
Well, a month and a half a go I said I would talk about the Unicode zero-width gender marker. But: it's just a teeny tiny footnote in a much larger ongoing story about Mongolian.
Commence a three-part thread that no one will read!
Commence a three-part thread that no one will read!
https://twitter.com/DHammarskjold/status/1390489759923937282
Preamble: Back in March 2020, Mongolia announced it was going to reintroduce the traditional Mongol script, which was replaced by a Cyrillic script in the 1940's. Not only that, but they plan to finish by 2025, which is not a lot of time! 

Computer support for Mongolian script was in a pretty sorry state in 2020. There have been efforts to make the script work on computers since at least the 1990's, but it has some hurdles still. Apple has just given up, it seems.

Let's talk about the Mongolian script, the hurdles to computerizing it, what's been achieved since the Mongolian government announcement, and what still needs to be done.
A lot of this info comes from the Unicode Mongolian Working Groups (unicode.org/L2/topical/mon…), the W3C Mongolian Layout Task Force (w3.org/International/…), and CJVlang (cjvlang.com)
If you're expecting a precise explanation and consistent terminology, well….don't. This will be a long Twitter thread, but it's still Twitter. I apologize if I misrepresent anything; if I'm egregiously wrong please tell one of the "Bad Linguistics" accounts
PART 1 – THE MONGOLIAN SCRIPT
If you know anything about Mongolian script, you probably know that it's written vertically. Or that it's a cursive script, like Arabic, with different initial/medial/final letterforms. (Image taken from w3c.github.io/mlreq/)
If you know anything about Mongolian script, you probably know that it's written vertically. Or that it's a cursive script, like Arabic, with different initial/medial/final letterforms. (Image taken from w3c.github.io/mlreq/)

The Mongolian script was developed in the 13th century. In 🇲🇳Mongolia, this script was replaced by Cyrillic in 1946, but millions of Mongolians living in 🇨🇳Inner Mongolia continued using it. In the 90's 🇲🇳Mongolian schools began teaching it again.
There are roughly 3 million 🇲🇳Mongolians who will soon be using the script much more frequently (in theory); add that to the roughly 2.5 million 🇨🇳Inner Mongolians who already use the script (the Inner Mongolia number is in decline; it was 4M in 1998).
As of 2010 there were ~368k Oirat speakers in Central & East Asia; those in China use a modified Mongolian script. Also, 30,000 speakers of Daur and Xibe with different modified scripts. Sorry I used a missionary's map for the Xibe language.


There are only a handful of native Manchu speakers left, but there are several thousand scholars who speak it in order to study Qing dynasty manuscripts. Manchu also uses a modified script.
All writing in the Mongolian script consists of 24-ish sub-units (more in Oirat/Manchu/etc). A letter is composed of one or more sub-units. For example, here is the word ᠣᠶᠢᠷᠠᠳ ойрад /oyrad/ "Oirat" split into letters and sub-units.

(NB: splitting into letters might be the wrong approach here, as Mongolian script is normally taught as a syllabary, to aid in learning the various ligatures and logotypes)
Mongolian script typewriters and moveable-type-printers work by inputting individual sub-units, not whole letters!
https://twitter.com/allysonseaborn/status/624477845834719232
Remember, Mongolian letters take different shapes at the start, middle and end of words. For example, here are the words for "book", "pomegranate", and "animal", with the ⟨n⟩ grapheme highlighted.
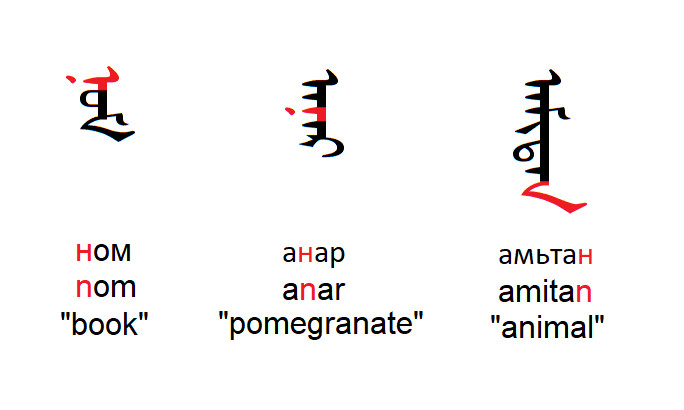
The ⟨n⟩ grapheme is written with a different glyph in all three words, but at heart it's the same letter. So in this case we'd say "the n grapheme is represented as three glyphs". To borrow a typography term, it follows a "shaping rule".
This seems comparable to Arabic, right?
Arabic script: 2-4 glyphs per grapheme; shaping rules determined by the immediate neighbors; shaping rules are (very nearly) consistent among all languages that use Arabic script and its extensions.
Arabic script: 2-4 glyphs per grapheme; shaping rules determined by the immediate neighbors; shaping rules are (very nearly) consistent among all languages that use Arabic script and its extensions.
Mongolian script: up to TWELVE glyphs per grapheme; shaping rules determined by far-away graphemes; shaping rules vary between languages; shaping rules have exceptions.
Let's look at a couple examples. Here are all the glyphs that the transcription ⟨ü⟩ can correspond to. (the parts marked in red are part of a different letter)

