/2/3/4) for March. It’s the very first step. We won’t charge all the services SBG(3/4) in April.
Please be patient. We will deal with all more complex cases as soon as possible. Just need to go step by step. thx!
We started to refund all the services SBG(1/2/3/4) for March. It’s the very first step. We won’t charge all the services SBG(3/4) in April.
Please be patient. We will deal with all more complex cases as soon as possible. Just need to go step by step. thx!
Update March,31 6pm
1/2
pCS is in RW. This evening the cust will be able to rebuild the pCI projets from the paid backup. Also, we have all racks UP for VM and we start soon to rebuild the VPS from the paid backup.
1/2
pCS is in RW. This evening the cust will be able to rebuild the pCI projets from the paid backup. Also, we have all racks UP for VM and we start soon to rebuild the VPS from the paid backup.
Update March,31 6pm
2/2
We still have 3 racks down in SBG3 for BM but we expect to have them up by tomorrow. Then, all servers for BM in SBG3 will be UP.
70% of the vRack is UP. We are working on the code to activate the remains 30% asap.
2/2
We still have 3 racks down in SBG3 for BM but we expect to have them up by tomorrow. Then, all servers for BM in SBG3 will be UP.
70% of the vRack is UP. We are working on the code to activate the remains 30% asap.
Update March,31 9:30pm
1/2
pCS
0.5% of the servers were destroyed. we checked and rebuilt data, but we can’t recover all data. There is small part, we don’t have 3 copies since the 3 copies were on 0.5% servers
It means, for the paid backup, we have 18251 backups on 19486.
1/2
pCS
0.5% of the servers were destroyed. we checked and rebuilt data, but we can’t recover all data. There is small part, we don’t have 3 copies since the 3 copies were on 0.5% servers
It means, for the paid backup, we have 18251 backups on 19486.
Update March,31 9:30pm
2/2
On 1235 backups on 19486 backups, 6%, a small part of the file isn’t there. Since all files are encrypted, we can’t partially rebuild 1235 backup with the data we have. We continue to check, but .. :/
All 18251 backups (VPS / PCI) are in progress.
2/2
On 1235 backups on 19486 backups, 6%, a small part of the file isn’t there. Since all files are encrypted, we can’t partially rebuild 1235 backup with the data we have. We continue to check, but .. :/
All 18251 backups (VPS / PCI) are in progress.
Update April,1 7am
We have an issue on the UPS UPS11T3 in SBG3. We shutdown it down.
We have an issue on the UPS UPS11T3 in SBG3. We shutdown it down.
Update April,1 7:15am
1/2
In the SBG3 we have the security guard walking and checking if everything is okey. This morning at 6am, they felt something strange in the air and found out it’s coming from UPS11T3. We immediately bypass/shutdown the UPS and we called the firefighter
1/2
In the SBG3 we have the security guard walking and checking if everything is okey. This morning at 6am, they felt something strange in the air and found out it’s coming from UPS11T3. We immediately bypass/shutdown the UPS and we called the firefighter
Update April,1 7:15am
2/2
The firefighters came and checked the temp everywhere: no smoke, no fire. They left the site.
On the front of this UPS, we see that the small filter is burnt. I won’t give any fast conclusion.
No impact on the services.
2/2
The firefighters came and checked the temp everywhere: no smoke, no fire. They left the site.
On the front of this UPS, we see that the small filter is burnt. I won’t give any fast conclusion.
No impact on the services.
Update April,1 7:30am
The incident is over. We called the supplier to check this UPS.
The teams are back in SBG3. We continue the operations.
The incident is over. We called the supplier to check this UPS.
The teams are back in SBG3. We continue the operations.
Update April,1 5pm
pCC:
We delivered 300 hosted in SBG3 and 900 hosted in RBX, but we won’t be able to deliver more that 500 hosts in SBG3. It will be too long. That’s why we still adding new hosts in RBX and we help the custs to migrate data from SBG3 to RBX. Please contact us.
pCC:
We delivered 300 hosted in SBG3 and 900 hosted in RBX, but we won’t be able to deliver more that 500 hosts in SBG3. It will be too long. That’s why we still adding new hosts in RBX and we help the custs to migrate data from SBG3 to RBX. Please contact us.
