
Finally, someone did it.
MoE + Weight sharing.
This is amazing.
WideNet finds a way to combine two time-parameter tradeoffs to reduce the final training time and parameter count.

MoE + Weight sharing.
This is amazing.
WideNet finds a way to combine two time-parameter tradeoffs to reduce the final training time and parameter count.
https://twitter.com/ak92501/status/1419824931181846528

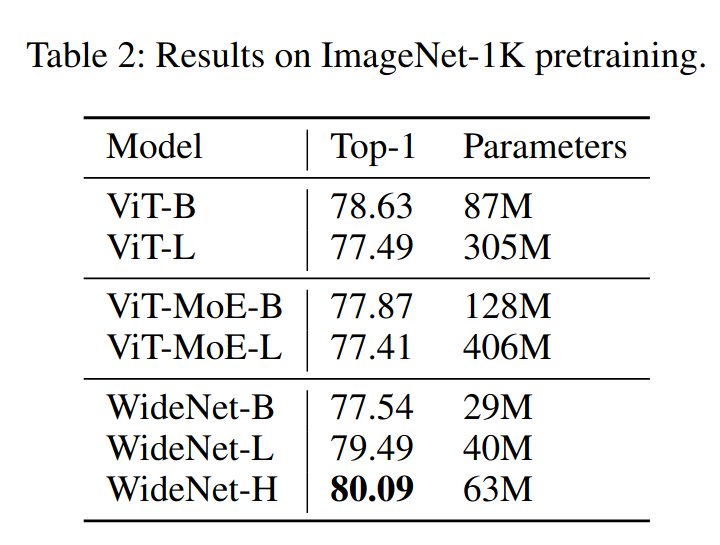
With fewer parameters, layers, and lower training time, they achieve a 3.2% (relative) lower top-1 error.
Their experiments also illustrate that ViT by itself can learn with weight sharing, which is incredibly exciting.
Their experiments also illustrate that ViT by itself can learn with weight sharing, which is incredibly exciting.

ALBERT (arxiv.org/abs/1909.11942) proposed the same thing for language models two years ago and found that adding weight sharing reduces parameter (and with that memory) consumption significantly but makes the model slower train.
Just like WideNet, they don't share LayerNorm
Just like WideNet, they don't share LayerNorm


WideNet investigated the same thing by checking whether MoE helps, and if so, how much.
The unexpected thing here is that WideNet-L performs better with parameter sharing. This could be because of the cleaner and stronger gradients for each expert.
The unexpected thing here is that WideNet-L performs better with parameter sharing. This could be because of the cleaner and stronger gradients for each expert.

To validate this hypothesis, they "group" the experts and found that gating to the same tokens for 6 blocks (2 groups) overfits much more than calculating a new gating at every block, indicating that these additional gatings are what gives this model its additional performance.

They also tested varying the number of experts in MoE and found similar things to MAT.
Adding experts (while keeping all other parameters the same) increases overfitting and reduces the evaluation performance.
Perhaps we have to use Attention-MoE?
Adding experts (while keeping all other parameters the same) increases overfitting and reduces the evaluation performance.
Perhaps we have to use Attention-MoE?
https://twitter.com/_clashluke/status/1418898627288776704

TL;DR: WideNet illustrates very well that MoE has both gradient and overfitting issues which can be improved by adding weight sharing.
Considering its curve, I'm unsure if Switch, with that NLP, has these problems at 1M tokens/step as WideNet uses a batch size of 4096 samples.
Considering its curve, I'm unsure if Switch, with that NLP, has these problems at 1M tokens/step as WideNet uses a batch size of 4096 samples.


• • •
Missing some Tweet in this thread? You can try to
force a refresh


