Enclitics are special case-marking suffixes for the Mongolian language (I'm not sure if Xibe/Manchu/etc use them). They use the initial or medial form most of the time, but ⟨a⟩ and ⟨ü⟩ get special enclitic-only forms.
Do you want to see the same chart for the letter ⟨ö⟩? Guess what, it's the SAME CHART. In the Mongolian language, ⟨ö⟩ and ⟨ü⟩ are written the same, as are ⟨o⟩ and ⟨u⟩, and many other letters have partial overlaps. Foreshadowing…
In schools, pairs like ⟨o⟩ and ⟨u⟩ are taught as unique, distinct letters despite looking identical. This is unique to the Mongolian language; Xibe, Manchu, Oirat, and other languages added new symbols to differentiate these sounds.
Most letters don't have this many shaping rules. But ⟨q⟩ & ⟨g⟩ have a really unusual shaping rule: the glyph changes based on word gender! E.g. word-final ⟨g⟩ bends to the right in masculine words, and bends to the left in feminine words.

(oh gosh oh no my friend who speaks Manchu is reading this, oh gosh I'm so sorry if I get everything wrong, aaaaa)
Anyway Manchu has gendered final ⟨g⟩ forms as well, but they're reversed from the image above—masculine ⟨g⟩ points left, feminine ⟨g⟩ points right.
I admit I am confused on this point still; many sources treat ⟨q⟩ as two letters, ⟨q⟩ and ⟨k⟩, and ⟨g⟩ as two letters, ⟨g⟩ and ⟨ɣ⟩, but China and Mongolia requested that Unicode merge them into two letters total, not four.
Also! Many of these shaping rules can go RIGHT OUT THE WINDOW when it comes to loanwords! Several letters take their medial form at the end of loanwords. That's what I read, at least. I haven't found many good examples.
The most succinct English-language summary of Mongolian orthography comes from, oddly enough, the Estonian Place Names Database. eki.ee/knab/lat/kblcm…

