📢 In our #ACMMM21 paper, we highlight issues with training and evaluation of 𝗰𝗿𝗼𝘄𝗱 𝗰𝗼𝘂𝗻𝘁𝗶𝗻𝗴 deep networks. 🧵👇 

For far too long, 𝗰𝗿𝗼𝘄𝗱 𝗰𝗼𝘂𝗻𝘁𝗶𝗻𝗴 works in #CVPR, #AAAI, #ICCV, #NeurIPS have reported only MAE, but not standard deviation.
Looking at MAE and standard deviation from MAE, a very grim picture emerges. E.g. Imagine a SOTA net with MAE 71.7 but deviation is a whopping 376.4 !




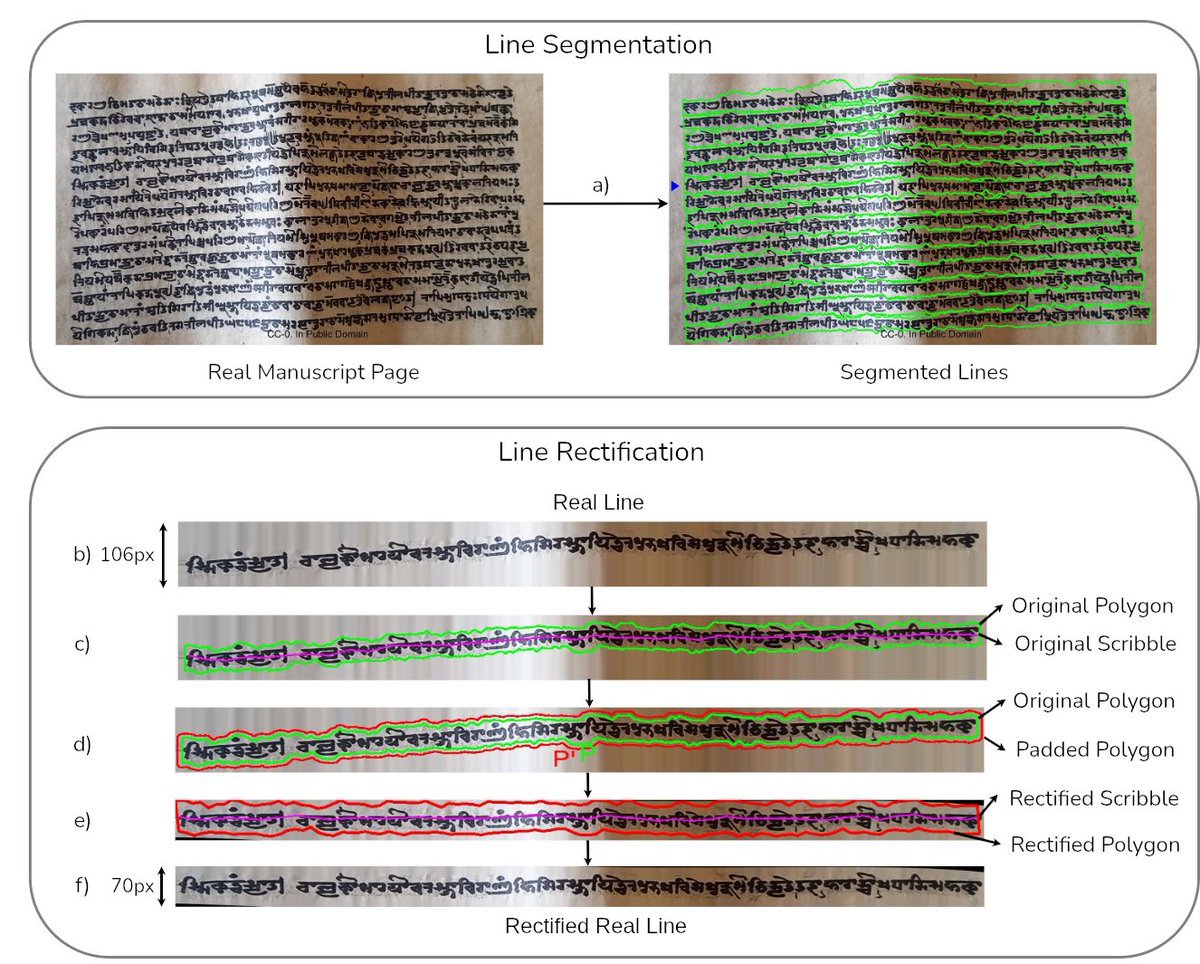
How do we address this ? There is no easy answer. The problem lies all over the processing pipeline ! The standard pipeline for 𝗰𝗿𝗼𝘄𝗱 𝗰𝗼𝘂𝗻𝘁𝗶𝗻𝗴 looks like 👇

ISSUE-1:Standard sampling procedure for creating train-validation-test splits implicitly assumes uniform distribution over target range. But benchmark dataset distribution of crowd counts is discontinuous and heavy-tailed. Uniform sampling causes tail to be underrepresented.
The problem is that sampling being done is too fine a resolution, i.e. individual counts.
OUR FIX: Coarsen the resolution. Partition the count range into bins optimal for uniform sampling.
OUR FIX: Coarsen the resolution. Partition the count range into bins optimal for uniform sampling.

We employ a Bayesian stratification approach to obtain bins which can be uniformly sampled from, for minibatching.

