New project on causal language and claims, and I want you to see how everything goes down live, to a mind-boggling level of transparency.
That includes live public links to all the major documents as they are being written, live discussion on major decisions, etc.
HERE WE GO!
That includes live public links to all the major documents as they are being written, live discussion on major decisions, etc.
HERE WE GO!
Worth noting: this is the second time I've tried this kind of public transparency; the previous paper got canned due to COVID-related things.
NEW STUDY TIME!
Here's the idea (at the moment, anyway): health research has a very complicated relationship with "causal" language.
NEW STUDY TIME!
Here's the idea (at the moment, anyway): health research has a very complicated relationship with "causal" language.
There is a semi-ubiquitous standard that if your study isn't the right method or isn't "good enough" to for causal estimation, you shouldn't use the word cause, but instead just say things are association/correlated/whatever, and you're good to go.
This is ... problematic.
This is ... problematic.
Lots of potential rants here for why, but suffice to say this standard creates all kinds of issues with study strength, communication, and usefulness. This is a problem I've been working on for years.
But how common is this, and is it a big problem?
But how common is this, and is it a big problem?
One symptom of this disconnect is that a lot of papers may make a lot of action claims about their studies that would require causal estimation, but according to the language, are "just association."
So, what do we want to know?
So, what do we want to know?
1) How do *typical* journal publications phrase the relationships between exposures and outcomes?
What actual words are used (correlate, effect on, associate, cause, etc)?
With what modifiers (may be, strongly, etc)?
How common is "just say association"?
What actual words are used (correlate, effect on, associate, cause, etc)?
With what modifiers (may be, strongly, etc)?
How common is "just say association"?
2) Do the claims and action implications made in the paper imply or require a causal estimate?
E.g. do the implications from the paper suggesting doing more, less, or the same amount of X in order to increase or decrease Y?
That's implicitly causal in nature.
E.g. do the implications from the paper suggesting doing more, less, or the same amount of X in order to increase or decrease Y?
That's implicitly causal in nature.
So, the plan:
1) Take a giant randomly selected, screened sample of X vs Y-type articles in the health literature.
2) Recruit a giant multidisciplinary team of awesome people
3) Have them determine what the phrases used and what the claims made are, based on guidance.
Easy!*
1) Take a giant randomly selected, screened sample of X vs Y-type articles in the health literature.
2) Recruit a giant multidisciplinary team of awesome people
3) Have them determine what the phrases used and what the claims made are, based on guidance.
Easy!*
* narrator: this is not easy, but at least its fun!**
** narrator: fun-ish.
First thing that needs to be done is developing a rough protocol.
My task of the day is making a messy terrible outline of what I think this should look like.
** narrator: fun-ish.
First thing that needs to be done is developing a rough protocol.
My task of the day is making a messy terrible outline of what I think this should look like.
Good news is that I've had enough proposals in this arena that I can stitch it together from scraps leftover from ~4 years of failed grant proposals and cancelled projects that this shouldn't be that hard, right?
RIGHT???
RIGHT???
Some time this afternoon, I'll open a blank document for the protocol draft, and share the link with the world, so you can watch / comment / suggest everything as I go, and can see just how terrible I am at writing.
It's gonna be great. Or something.
It's gonna be great. Or something.
And here we go!
Link to document, feel free to leave comments and whatnot any time. This will be fully open docs.google.com/document/d/1dG…
And as a bonus from now to about 5ish, I'm gonna stream it all on Twitch, come join!: twitch.tv/noahhaber
Link to document, feel free to leave comments and whatnot any time. This will be fully open docs.google.com/document/d/1dG…
And as a bonus from now to about 5ish, I'm gonna stream it all on Twitch, come join!: twitch.tv/noahhaber
Day 1: Got a decent outline of the protocol draft. Goal is to get a full shitty draft for tomorrow, and send around for potential protocol co-authors / revisions.
I want a full, presentable protocol by the end of the month, because this is going to be an aggressive timeline.
I want a full, presentable protocol by the end of the month, because this is going to be an aggressive timeline.
Bad protocol chalkboard draft #1 written and done.
Now in get-core-team-together mode, to be followed shortly by absolutely-massacre-original-draft-and-like-a-phoenix-a-decent-draft-will-be-reborn-from-the-ashes mode
docs.google.com/document/d/1dG…
Now in get-core-team-together mode, to be followed shortly by absolutely-massacre-original-draft-and-like-a-phoenix-a-decent-draft-will-be-reborn-from-the-ashes mode
docs.google.com/document/d/1dG…
Core team is now being constructed, people getting invited to collaborate.