You know how spelling in English is all messed up? That's partly because our spellings ossified several centuries ago; pronunciations changed and spellings did not. Arika Okrent has a book on this topic coming out that I'm very exited for!
Well, Mongolian spelling is similar.
The word for "father" in the traditional script is ᠠᠪᠤ—an ⟨a⟩, then ⟨b⟩, then ⟨u⟩. But in the dominant dialect, it's pronounced like "aaw/aav" and indeed that's how it's spelled in Cyrillic: аав. Similarly, "mother" is ᠡᠵᠢ ⟨eji⟩ but pronounced "ehj" and spelled ээж.
One apt example is "transcription": ᠪᠢᠴᠢᠯᠭᠡ ⟨bichilge⟩. A more modern pronunciation is reflected by its Cyrillic spelling: бичлэг (bichleg). In general Cyrillic Mongolian is spelled like it's pronounced in the majority Mongolian dialect.
But also some words DO have a modernized form in Mongolian script: the initial ⟨g⟩ in ᠭᠠᠯ ɣ᠋al гал "fire" has 2 dots in modern spelling, no dots in traditional. 🤷
I imagine it will be very interesting to see generations of folks who only know the reformed Cyrillic spellings as they encounter traditional spellings in Mongolian script. Will it spur additional spelling reform? How could it not?
So that's a short intro to Mongolian and the Mongolian script. The grammar is complex, the script is complex, the rules seem capricious to a novice. Now let's try to make computers understand it. How hard could that be?
END OF PART 1
END OF PART 1
Part 2: The Mongolian is in the computer
A week ago, I knew nothing about Mongolian text encoding. I assumed it was fine! I thought Unicode would be the least problematic part of the Cyrillic-to-Mongolian transition, and designing vertical websites was going to be the bugbear.
A week ago, I knew nothing about Mongolian text encoding. I assumed it was fine! I thought Unicode would be the least problematic part of the Cyrillic-to-Mongolian transition, and designing vertical websites was going to be the bugbear.
Friends, I warn you now: there aren't many answers in here. There are many, many questions.
So in the late 80's there were over 4 million people, mostly in Inner Mongolia, using the traditional Mongolian script, but with no computer support. They needed a keyboard layout, and they needed a consistent encoding.
(BTW, Cyrillic Mongolian had problems of its own! It took a LONG time for computers to support Өө and Үү, the Cyrillic Mongolian characters that I've been writing as ⟨ö⟩ and ⟨ü⟩.)
There wasn't an existing keyboard layout to borrow from. Remember, Mongolian typewriters (and lead type) didn't type characters, they typed fragments:
https://twitter.com/tsmullaney/status/1099786562898980864
I think the earliest standard for a keyboard layout and character encoding is GB 8045, written in 1987. I can't read it (it's in Chinese) but I can look at the pictures!

As I understand it, every glyph has its own code point. So if you hit the ⟨o⟩ ⟨u⟩ ⟨ö⟩ or ⟨ü⟩ key in the middle of a word, your computer inserts the character at code point 0xC5.

Phonetic information is lost when in this method. If you look at code point 0xC5 in isolation, it's impossible to tell if it represents an o, u, ö, or ü.
But script encodings aren't supposed to encode phonetic information, right?
...Right?
But script encodings aren't supposed to encode phonetic information, right?
...Right?
Let's say we want to type the word ᠳᠤᠭ дэг "dug", which means "deep sleep". We press the ⟨d⟩ key, then the ⟨u⟩ key, then the ⟨g⟩ key and our GB-8045-compliant word processor handles the rest.
Let's change it to ᠳ᠋ᠤᠭ, still transcribed дэг "dug" but with a different initial ⟨d⟩. This word means (I swear I'm not making this up) "in chess, to put an opponent in check using the bishop."
So we delete the ⟨d⟩ at the start of the word.
So we delete the ⟨d⟩ at the start of the word.
Now we have a problem! When we deleted the ⟨d⟩, it means we have to change the next character from medial-form to initial-form. Our text editor knows the medial form, 0xC5, but which initial form should it display?

The text editor has two possibilities here, and no way to know which is correct. It doesn't remember that we typed ⟨u⟩ and not ⟨ü⟩—how could it? Our text editor gives up and deletes the entire word instead of dealing with the ambiguity.
So that's what happens when a Mongolian script encoding DOESN'T keep phonetic information. We *need* to encode some phonetic info, which makes it unlike basically every other script on the planet, even complex ones like Arabic and Tibetan.
Some other encodings came up in the 90s and early 2000s: Menksoft, Saiyin, Boljoo, Sudar, MBE, Fangzheng, Oyuta, Sain, Mingantu, Burigude. None of these are compatible with the others. (I promise I'll get to Unicode soon)
Some encodings work like GB-8045: one glyph at each code point, no shaping rules. Others utilize advances in font tech that allow shaping rules (like in Arabic script). I think Burigude encodes only sub-units, like the old typewriters.
Other than Burigude, all these systems encode phonetic information. Multiple code points per glyph! The medial ⟨o⟩/⟨u⟩/⟨ö⟩/⟨ü⟩ from above? Now it's four code points! For example, Menksoft, which is by far the most popular encoding:

So, hooray, we've solved the earlier ambiguity problem! But we've introduced soooooo many more ambiguities at the same time.
On to Unicode. Unicode is supposed to be a global standard, so anyone anywhere can read the same information accurately. Mongolian was technically added to Unicode in 1999, but many users argue that it's *still* not in a usable state.
The earliest discussion of Mongolian in Unicode was in 1992, the first proposal was a year later. It included a note: "As we have no experience in the development of the character code set we ask you to help us how to do better."
I was surprised by how similar this first proposal was to Menksoft encoding, even though Menksoft would not be founded until the year 2000. Multiple code points per letter, code points are not shared even when they have the same glyph.