Update April,1 7pm
BareMetal (BM):
SBG3: all is UP (except 2 racks). this evening / tomorrow morning all vRack is UP.
SBG1/AD to SBG4: started today.
SBG1/E to Croix to SBG3: shipment ongoing. will start to be UP from Monday. lot lot or complex job. we won’t give up !
BareMetal (BM):
SBG3: all is UP (except 2 racks). this evening / tomorrow morning all vRack is UP.
SBG1/AD to SBG4: started today.
SBG1/E to Croix to SBG3: shipment ongoing. will start to be UP from Monday. lot lot or complex job. we won’t give up !
Update April,2 1pm
SBG1/AD > SBG4
18% done
More details in real time:
travaux.ovh.net/?do=details&id…
SBG1/AD > SBG4
18% done
More details in real time:
travaux.ovh.net/?do=details&id…
Update April,2 5pm
SBG3 Baremetal + vRack : all racks are UP.
(all servers which are still down needs to be repaired).
SBG3 Baremetal + vRack : all racks are UP.
(all servers which are still down needs to be repaired).
Update April,3 6am
OpenStack/VPS:
All racks are UP.
5% (405/7650) VPS backup restored
100% (837/837) volumes rebuilt (from os-sbg3, imported to os-sbg7)
All customers will receive an email tomorrow afternoon with their status
OpenStack/VPS:
All racks are UP.
5% (405/7650) VPS backup restored
100% (837/837) volumes rebuilt (from os-sbg3, imported to os-sbg7)
All customers will receive an email tomorrow afternoon with their status
Update April,3 10:30am
Paid Backup VPS SBG2:
8% UP (637/7650)
We patched duplicity and we are able to recreate the disk even if a part is missed. POC works. If the case (6% of backups), we will restart the VPS with empty system + the additional disk rebuilt from the backup.
Paid Backup VPS SBG2:
8% UP (637/7650)
We patched duplicity and we are able to recreate the disk even if a part is missed. POC works. If the case (6% of backups), we will restart the VPS with empty system + the additional disk rebuilt from the backup.
Update April,3 12am
Paid Backup pCI:
18K backup are available, you can restore them if needed. if any issue, pls send me DM.
Paid Backup VPS:
7.6K backup, we restore them, same IP. 9%.
Paid Backup OS (OpenStack):
25.6K backup (18K pCI + 7.6K VPS). for 6% we patched duplicity.
Paid Backup pCI:
18K backup are available, you can restore them if needed. if any issue, pls send me DM.
Paid Backup VPS:
7.6K backup, we restore them, same IP. 9%.
Paid Backup OS (OpenStack):
25.6K backup (18K pCI + 7.6K VPS). for 6% we patched duplicity.
Update April,3 11:30pm
VPS paid backup
7.6K backup are in pCS = 3K VPS. will be restored asap. Same IP
1K VPS backup were in pCA, which is destroyed. We will restart the VPS with the new image. Same IP. We will contact all thoses custs.
6% duplicity: 400 VPS will be restored
VPS paid backup
7.6K backup are in pCS = 3K VPS. will be restored asap. Same IP
1K VPS backup were in pCA, which is destroyed. We will restart the VPS with the new image. Same IP. We will contact all thoses custs.
6% duplicity: 400 VPS will be restored
Update April,4 1:30pm
BM:
SBG1/AD to SBG4:
The migration should end by Mon. In the case that the server has an issue, it can take additional 24h/48h.
SBG1/E to Croix to SBG3:
All is cleaned. We rebuild the racks and we check the server. First racks were shipped to SBG3.
BM:
SBG1/AD to SBG4:
The migration should end by Mon. In the case that the server has an issue, it can take additional 24h/48h.
SBG1/E to Croix to SBG3:
All is cleaned. We rebuild the racks and we check the server. First racks were shipped to SBG3.
Update April,4 6pm
1/3
VPS
A) during all period when your service is not delivered, you will be refund. you’ve already got the refund for mars.
