
A very common #typescript pattern with some kinda tricky types behind the scenes. codesandbox.io/s/type-mapping… 

Let's say we have a number of related objects (in this case, a few foods) that each have a unique type.
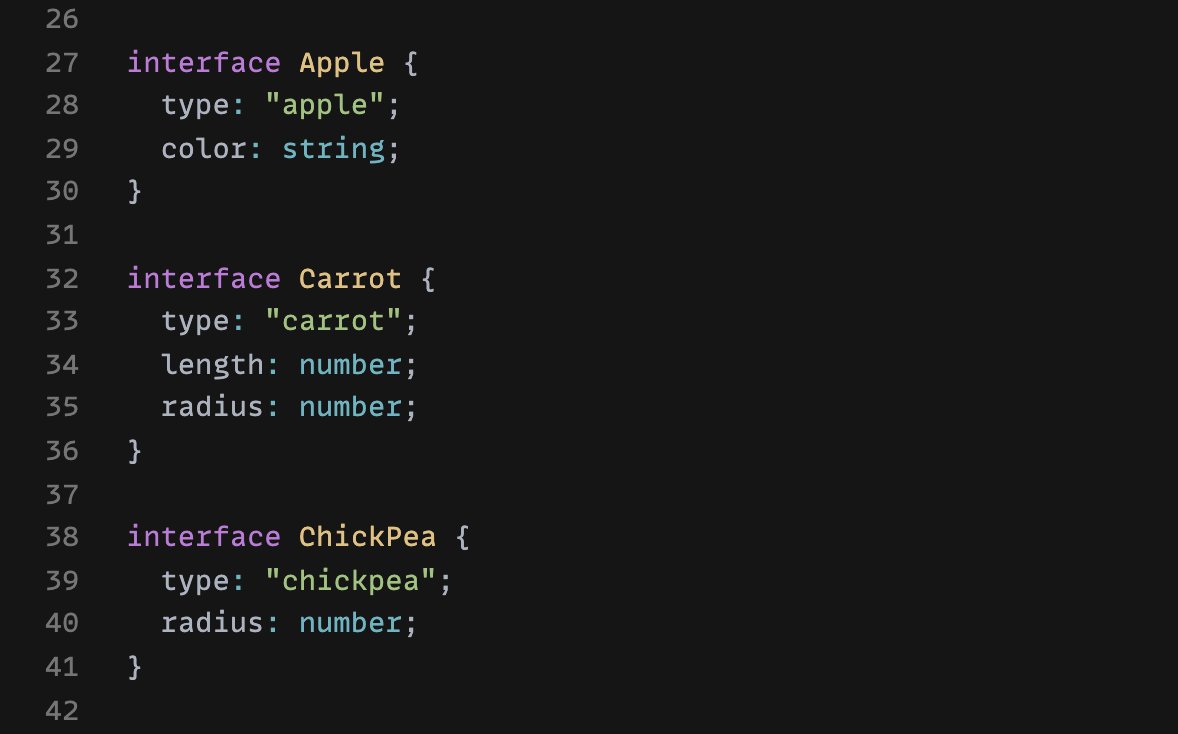
We can type all of them together as a union (Food), and extract their common types as a second different union (FoodType).

It might be nice to have a mapping of each FoodType to its corresponding Food.