In the coming years, the ability to apply shaping rules became much more common in fonts. It was now easy to merge, e.g., all four forms of Arabic bāʾ into a single code point, and let shaping rules determine the presentation form.
"Don't encode presentation forms" became a Unicode rule.
In 1995 Mongolia and China, in a joint proposal full of collaboration and camaraderie, made their pitch to the Unicode Consortium.
It...encoded presentation forms.
In 1995 Mongolia and China, in a joint proposal full of collaboration and camaraderie, made their pitch to the Unicode Consortium.
It...encoded presentation forms.
I think the delegation justifies their decision quite well! Still, this was not received warmly by the Unicode Consortium. (Img src: X3L2/96-103)

Unicode turned down the proposal. They requested a Mongolian encoding where all possible glyphs for a letter are encoded in the same code point (like Arabic), while also acknowledging this might be impossible because of all the variants.
Recall the gendered forms of ⟨g⟩ and ⟨q⟩. At the time there was no method for a font to calculate a word's gender and render the correct glyph. Experts floated the idea of an invisible gender-marking character, which I find highly amusing.

(That's it, that's the only appearance of the zero-width gender reveal party in this thread, you can stop reading if you want to)
After lots more back-and-forth, all parties settled on an encoding that worked like Arabic. An initial ⟨g⟩, medial ⟨g⟩, or terminal ⟨g⟩ would all have the same code point and the font would compute the right form to display.
But there were still multiple initial, multiple medial, multiple terminal forms for most letters! To accommodate this, the proposal required:
1. The most complex shaping rule of any font ever
2. Four invisible "manual override" characters
1. The most complex shaping rule of any font ever
2. Four invisible "manual override" characters
Requirement 1: extremely complex shaping rules. At this point no one had written out all the shaping rules, mind you. They just said "this will be required and we'll agree upon it later."
Requirement 2: When the complex rules fail to predict the correct form, users need to append an invisible additional character after the letter to convert the glyph to one of its variant forms. Which variants? "We'll figure it out later"
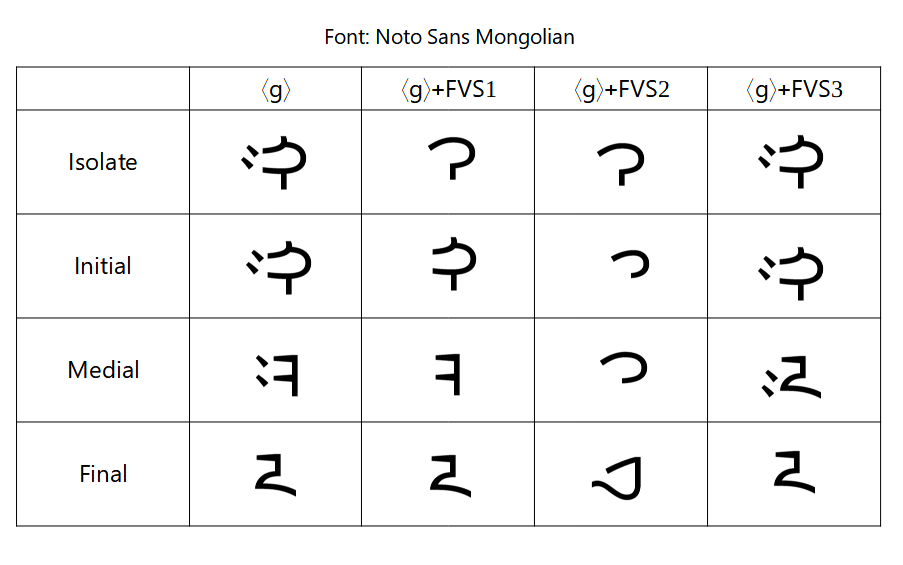
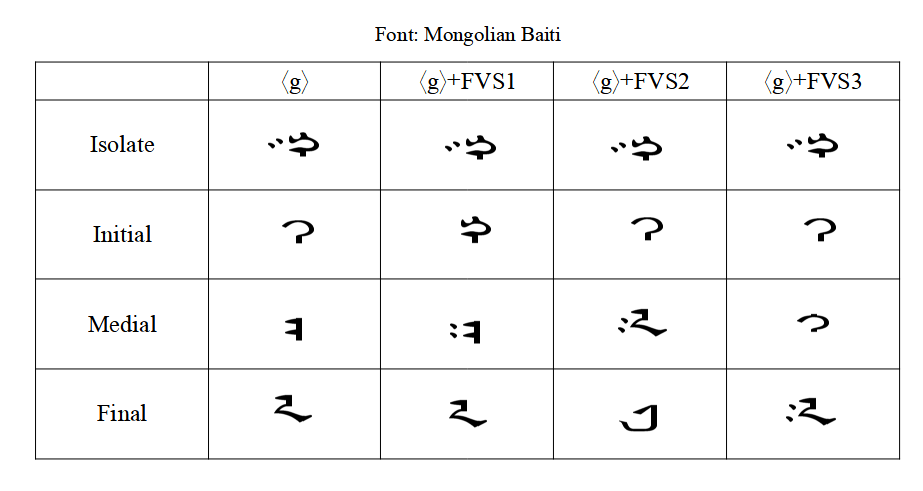
3 of the invisible characters are "Free Variation Selectors" (FVS1, FVS2, FVS3). If a letter has variants, put an FVS after it to display a variant. If you put an FVS in when there is no variant to display, nothing happens (in theory).
Here are the effects of the FVS characters on ⟨g⟩. Notice that the results are inconsistent between fonts, even now in 2021. (that's very bad)
The 4th invisible manual-override character is the Mongolian Vowel Separator or MVS. It is used exclusively for word-final ⟨a⟩ and ⟨e⟩ variants, and it goes BEFORE the character it modifies, not AFTER. (img src: Unicode Standard 5, Ch. 13)

