
On ne le dira jamais assez : ARRÊTEZ DE PUBLIER DES CERTIFICATS DE VACCINATION SUR INTERNET !
Je vous propose un thread d'exemple avec cet article @France3tv, on va essayer de reconstituer le 2D-DOC "flouté" (et ce sera une excuse pour en apprendre beaucoup sur Datamatrix 😉) ⤵️
Je vous propose un thread d'exemple avec cet article @France3tv, on va essayer de reconstituer le 2D-DOC "flouté" (et ce sera une excuse pour en apprendre beaucoup sur Datamatrix 😉) ⤵️


Saluons avant de commencer le courage de @Jefffrey68 qui a décidé de sacrifier son propre pass sanitaire pour la photo ;)

Le 2D-DOC (première version des certificats de vaccination) est encodé au format Datamatrix ECC-200, qui est comme la plupart des code-barres 2D résistant à des dégâts partiels des données, ici à l'aide de codes correcteurs Reed-Solomon.
Avec suffisamment de persévérance et un peu de lecture de documentation, il est complètement possible de décoder manuellement un Datamatrix.
Ici, on va essayer d'extraire le plus de données possibles (comme je n'ai trouvé aucun lecteur qui arrive à le lire, même partiellement)
Ici, on va essayer d'extraire le plus de données possibles (comme je n'ai trouvé aucun lecteur qui arrive à le lire, même partiellement)
On commence par l'emballage : un Datamatrix est forcément entouré d'une barre de pixels noirs sur deux côtés, et de pointillés sur les deux autres côtés. Si les dimensions sont trop grandes, on fait des subdivisions comme c'est le cas dans le 2D-DOC (2x2 régions).

Pour décoder, on va se baser sur ce pavage régulier de motifs en forme de L qui contiennent chacun 8 bits.
Ici, je mets un point rouge sur le bit de poids faible pour mettre en évidence la régularité du pavage.
Ici, je mets un point rouge sur le bit de poids faible pour mettre en évidence la régularité du pavage.

Une fois ce découpage effectué, on peut commencer à décoder les octets bruts contenus dans le 2D-DOC. C'est tout simple, chaque motif en L se lit dans le sens de lecture en partant d'en haut à gauche. Dans cet exemple, on trouve 00101001 soit 41.

Tous les octets sont décodés dans un ordre de zigzag bien déterminé :

Une fois que tous les octets lisibles sont transcrits, il faut procéder à une dernière étape de décodage avant de pouvoir lire les données (tout du moins ce qu'on parvient à transcrire !)

Dans le screenshot du tweet précédent, on voit bien que les données brutes (avant décodage donc) ne correspondent pas du tout à ce qu'on trouve en scannant un certificat de vaccination avec un lecteur classique, cf.
https://twitter.com/MathisHammel/status/1397902104589651971
Il y a plusieurs éléments à prendre en compte. Déjà, les caractères sont décalés de 1 dans la table ASCII. Ainsi, les lettres "ED" que l'on voit se décodent en "DC". Ce qui correspond déjà bien au "DC04FR03" que l'on retrouve dans les 2D-DOC de vaccination !

Ensuite, les choses se compliquent un peu. Quand on essaie de regarder le caractère 0x85 dans la table ASCII, on se rend compte que c'est un caractère spécial (comme tous les caractères après 0x7F)...
En lisant la doc, on peut lire que les valeurs 130 à 229 encodent toutes les paires de chiffres entre 0 et 99. Il est donc possible d'encoder deux octets en un, pratique non ?
0x86 = 134, donc on décode les octets "04".
0x86 = 134, donc on décode les octets "04".

Le décodage se poursuit sans encombre, on arrive à récupérer le début du certificat "DC04FR03AV011E731E73L", mais ensuite tout s'effondre : le caractère 0xE6 (= 230) va venir nous poser quelques soucis. Il correspond au début d'un mode d'encodage nommé C40.

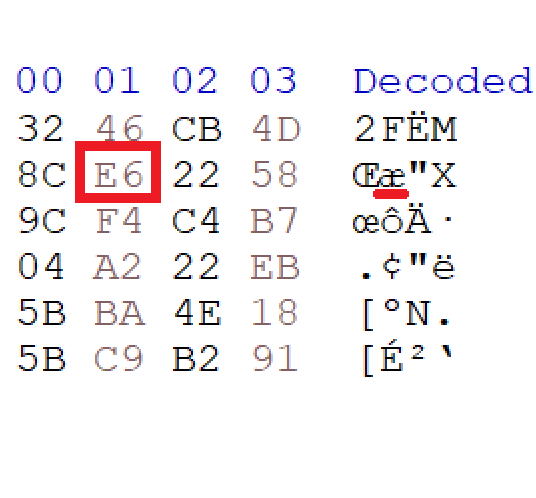
Jusqu'ici, on était dans le plus simple encodage, l'encodage TEXT. Il est efficace pour stocker des nombres comme on peut encoder deux octets en un, mais le C40 offre une meilleure compression des lettres majuscules (qui constituent la majorité du reste du 2D-DOC).
Le C40 utilise une table de caractères réduite à 40 caractères, encodés en base 40.
Par exemple, la paire d'octets 22 EB se lit comme un nombre de 16 bits 0x22EB (= 8939). On soustrait 1, puis on décode en base 40 : 5 * 40² + 23 * 40 + 18
Par exemple, la paire d'octets 22 EB se lit comme un nombre de 16 bits 0x22EB (= 8939). On soustrait 1, puis on décode en base 40 : 5 * 40² + 23 * 40 + 18

Ces trois nombres en base 40 nous donnent les trois index des caractères dans le charset.
5 = "1"
23 = "J"
18 = "E"
On vient de trouver le début du champ L1 (prénom), ici "L1JEAN-FRANCOIS" 😉
Et une compression encore assez efficace car on encode 3 octets en seulement 16 bits.
5 = "1"
23 = "J"
18 = "E"
On vient de trouver le début du champ L1 (prénom), ici "L1JEAN-FRANCOIS" 😉
Et une compression encore assez efficace car on encode 3 octets en seulement 16 bits.