Fun part of this is that I am under a small time crunch, since my fellowship ends August 31, with no clear employment after that.
4 month hard deadline, here we go!
Fun part of this is that I am under a small time crunch, since my fellowship ends August 31, with no clear employment after that.
4 month hard deadline, here we go!
Update: two weeks later, we have a full core team, and the protocol is well on its way.
Things, they are happening. 3.5 months to go.
docs.google.com/document/d/1dG…
Things, they are happening. 3.5 months to go.
docs.google.com/document/d/1dG…
Status update: protocol is getting close to done, protocol coauthor team finalized, reviewers are being recruited and we're having one of several intro meetings tomorrow morning.
Good thing I definitely for sure planned ahead and made slides.
docs.google.com/presentation/d…
Good thing I definitely for sure planned ahead and made slides.
docs.google.com/presentation/d…
Only thing that's not public is stuff that contains personal information; everything else is public.
Welp, things are going. Here's where we're at:
- Team recruited and on Slack
- Currently putting the final touches on the protocol
- Wrote/ran the search code
- Team divided into screeners and review tool piloters
- Meetings scheduled for the training sessions
- Team recruited and on Slack
- Currently putting the final touches on the protocol
- Wrote/ran the search code
- Team divided into screeners and review tool piloters
- Meetings scheduled for the training sessions
This is definitely a work weekend for me, lots of moving parts and administration for which I am the bottleneck.
Good news is that the team is AWESOME. Particular shout out to @SarahWieten for taking a whole bunch of responsibility (including boring stuff).
Good news is that the team is AWESOME. Particular shout out to @SarahWieten for taking a whole bunch of responsibility (including boring stuff).
@SarahWieten Relatedly, we had so much interest in this study that we had to narrow down a list of 150+ people down to a 50ish person final team.
Decisions were based on a lot of things, but notably maximimally diverse representation among qualified people.
Decisions were based on a lot of things, but notably maximimally diverse representation among qualified people.
@SarahWieten Which is to say we had to say no to a whole lot of people who are super awesome and super qualified.
If I had known how much interest there would be, possible I could have redesigned things to work with a bigger team. But alas.
If I had known how much interest there would be, possible I could have redesigned things to work with a bigger team. But alas.
@SarahWieten Hard deadline looms though. We've already used up just about the entire buffer already (granted, planning is the "high risk of delays" stage).
Doing a first-of-its-kind project with a massive team and lots of unknown unknowns is a particularly Noah style of bad idea.
Doing a first-of-its-kind project with a massive team and lots of unknown unknowns is a particularly Noah style of bad idea.
Protocol pre-registered, screening process and review tool piloting start roughly simultaneously tomorrow.
Feels like things are a touch more rushed than I would like, but so it goes. Good news: pre-registration is not a stone tablet. If we need to make changes, we'll make them.
Feels like things are a touch more rushed than I would like, but so it goes. Good news: pre-registration is not a stone tablet. If we need to make changes, we'll make them.
For whatever reason, the screening is always always always the most chaotic part of these projects.
Hiccups abounded, but screening is well underway (albeit a touch behind schedule due to said hiccups).
Main review training starts on Monday!
Hiccups abounded, but screening is well underway (albeit a touch behind schedule due to said hiccups).
Main review training starts on Monday!
One hiccup was just a straight up coding error that was my fault, but others were more about the sampling and screening design due to some unexpected interactions. Lessons learned.
Pretty much inevitable with a first-of-its-kind sortof project, but can be frustrating.
Pretty much inevitable with a first-of-its-kind sortof project, but can be frustrating.
While the screening's been going on, @SarahWieten has been leading a team to pilot the review tool and giving really incredibly helpful suggestions.
The many-commenters model is a lot of work for sure, but it absolutely makes a HUGE difference to the end product.
The many-commenters model is a lot of work for sure, but it absolutely makes a HUGE difference to the end product.
Really really looking forward to the main review phase starting (after the inevitable round of fires have been put out, of course).
I've been going nonstop on this project for a few weeks now. Will be nice to take a break.
I've been going nonstop on this project for a few weeks now. Will be nice to take a break.