"Couldn't this be done with an FVS?"
"Well, no, because the MVS *also* sometimes modifies the letter preceding it, as well as the letter after it."
"But couldn't you add one more shaping rule specific to these variant vowels?"
"…………"
"Well, no, because the MVS *also* sometimes modifies the letter preceding it, as well as the letter after it."
"But couldn't you add one more shaping rule specific to these variant vowels?"
"…………"
Speaking of those shaping rules, when *did* Unicode come out with guidance on what code sequences should produce what glyphs?
A guide was seemingly rushed out in August '99, around when Mongolian Unicode was approved. But it had mistakes and was being tweaked as late as 2010. Typographers have interpreted the guide differently, resulting in incompatible fonts.
The most recent update to the Mongolian code chart was March 2020 with the release of Unicode 13.0. The release announcement warns that further changes are coming...someday.

This is not great for users. Two websites, with two different fonts, can (and do!) display the same letterforms with dramatically different underlying encodings. Heck, at the moment two websites with ONE font can display the same letterforms with dramatically different encodings!
There are several proposals for fixing Unicode Mongolian. But it will be very messy, because there is so much text already out there in Menksoft encoding, or in Unicode but only correct in Monbaiti, or in Unicode but only correct in Noto Sans.
My favorite proposal is by the Zteam user group. Not because I think it's the most realistic, but because I appreciate their passion and novel approach. I can't read most of the original essay, but I love the Time Cube graphics.