Nice!
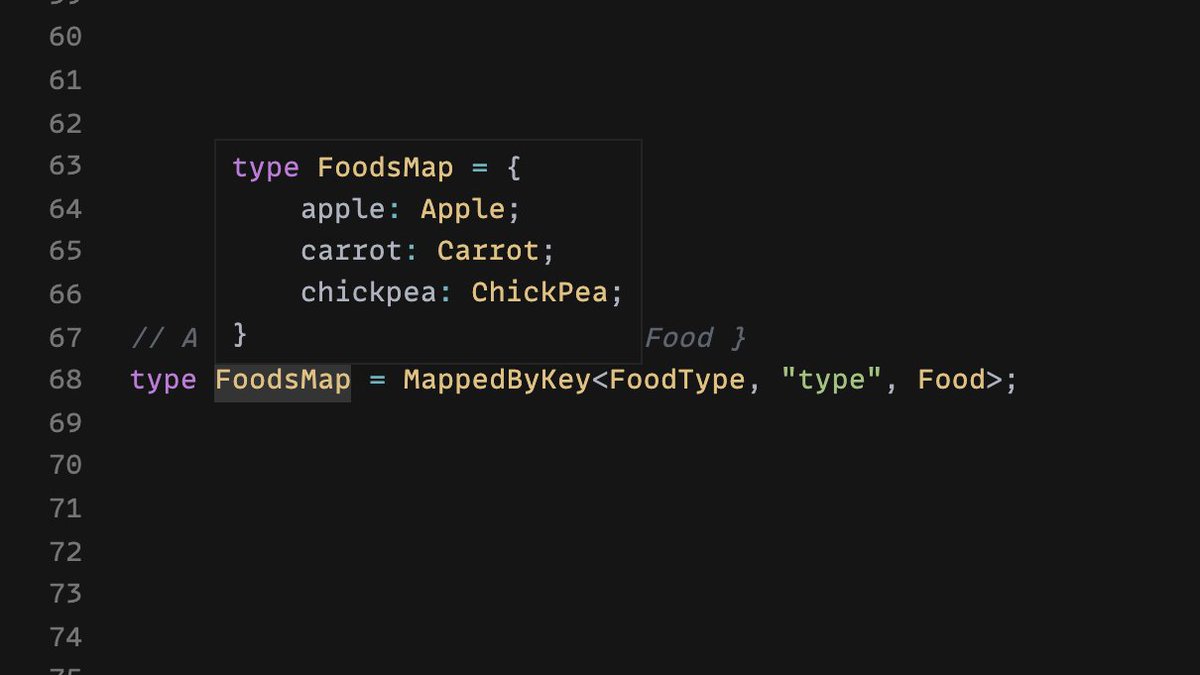
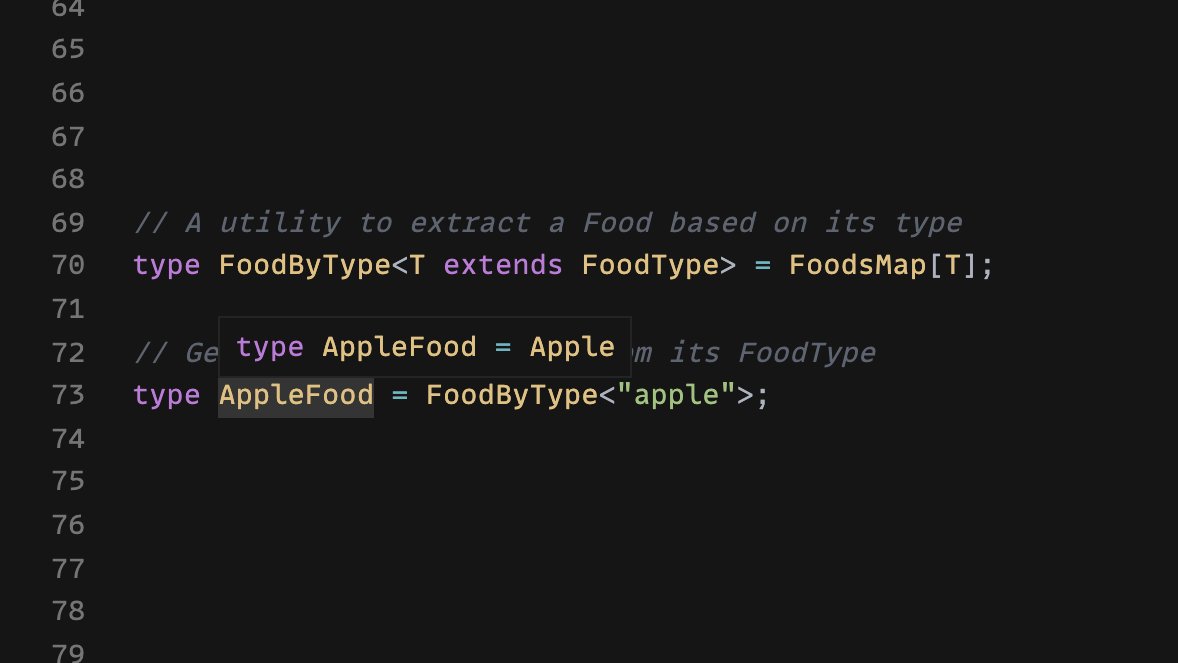
We can use this map to create a new utility that will access a Food by its FoodType.