Inching ever closer to launching the main review phase, currently desperately putting the final touches on a dozen things before we commit.
Side note: I think I've worked harder on this over the last few weeks than I've worked on just about anything.
Side note: I think I've worked harder on this over the last few weeks than I've worked on just about anything.
A brief recap of the last 2 weeks:
Estimated person-time for the main review alone is just a hair over 1,000 person hours between ~50 coauthor reviewers.
That's not even counting the screening and piloting process, design, admin, analysis/writing., etc.
This thing is a MONSTER.
That's not even counting the screening and piloting process, design, admin, analysis/writing., etc.
This thing is a MONSTER.
AND WE'RE OFF! Data collection has officially started for the main review.
I've been working on getting to this moment for YEARS and it's awesome to see it happening
I've been working on getting to this moment for YEARS and it's awesome to see it happening
Progress is happening
Primary review phase wraps up (ish) today! Next week is the arbitration review phase, plus a bit of extra ratings and such.
But the end of the data collection phase is in sight.
Cool.
But the end of the data collection phase is in sight.
Cool.
One side effect of this study is that a lot of extremely smart people are seeing what a reasonably representative random sample of the high-impact medical / epi journal literature actually looks like.
Reactions have been pretty interesting.
Reactions have been pretty interesting.
By request, I am doing an improvised stream of how the back end of all this works on Thursday, July 22 at 10am eastern.
How do you organize the code and interface of a complex multi-phase, 50+ person 1k+ article 3,000+ reviews study?
DM for pwd.
stanford.zoom.us/j/92540957829
How do you organize the code and interface of a complex multi-phase, 50+ person 1k+ article 3,000+ reviews study?
DM for pwd.
stanford.zoom.us/j/92540957829
Be prepared for a bizarre combination of good design and some hacky nonsense.
All code and almost* the entire file infrastructure are fully public if you want to poke around.
drive.google.com/drive/folders/…
* files containing personal info are private (some are needed for code to run)
All code and almost* the entire file infrastructure are fully public if you want to poke around.
drive.google.com/drive/folders/…
* files containing personal info are private (some are needed for code to run)
Major milestones!
1) Arbitration round reviews are wrapping up. One more piece of data collection next week and some cleanup work to do, but we're so, so close!
2) I've made an analysis coding file!
3) The manuscript is getting written!
docs.google.com/document/d/1iR…
EEEEEP!!!!
1) Arbitration round reviews are wrapping up. One more piece of data collection next week and some cleanup work to do, but we're so, so close!
2) I've made an analysis coding file!
3) The manuscript is getting written!
docs.google.com/document/d/1iR…
EEEEEP!!!!

These mega collabo projects can be monstrous, but good golly it's magical sometimes.
I was short on time to write, so I sent a quick message to the group to see if someone could handle the intro, and BOOM @dingding_peng wrote an awesome 1st draft, WAY better than I would have.
I was short on time to write, so I sent a quick message to the group to see if someone could handle the intro, and BOOM @dingding_peng wrote an awesome 1st draft, WAY better than I would have.
MAJOR MAJOR MILESTONE hit last night:
100% of article reviews completed!
Still so, so much left to do, but this is the point at which we officially have enough data to meet our primary analysis goals.
100% of article reviews completed!
Still so, so much left to do, but this is the point at which we officially have enough data to meet our primary analysis goals.

Going to reflect on a few things to getting here.
Firstly, the screening part turned out to be the most chaotic phase, and the main review went mostly fairly smoothly.
Screening is the point where you have a logistically hard proble, the least info, and untuned systems.
Firstly, the screening part turned out to be the most chaotic phase, and the main review went mostly fairly smoothly.
Screening is the point where you have a logistically hard proble, the least info, and untuned systems.
It was EXTRA chaotic due to the requirement of accepting the same number of articles per journal as a stopping, with wildly different acceptance rates per journal, with feedback loops for screener assignments.
Doing that involved a lot of pain and chaos. Do not recommend.
Doing that involved a lot of pain and chaos. Do not recommend.
I also messed up and created some extra work due to a very stupid code bug that resulted in excluding two very important journals, which was not caught until late in the process.
Fortunately, the system was built such that fixing it wasn't a huge problem. But still.
Fortunately, the system was built such that fixing it wasn't a huge problem. But still.