No matter what proposal gets approved, it will take a lot of effort to convince the public to convene on a single Unicode encoding.
Myanmar did something similar recently, and it was not easy.
Myanmar did something similar recently, and it was not easy.
(Brief aside 1/2) Unicode and Zawgyi are two encodings for the Myanmar script and they are completely incompatible. Unicode dragged their feet making a full standard for font shaping, during which time Zawgyi got a huge market share.
(Brief aside 2/2) The Myanmar government had to run an elaborate nationwide campaign to get people and businesses to switch to Unicode by October 1, 2019, which was designated "U-Day". But gigabytes of old text are still out there, in Zawgyi.
I'm sure Mongolian encodings will eventually be resolved and harmonized. But it will require a lot of time, and a concerted effort by at least two national governments.
END OF PART 2
END OF PART 2
Part 3: the one thing I just can't figure out
Mongolian Unicode isn't perfect, and the rollout was mishandled, but I understand most of the logic behind the encoding they settled upon. I read every ding-dang document from the Unicode Consortium on Mongolian: unicode.org/L2/topical/mon…
There's still one thing I don't get. I really, REALLY don't get it.
Why are ⟨o⟩ and ⟨u⟩ are separate codepoints? Why are ⟨ö⟩ and ⟨ü⟩ separate codepoints?
Why are ⟨o⟩ and ⟨u⟩ are separate codepoints? Why are ⟨ö⟩ and ⟨ü⟩ separate codepoints?
They are visually identical. They are visually identical. They are visually identical.
Every single encoding differentiates o and u, and ö and ü, and I can't figure out why. Chinese and Mongolian representatives at the Unicode Consortium insisted on it from the beginning. They give this explanation, verbatim, several times:

I don't find that explanation satisfactory at all! Mongolian has lots of unique features, but "different meanings in identical forms" is not one of them. Why should homographs get special treatment in this script but not others?
I can think of no comparable situation in any writing system anywhere. In Japanese, the kanji 生 has at least 12 possible pronunciations; should all of those have their own code point?
In English, "bow" can be pronounced /boʊ/ or /baʊ/; should I use a different "o" code point in each one?
Shona uses unmodified Latin script, but it's a tonal language; should high tone "a" be coded separate from low tone "a"?
Shona uses unmodified Latin script, but it's a tonal language; should high tone "a" be coded separate from low tone "a"?
And yet, every Mongolian encoding proposal insists on keeping the o/u/ö/ü distinctions. And they trot out that same paragraph, with bodo/budu and ögelehü/ügelehü, every time.
It's not until *2018* that someone offers a different justification, one that I can appreciate much more (though I'm still not convinced): unicode.org/L2/L2018/18101…
The authors cite Danjindagba, an 18th century Mongol scholar who wrote a grammar that was itself a commentary on a much earlier grammar. The upshot is "o/u ö/ü have always been treated as distinct, so we must continue to do so."
As an aside, the authors translate Danjindagba's book title into English as "The Space Jewel for Eliminating of Letter Ambiguity: Commentary on the Heart Essence", which instantly makes me dissatisfied with all other textbook titles.
As an aside to the aside, I believe "The Heart Essence" was the translated title of the first Mongolian grammar book, the one Danjindagba was expanding upon.
So, supporters of the o/u ö/ü separation argue that "Phonetic information in the underlying representation may make collation and linguistic analyses easier than a graphetic approach."
I really think the opposite is true!
I really think the opposite is true!
For example, one study in 2016 looked at different ways people typed ᠮᠣᠩᠭᠣᠯ, meaning "Mongolia": cips-cl.org/static/antholo…
The intended spelling is ⟨moŋgol⟩--hit the m key, o key, ŋ key, g key, o key, l key. But they found that users online typed it as ⟨muŋgul⟩, with ⟨u⟩ instead of ⟨o⟩, TWENTY TIMES MORE FREQUENTLY than the correct spelling.

How is that going to help your linguistic analysis? As discussed in part 2, *some* phonetic information is necessary for Mongolian, but demanding complete phonetic info is a fool's errand!
This is the closing argument from a 2018 memo in favor of keeping as much phonetic info as possible in the encoding. But when 95% of your users are typing things with the WRONG phonetic info, are you really helping future historians?

And Mongolia is going ahead with its 2025 deadline! I'm not sure what they actually intend to accomplish by then. I don't think the plan is to totally supplant Cyrillic, and students have already been learning the script in schools.
That's it. There's no grand ending to this. A bunch of people were asked to do a very difficult thing involving a very difficult script, and now we wait for a bodge upon a bodge upon a bodge to get things working.
Erratum: the Cyrillic here should be дуг instead of дэг:
More info thanks to redditron ulaanbaataritinator
https://twitter.com/DHammarskjold/status/1407788621864701953?s=19
More info thanks to redditron ulaanbaataritinator

• • •
Missing some Tweet in this thread? You can try to
force a refresh