Handy!
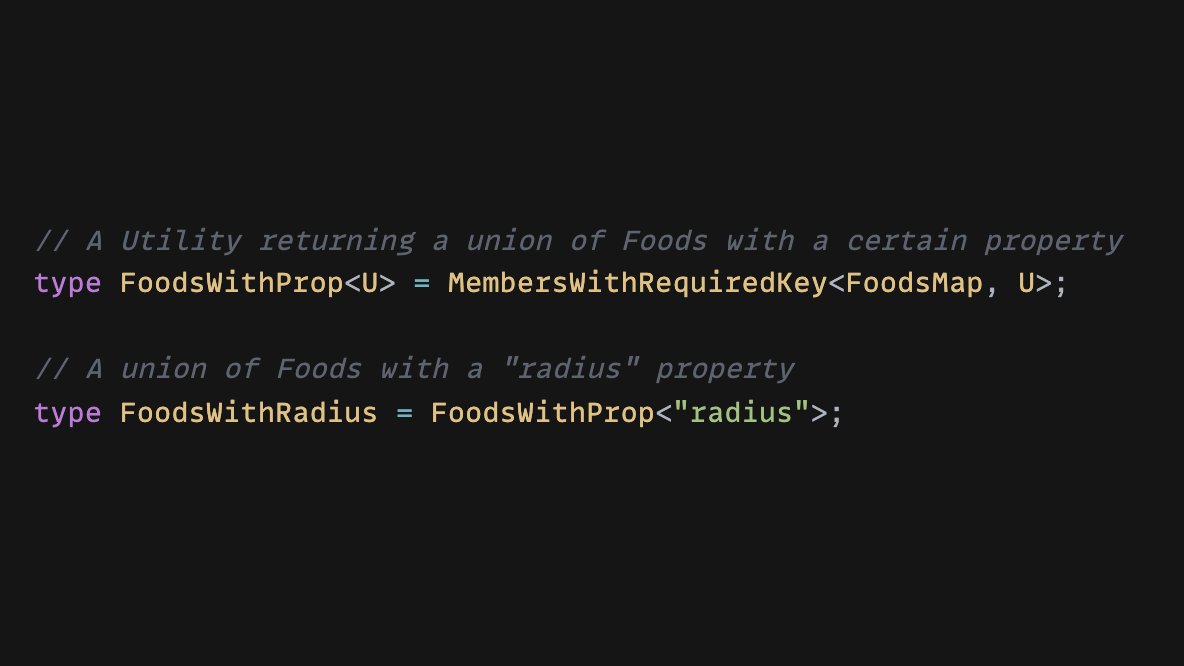
We might also want to pull a union of Food types that share a certain property. We'll need some more utilities for that one...

We can put that in practice like this.
Right on!