Then there's just the general chaos of doing a complicated and way out of ordinary project, with very unusual framing and methods, requires constant tweaking and changes, etc.
Doing something weird is always tough.
Doing something weird is always tough.
And then there's the fact that this project involves carefully coordinating, training, and synchronizing 50 (!!!) people, where everything needs to mesh at precise times and multiple phases, and any one unmeshing issue throws the whole thing out of whack.
As before, the only thing that isn't public is personal info, so I can't and won't talk about specifics.
But some tough situations arose, some unavoidable, others perhaps avoidable.
By and large though, the crew is/was ASTOUNDINGLY amazing, and my favorite part of these things.
But some tough situations arose, some unavoidable, others perhaps avoidable.
By and large though, the crew is/was ASTOUNDINGLY amazing, and my favorite part of these things.
Now we're on the cleanup phase, where there is a tough balance to be hard. I have to maintain three conflicting goals:
1) Data quality
2) Being a reasonably neutral party to avoid over-influencing reviewer decisions
and 3) Timelines
Can't get all 3 perfectly.
1) Data quality
2) Being a reasonably neutral party to avoid over-influencing reviewer decisions
and 3) Timelines
Can't get all 3 perfectly.
Have a bit more data collection to do, but the next phases are the analysis and manuscript writing phases.
And because I am me, I am going to do this the hard way, with hypertransparency engaged.
That means everyone can see all the not-so-pretty parts of the sausage making.
And because I am me, I am going to do this the hard way, with hypertransparency engaged.
That means everyone can see all the not-so-pretty parts of the sausage making.
And so, without further ado, some public links!
The manuscript is being written here (currently public comments off): docs.google.com/document/d/1iR…
The analysis code can be found in the code folder, here: drive.google.com/drive/folders/…
I know that I should be using git. Next time.
The manuscript is being written here (currently public comments off): docs.google.com/document/d/1iR…
The analysis code can be found in the code folder, here: drive.google.com/drive/folders/…
I know that I should be using git. Next time.
AHHHHH I JUST WANT TO GET TO SHARE THE RESULTS AND THE DATA WITH EVERYONEEEEEE
Final day of data collection today. The results are super super super cool.
Also reminder: everything is being done EXTREMELY openly, including the manuscript AS IT IS BEING WRITTEN.
docs.google.com/document/d/1iR…
Also reminder: everything is being done EXTREMELY openly, including the manuscript AS IT IS BEING WRITTEN.
docs.google.com/document/d/1iR…
jeez. we did this.

For a sense of scale, what you see in that chart was the work of 49 people across the world, carefully synced and coordinated, with a complex multiphase process, using a first of its kind guidance and review...
In *42 days* from first screen to last data collected.
In *42 days* from first screen to last data collected.
I am looking forward to never working this hard ever again.
But no rest yet.
Because I have 28 days left of my fellowship to get this written and submitted.
But no rest yet.
Because I have 28 days left of my fellowship to get this written and submitted.
The results section is being written, figures and statistics are being dropped, come check it out!
docs.google.com/document/d/1iR…
docs.google.com/document/d/1iR…
The "big" result and data are being dropped and written right now.
To what degree does the strength of causal implications in the sentence linking exposure to outcome match the causal implication of action recommendations (i.e. what the authors say you should *do* with the data)
To what degree does the strength of causal implications in the sentence linking exposure to outcome match the causal implication of action recommendations (i.e. what the authors say you should *do* with the data)
Nearly done writing up a first draft of the results.
Also, just drafted a nearly 2 page document detailing changes from the original protocol, of which there were many.
Doing something new and weird means running into unexpected weird problems, and plans change.
Also, just drafted a nearly 2 page document detailing changes from the original protocol, of which there were many.
Doing something new and weird means running into unexpected weird problems, and plans change.
Big one was that we ended up using a much more direct and context-sensitive measure of linking language causal strength, scrapping the original (over-complex and probably worse in every way) assignment and rating process.
Preregistration is SUPER useful, but not a stone table,
Preregistration is SUPER useful, but not a stone table,
Aaaaand first (bad) draft of the results section is written. On to the discussion section this week.
And boy howdy what a discussion section it's gonna be. I tend to think the results are pretty damning (including in some ways that surprised me).
And boy howdy what a discussion section it's gonna be. I tend to think the results are pretty damning (including in some ways that surprised me).
Now first bad draft of the Discussion!