Au bout d'une vingtaine d'octets décodés en C40, on rencontre la première des deux zones de floutage. 5 octets des données brutes sont fortement endommagés.
Comme les zones sont parcourues en diagonale, seuls 2 octets à la fois sont corrompus, ce qui facilite la reconstruction.
Comme les zones sont parcourues en diagonale, seuls 2 octets à la fois sont corrompus, ce qui facilite la reconstruction.

D'après la zone détruite, on se retrouve avec ce décodage partiel à la main :
FREY[DC]L1JEAN-FRANCOIS[DC]❓❓❓9031982
A noter que l'on a quitté le mode C40 pour repasser en texte afin d'encoder le byte [DC].
FREY[DC]L1JEAN-FRANCOIS[DC]❓❓❓9031982
A noter que l'on a quitté le mode C40 pour repasser en texte afin d'encoder le byte [DC].
Les deux premiers octets sont faciles. Il s'agit de "L2", marqueur de début du champ date de naissance. Mais Jean-François est-il né le 9, le 19 ou le 29 mars 1982 ?
Comme on est repassés en mode texte, cette zone encode une paire de chiffres.
Comme on est repassés en mode texte, cette zone encode une paire de chiffres.

Le premier chiffre est le 2 du marqueur "L2", le second correspond au début de la date de naissance. 3 options donc : 20, 21 ou 22.
On rappelle que les paires de chiffres sont encodées par les valeurs 130 à 229, on devrait donc obtenir l'octet 150, 151 ou 152.
On rappelle que les paires de chiffres sont encodées par les valeurs 130 à 229, on devrait donc obtenir l'octet 150, 151 ou 152.
Dans la zone endommagée par le floutage, on peut lire 1001?11? avec les deux bits de droite manquants. Regardons nos options :
1001?11?
10010110 = 150 (paire "20")
10010111 = 151 (paire "21")
10011000 = 151 (paire "22")
Ce qui nous permet d'éliminer le 29 mars !
1001?11?
10010110 = 150 (paire "20")
10010111 = 151 (paire "21")
10011000 = 151 (paire "22")
Ce qui nous permet d'éliminer le 29 mars !

Plus tard dans le décodage, le zigzag repasse par cette zone floutée. De nouveau, 2 octets corrompus mais ici ce sera beaucoup plus simple. En effet, on est en mode C40 et le décodage partiel est le suivant :
"1982L3COVID-19❓❓4J07BX03"
"1982L3COVID-19❓❓4J07BX03"
On est encore bien tombés, car les deux octets qui nous manquent sont pile sur le marqueur de champ L4 (on voit d'ailleurs le 4). Il manque "[DC]L" que l'on devra rajouter. En regardant ce qui suit, on peut comprendre que cette fois on reste en mode C40 pour encoder [DC]

Pour encoder le caractère spécial [DC] sans quitter le C40, on va utiliser les charsets Shift. La séquence "[DC]L" s'encode:
0 = Shift-1 pour passer au charset contenant [DC]
29 = index de [DC] dans Shift-1
25 = index de L en C40 standard (le shift ne dure que pour un caractère)
0 = Shift-1 pour passer au charset contenant [DC]
29 = index de [DC] dans Shift-1
25 = index de L en C40 standard (le shift ne dure que pour un caractère)
On peut donc continuer à décoder les bytes à la suite, et on se rend compte que les autres zones endommagées (le second flou, et là où se trouve le doigt) sont également faciles à reconstituer, sans même avoir à utiliser la redondance des codes correcteurs d'erreur !
Et une petite preuve que ma reconstitution fonctionne, parmi nos deux choix possibles c'était donc le 9 mars ;)

Tout ce thread était une grosse excuse pour apprendre comment fonctionne 2D-DOC et son support Datamatrix. J'espère quand même que vous retiendrez et partagerez que même flouté/gribouillé, il est dangereux de partager son pass sanitaire !
(Enfin bon, je pense que les gens qui lisent jusqu'au bout un thread sur les spécifications de Datamatrix et les gens qui postent leur QR sur internet sont deux populations strictement distinctes, bravo à vous qui lisez ceci)
Pour conclure, là je suis allé un peu loin à me croire comme McGee dans NCIS alors qu'un bon lecteur aurait sûrement marché. En réalité c'est HYPER facile de tomber sur des pass sanitaires valides et pas floutés, notamment dans la presse en ligne (en 10 minutes j'en ai trouvé 8)
Et pour celles et ceux qui se posent plein de questions pertinentes sur la sécurité des attestations vaccinales, j'ai essayé de vulgariser tout ça dans un autre thread, publié à l'instant :
https://twitter.com/MathisHammel/status/1419268005909962756
• • •
Missing some Tweet in this thread? You can try to
force a refresh