API time. Our Food union would let us do something like this.
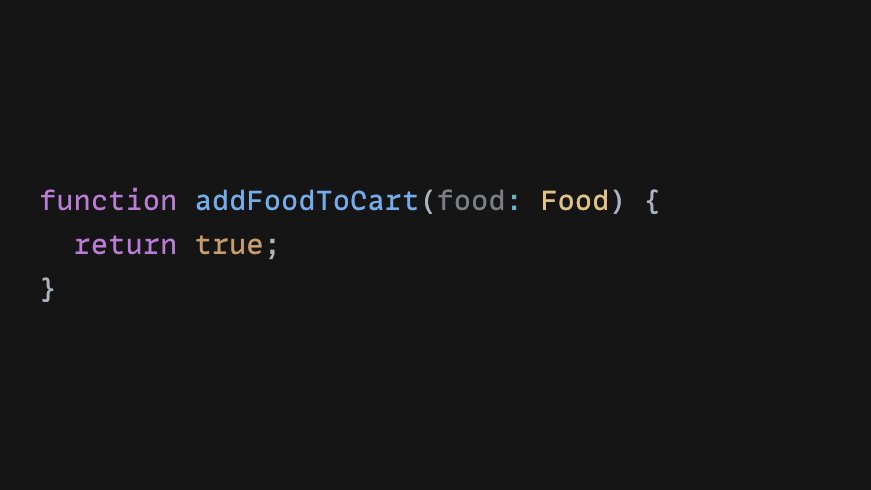
Which is nice, because once we add a type...
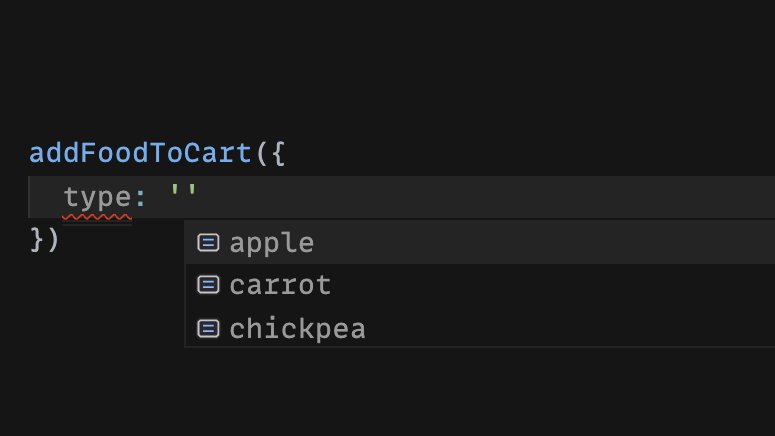
The argument will be of the corresponding Food interface with that type. Here we've added the "carrot" type, so TypeScript is expecting to receive the length and radius properties, too.
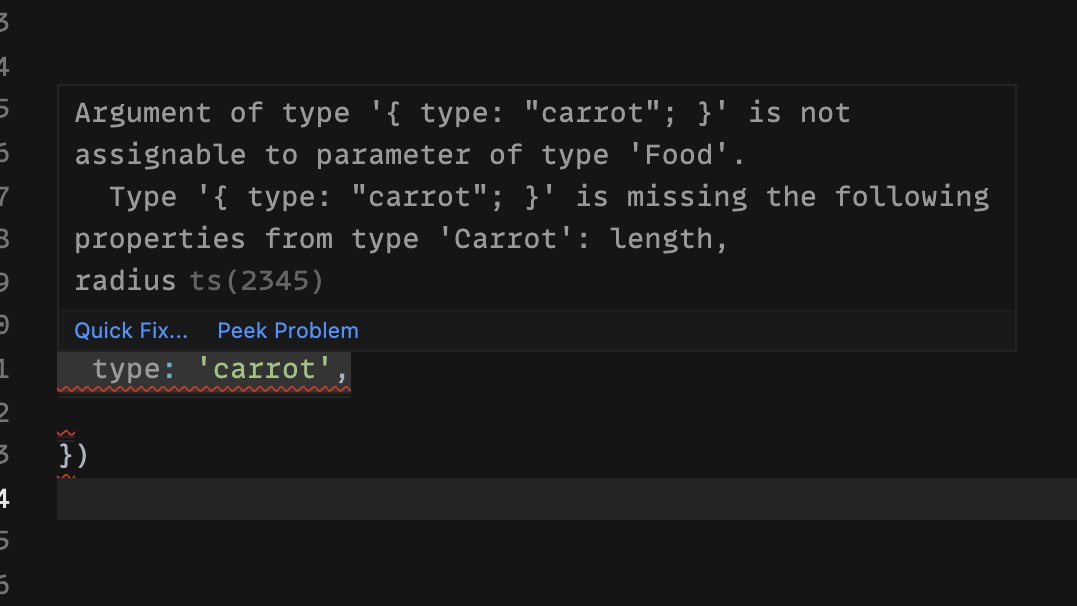
That's a decent API, but we can do better. Let's say we just want to provide the type as an argument, with the rest of the corresponding Food as options.
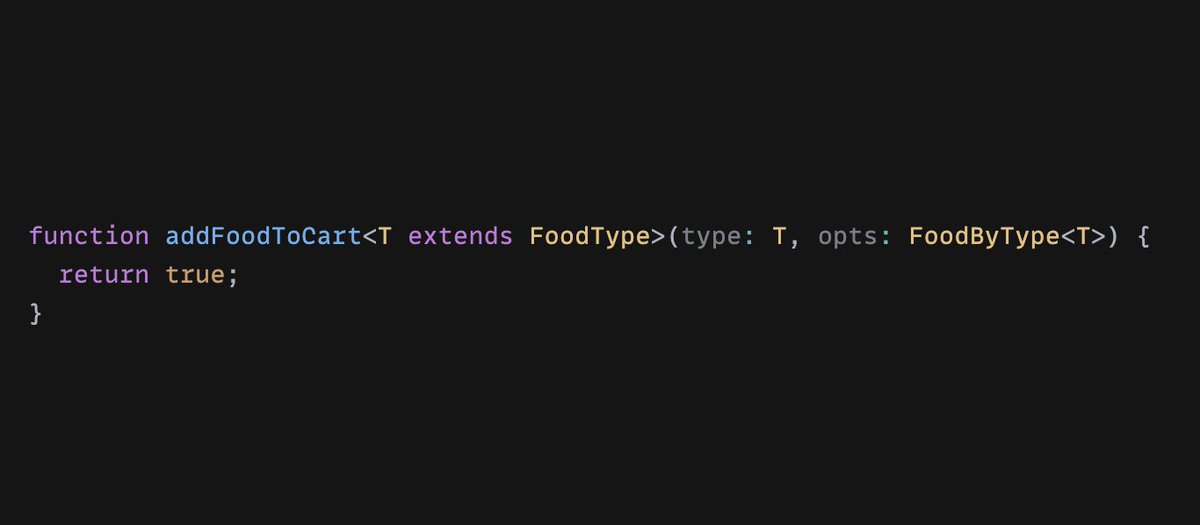
That works well too.
Even better of those options are optional.
And since we already have the type, we can omit that too.