B) once your VPS is UP again:
1) if your VPS was NOT destroyed, you will get 3 mo
1/3
VPS
A) during all period when your service is not delivered, you will be refund. you’ve already got the refund for mars.
B) once your VPS is UP again:
1) if your VPS was NOT destroyed, you will get 3 mo
Update April,4 6pm
2/3
VPS
2) if your VPS was destroyed,
a) and you didn’t order the paid backup you will get 6 mo
b) and you had the paid backup + we rebuilt the VPS from the paid backup, you will get 6 mo
2/3
VPS
2) if your VPS was destroyed,
a) and you didn’t order the paid backup you will get 6 mo
b) and you had the paid backup + we rebuilt the VPS from the paid backup, you will get 6 mo
3/3
VPS
2c) and you had the paid backup but the paid backup was destroyed too (even if the paid backup was local for the purpose «humain errors» / « tech failure») we will refund all paid backup (all time) and you will get 3y for free (with new multi-dc backup we will offer)
VPS
2c) and you had the paid backup but the paid backup was destroyed too (even if the paid backup was local for the purpose «humain errors» / « tech failure») we will refund all paid backup (all time) and you will get 3y for free (with new multi-dc backup we will offer)
Update April,5 10:30am
pCC/HPC:
delivered all the hosts available in SBG3 and we added lot of lot of new resources in RBX for all others custs. ‘ve created the migration process included copy of PBs of data from SBG to RBX.
going fast but we need to talk with each cust
DM me
pCC/HPC:
delivered all the hosts available in SBG3 and we added lot of lot of new resources in RBX for all others custs. ‘ve created the migration process included copy of PBs of data from SBG to RBX.
going fast but we need to talk with each cust
DM me
Update April,5 12:30am
Croix,FR
Last week, we produced 3600 servers, 70 racks. Today, we continue to assemble new servers and working on 61E.
All team fully engaged working 6d per day, 2 shifts per day.
Here, a short video from Croix, during the launch time.
Croix,FR
Last week, we produced 3600 servers, 70 racks. Today, we continue to assemble new servers and working on 61E.
All team fully engaged working 6d per day, 2 shifts per day.
Here, a short video from Croix, during the launch time.
Update April,6 8:30pm
BM:
SBG1/E > Croix > SBG3
First 200 servers are in SBG3. We are working to connect them on Floor 5. In the same time, still checking all remains servers before sending them back to SBG.
BM:
SBG1/E > Croix > SBG3
First 200 servers are in SBG3. We are working to connect them on Floor 5. In the same time, still checking all remains servers before sending them back to SBG.

Update April,7 8am
BM
SBG1/AD > SBG4
62% (472/758 servers)
More details:
travaux.ovh.net/?do=details&id…
BM
SBG1/AD > SBG4
62% (472/758 servers)
More details:
travaux.ovh.net/?do=details&id…
Update April,8 8am
1/3
BM
SBG1/E > SBG3
30% of servers are in SBG3. we restart 1by1 rack / server (IPMI / vlan / ip / vRack)
SBG1/AD > SBG4
Almost done, except 55 servers.
SBG2+SBG1/BC > GRA
we are assembling all the servers needed to deliver all destroyed servers in GRA
1/3
BM
SBG1/E > SBG3
30% of servers are in SBG3. we restart 1by1 rack / server (IPMI / vlan / ip / vRack)
SBG1/AD > SBG4
Almost done, except 55 servers.
SBG2+SBG1/BC > GRA
we are assembling all the servers needed to deliver all destroyed servers in GRA
Update April,8 8am
2/3
VPS
The process to restart the VPS from the backup is still ongoing. Once it’s done, we will restart all the VPS without backup.
pCI
Now, you have the access to the backup and you can restart your project from the backup.
2/3
VPS
The process to restart the VPS from the backup is still ongoing. Once it’s done, we will restart all the VPS without backup.
pCI
Now, you have the access to the backup and you can restart your project from the backup.
Update April,8 8am
3/3
pCC
We are adding more resources (host/datastore) in RBX to deliver and migrate the data / workload of some cust. Please contact us, so we can deliver the right resources since new HW is more powerful (more CPU RAM Storage) that some old HW in SBG2.