I expect most of this to get rewritten a few times over, but the first bad draft is the hardest part.
Entering the phase where 90% of the paper is done.
docs.google.com/document/d/1iR…
I expect most of this to get rewritten a few times over, but the first bad draft is the hardest part.
Entering the phase where 90% of the paper is done.
docs.google.com/document/d/1iR…

Now uploading the final datasets and (not so final) code to the OSF repository.
Everything's always been open and accessible via Google Drive, but having it all on an open science repository is MUCH nicer and more reliable.
osf.io/jtdaz/
Thanks @OSFramework!
Everything's always been open and accessible via Google Drive, but having it all on an open science repository is MUCH nicer and more reliable.
osf.io/jtdaz/
Thanks @OSFramework!
@OSFramework I always find this stage of a paper to be tough. We know what the results are and what we want to say. The big stuff is done; we're 95% of the way there.
But there are a thousand small tasks that make up the other 95%.
But there are a thousand small tasks that make up the other 95%.
@OSFramework To make a woodworking analogy: all parts are built and more or less assembled.
Everything else from here is sanding, finishing, and getting it installed.
There's just so, so much sanding.
Everything else from here is sanding, finishing, and getting it installed.
There's just so, so much sanding.
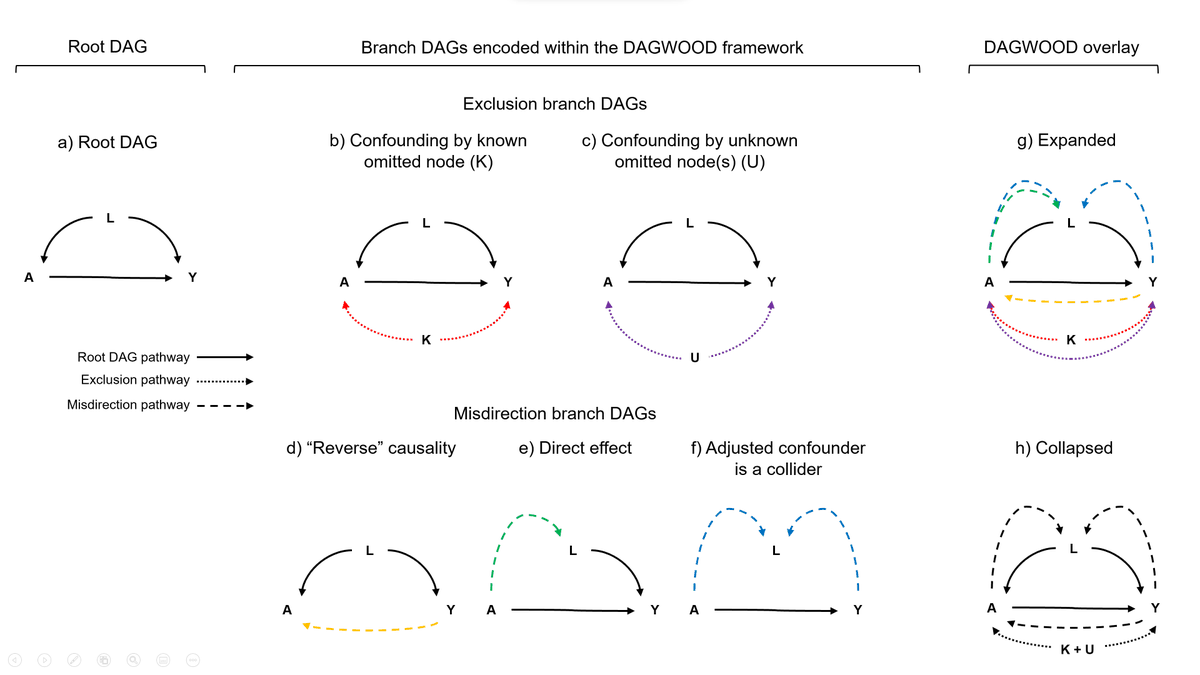
One REALLY tough thing in this paper is just how much tiptoeing we have to do for internal consistency in how we describe things.
In our case, we can't merely "just use the right words," we have to make DAMN sure that we also don't make any possible inappropriate implication.
In our case, we can't merely "just use the right words," we have to make DAMN sure that we also don't make any possible inappropriate implication.
• • •
Missing some Tweet in this thread? You can try to
force a refresh