These utilities can be helpful in plenty of places. In my case (tldraw.com), I'm using the pattern for "shapes". Here I'm getting a shape by its ID, however TypeScript doesn't know what kind of shape it is.
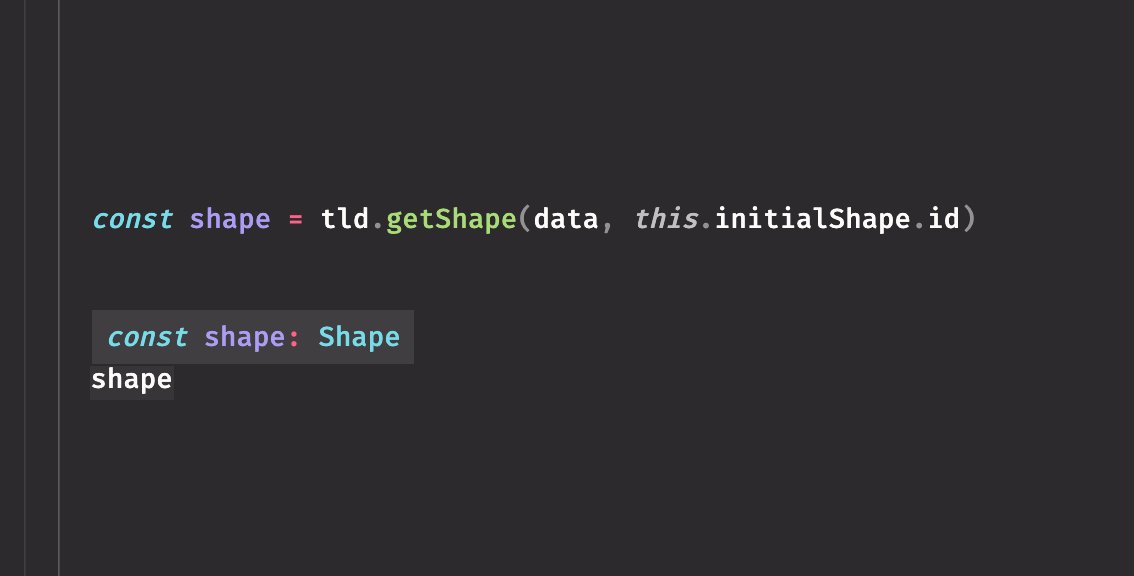
To help it out, I can write a helper that asserts that the shape actually has a certain property—which narrows its type.

Got it!

Anyway, something to try out or maybe come back to later.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