3/3
pCC
We are adding more resources (host/datastore) in RBX to deliver and migrate the data / workload of some cust. Please contact us, so we can deliver the right resources since new HW is more powerful (more CPU RAM Storage) that some old HW in SBG2.
Update April, 9 12am
BM
SBG1 > Croix > SBG3/Floor 5
less that 300 servers has to be tested in Croix before the shipment to SBG3. We have more that 250 servers are UP in SBG3. step by step ..
BM
SBG1 > Croix > SBG3/Floor 5
less that 300 servers has to be tested in Croix before the shipment to SBG3. We have more that 250 servers are UP in SBG3. step by step ..

Update April, 10 10am
1/5
pCC/HPC:
The restarting / the migrations are in progress with the cust, because some custs want to consolidate their infra (thanks to the new HW).
If the cust doesn’t answer us, we restart the infra « as it was » with new HW.
Please contact us.
1/5
pCC/HPC:
The restarting / the migrations are in progress with the cust, because some custs want to consolidate their infra (thanks to the new HW).
If the cust doesn’t answer us, we restart the infra « as it was » with new HW.
Please contact us.
Update April, 10 10am
2/5
OpenStack/pCI:
We sent the last emails to the custs about the backup and the restoring process.
On Public Cloud, we are NOT allowed to restart the service. The cust has to do that, if needed.
2/5
OpenStack/pCI:
We sent the last emails to the custs about the backup and the restoring process.
On Public Cloud, we are NOT allowed to restart the service. The cust has to do that, if needed.
Update April, 10 10am
3/5
VPS:
We almost have restarted VPS from backup. We are working on 6%. Mon/Tue.
Then we will restart all remains (empty) VPS. It will take time since we need to add the HW in SBG3. Faster way is, the cust start a new VPS in GRA (but IP will change).
3/5
VPS:
We almost have restarted VPS from backup. We are working on 6%. Mon/Tue.
Then we will restart all remains (empty) VPS. It will take time since we need to add the HW in SBG3. Faster way is, the cust start a new VPS in GRA (but IP will change).
Update April, 10 10am
4/5
BM
SBG1>SBG4
done
SBG1>SBG3
It’s a nightmare .. next wk only, first server will be UP. All servers are cleaned and tested, but it takes time to reassemble the racks .. a huge tetris.
4/5
BM
SBG1>SBG4
done
SBG1>SBG3
It’s a nightmare .. next wk only, first server will be UP. All servers are cleaned and tested, but it takes time to reassemble the racks .. a huge tetris.
Update April, 10 10am
5/5
SBG2+SBG1/BC
All destroyed servers will be (re)delivered.
An email will be sent: if the cust want us to do something else, example in the case he’s already ordered an another server and he just wants to migrate IP / 6 months voucher to the new server.
5/5
SBG2+SBG1/BC
All destroyed servers will be (re)delivered.
An email will be sent: if the cust want us to do something else, example in the case he’s already ordered an another server and he just wants to migrate IP / 6 months voucher to the new server.
Update March,11 10pm
1/2
pCI
we are close to finish all the stuff on the Public Cloud. If you see the things that don’t work for you, pls DM me.
SBG1/E > Croix > SBG3 (aka nightmare)
First rack is UP.
1/2
pCI
we are close to finish all the stuff on the Public Cloud. If you see the things that don’t work for you, pls DM me.
SBG1/E > Croix > SBG3 (aka nightmare)
First rack is UP.
Update March,11 10pm
2/2
We suspended renew of all new services for all the SBG’ custs, until we send all the vouchers with free months. So they can renew / pay with the vouchers.
2/2
We suspended renew of all new services for all the SBG’ custs, until we send all the vouchers with free months. So they can renew / pay with the vouchers.
Update April,12 7pm
SBG1/E > Croix > SBG3
2 racks are UP. It’s slow. Should be faster soon. For the moment, we are working on the Floor 5. Soon the extension of Floor 3 will be ready for the additional racks from SBG1/E and we will have more people working in the same time.
SBG1/E > Croix > SBG3
2 racks are UP. It’s slow. Should be faster soon. For the moment, we are working on the Floor 5. Soon the extension of Floor 3 will be ready for the additional racks from SBG1/E and we will have more people working in the same time.

Update April,13 8am
SBG(1/2/3/4)
BM: 92% UP
VPS: 84% UP
pCI: 86% UP
pCC: 79% UP
UP: in same DC or redelivered elsewhere
Work In Progress:
BM: SBG1/E, remains SBG2 in GRA
VPS: 6%, remains SBG2 in SBG3
pCC: work with each cust 1by1, SBG2+RBX
SBG(1/2/3/4)
BM: 92% UP
VPS: 84% UP
pCI: 86% UP
pCC: 79% UP
UP: in same DC or redelivered elsewhere
Work In Progress:
BM: SBG1/E, remains SBG2 in GRA
VPS: 6%, remains SBG2 in SBG3
pCC: work with each cust 1by1, SBG2+RBX
Update April,14 9pm
SBG1/E > Croix > SBG3
new 200 servers were shipped to Floor 5 which is now full. Tomorrow, we start filling Floor 3. Step by step. Yes, it’s slow. Real nightmare.
SBG1/E > Croix > SBG3
new 200 servers were shipped to Floor 5 which is now full. Tomorrow, we start filling Floor 3. Step by step. Yes, it’s slow. Real nightmare.

Update April,14 10pm
SBG1/E > Croix > SBG3
5 racks are UP (using internal-rescue). We are coding all the scripts to detect and (re)setup the servers in the racks / vRacks. Example: sometimes eth0 is eth1, and eth1 is eth0, depends on the motherboard, the cables. Nightmare.
SBG1/E > Croix > SBG3
5 racks are UP (using internal-rescue). We are coding all the scripts to detect and (re)setup the servers in the racks / vRacks. Example: sometimes eth0 is eth1, and eth1 is eth0, depends on the motherboard, the cables. Nightmare.
Update April,15 2pm
SBG1/E > Croix > SBG3
First servers are given back to custs. Sorry for delay. It’s a real nightmare. It’s not done, still long journey but the code works. Now, we will be able to speed up :)
SBG1/E > Croix > SBG3
First servers are given back to custs. Sorry for delay. It’s a real nightmare. It’s not done, still long journey but the code works. Now, we will be able to speed up :)
Update April,17 2am
SBG global status:
BM: 98% UP
pCI: 95% UP
VPS: 95% UP
HPC/pCC: 85% UP
WIP:
BM:
SBG1/E in SBG3 (thought Croix)
SBG2 in GRA (new HW)
VPS:
SBG2 in SBG3 (need new HW)
We keep working 24/7.
SBG global status:
BM: 98% UP
pCI: 95% UP
VPS: 95% UP
HPC/pCC: 85% UP
WIP:
BM:
SBG1/E in SBG3 (thought Croix)
SBG2 in GRA (new HW)
VPS:
SBG2 in SBG3 (need new HW)
We keep working 24/7.
Update April,18 12am
BM:
SBG1/E > Croix > SBG3
- Floor 5: all servers are there and we fix the issues, rack after rack, 24/7
- Floor 3: first racks comes by Tue
VPS:
- restart SBG2 in SBG3, case « no paid backup ». new HW will be in SBG3 in 10 days
If you have a request, DM me
BM:
SBG1/E > Croix > SBG3
- Floor 5: all servers are there and we fix the issues, rack after rack, 24/7
- Floor 3: first racks comes by Tue
VPS:
- restart SBG2 in SBG3, case « no paid backup ». new HW will be in SBG3 in 10 days
If you have a request, DM me
Update April,19 11pm
SBG1/E > SBG3
If you see the rack in «green », it means all servers «ping» but it doesn’t mean «work is done». We need to restart the server in «internal rescue» then work on each server, change the setup, and test it. example: s351A03 we are still on it
SBG1/E > SBG3
If you see the rack in «green », it means all servers «ping» but it doesn’t mean «work is done». We need to restart the server in «internal rescue» then work on each server, change the setup, and test it. example: s351A03 we are still on it
Update April,20 12am
SBG1/E > SBG3
S33X: we are racking the servers in the racks. work in progress (WIP).
S35X:
100% of servers are in the racks
80% are delivered to cust (Done).
Todo: we setup the network, IPMI, vRack.
Blocked : need to be repaired
SBG1/E > SBG3
S33X: we are racking the servers in the racks. work in progress (WIP).
S35X:
100% of servers are in the racks
80% are delivered to cust (Done).
Todo: we setup the network, IPMI, vRack.
Blocked : need to be repaired

Update April,20 2pm
VPS SBG2 > SBG3
- 19% had a paid backup, are UP now
- 51% didn’t have paid backup, are UP now
Work in Progress (WIP):
- 29% no paid backup : need additional server to deliver them.
- paid backup: 0.5% restoration failed, we fix them + 0.5% backup with 6%
VPS SBG2 > SBG3
- 19% had a paid backup, are UP now
- 51% didn’t have paid backup, are UP now
Work in Progress (WIP):
- 29% no paid backup : need additional server to deliver them.
- paid backup: 0.5% restoration failed, we fix them + 0.5% backup with 6%
Update April,21 1pm
The billing is suspended for all services in SBG. It has to stay like that until we send all the vouchers.
For some reasons, we charged the custs for VPS if they pay with Credit Card or Paypal.
It’s a mistake. Sorry for that !
We fix it and charge back.
The billing is suspended for all services in SBG. It has to stay like that until we send all the vouchers.
For some reasons, we charged the custs for VPS if they pay with Credit Card or Paypal.
It’s a mistake. Sorry for that !
We fix it and charge back.
Update April,24 9am
SBG1/E > SBG3
S35X (SBG3/Floor 5): All done
S33X (SBG3/Floor 3): All serveurs are in the racks. Now, we are fixing them.
SBG1/E > SBG3
S35X (SBG3/Floor 5): All done
S33X (SBG3/Floor 3): All serveurs are in the racks. Now, we are fixing them.

Update April,26 7pm
SBG1/E > Croix > SBG3 Floor3/5.
All done.
If you have any issue, please DM me.
SBG1/E > Croix > SBG3 Floor3/5.
All done.
If you have any issue, please DM me.
Update April,30 9am
VPS:
The paid backup were hosted on pCS which had 0.5% of disk destroyed. About 6% of paid backup has at least 1 part of the backup destroyed. We «hacked» the process to rebuild the backup with missed parts and we delivered new VPS + /dev/sdb with backup.
VPS:
The paid backup were hosted on pCS which had 0.5% of disk destroyed. About 6% of paid backup has at least 1 part of the backup destroyed. We «hacked» the process to rebuild the backup with missed parts and we delivered new VPS + /dev/sdb with backup.

Update May,2 9am
An important step has been reached delivering 98% of 120K services we had in SBG. We keep working on all custom cases: cust has 2 services, which one he wants to keep, cust has the service back but he needs other HW, etc
An important step has been reached delivering 98% of 120K services we had in SBG. We keep working on all custom cases: cust has 2 services, which one he wants to keep, cust has the service back but he needs other HW, etc
Update May,2 9am
We’ve been working hard for the last 50 days to give back the services. During all this time, when the service was not DOWN, you got free month. Normal.
Once your services is UP, in the next days, you will get the voucher with free months for futur bills.
We’ve been working hard for the last 50 days to give back the services. During all this time, when the service was not DOWN, you got free month. Normal.
Once your services is UP, in the next days, you will get the voucher with free months for futur bills.
Update May,2 9am
It’s a complex task to deliver 120000 vouchers with the right amount for all custs because of the different services, cases, billings.
If you think the amount is not correct, please contact us, we will verify it.
If your service is not totally recovered, DM me.
It’s a complex task to deliver 120000 vouchers with the right amount for all custs because of the different services, cases, billings.
If you think the amount is not correct, please contact us, we will verify it.
If your service is not totally recovered, DM me.
• • •
Missing some Tweet in this thread? You can try to
force a refresh


