ISSUE-2: Minimizing per-instance loss averaged over minibatch poses same issues as those during minibatch creation (imbalance, bias). OUR FIX: A novel bin sensitive loss function. Instead of loss depending only on error, we also consider count bin to which data sample belongs

ISSUE-3: The imbalanced data distribution also causes MSE to be an ineffective representative of performance across the entire test set.

OUR FIX: Instead of using a single pair of numbers (mean, standard deviation) to characterize performance across the *entire* count range, we suggest that reporting them for each bin. This provides a much broader idea of performance across count range.
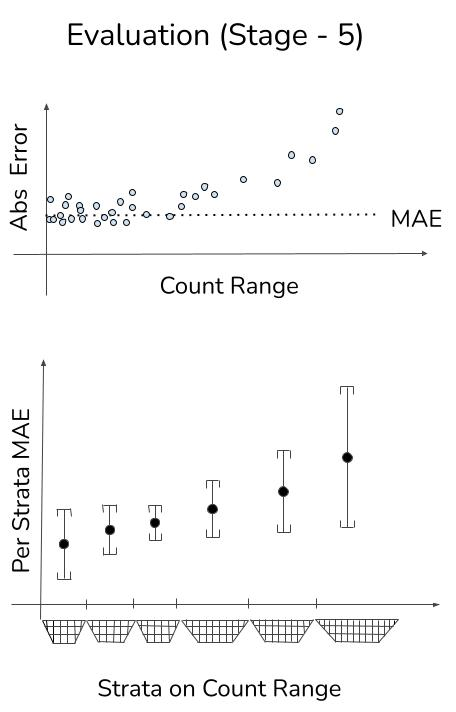
If a single summary statistic is still desired, mean and standard deviation of bin-level performance measures can be combined in a bin-aware manner.

Bin-level results demonstrate that our proposed modifications reduce error standard deviation in a noticeable manner. The comparatively large deviations when binning is not used, can clearly be seen.


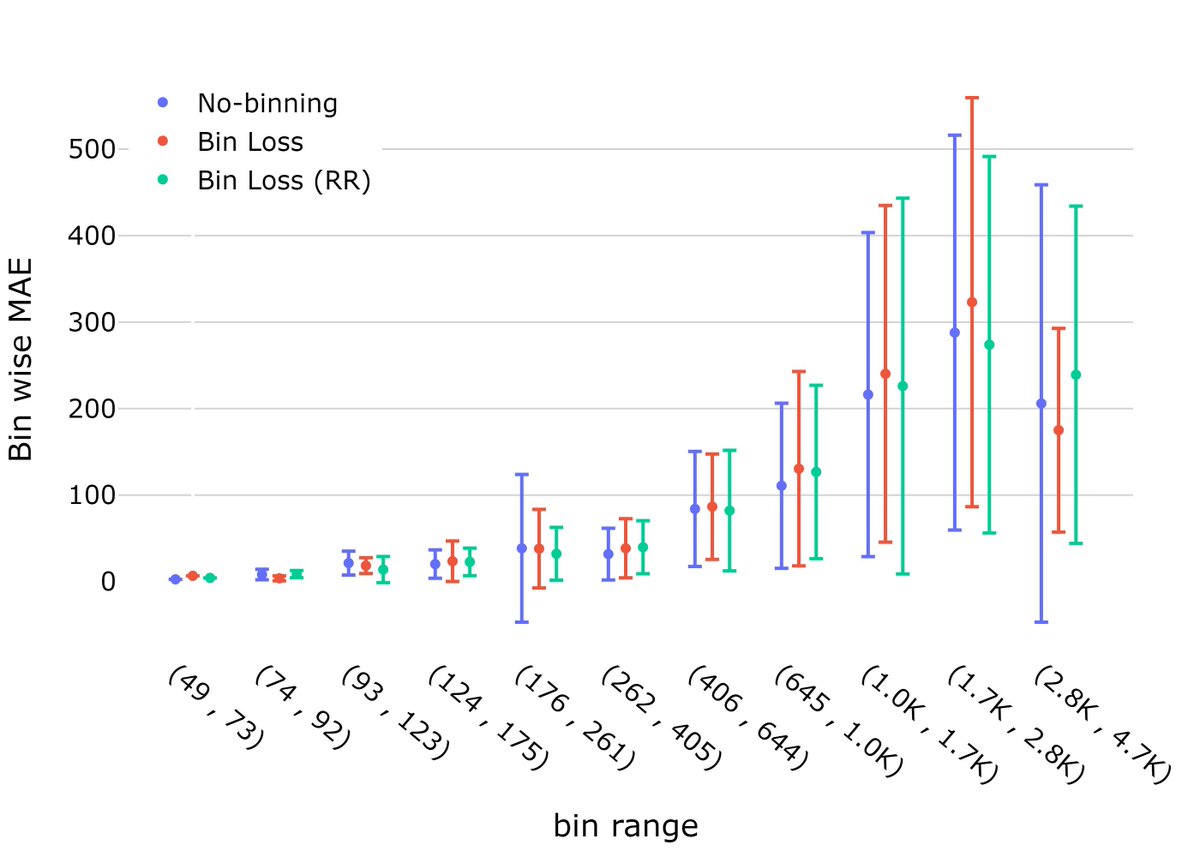
However, the large magnitudes of deviations relative to MAE are still a big concern.

Studying and addressing issues we have raised would enable statistically reliable 𝗰𝗿𝗼𝘄𝗱 𝗰𝗼𝘂𝗻𝘁𝗶𝗻𝗴 approaches in future. Our project page deepcount.iiit.ac.in contains interactive visualizations for examining results on a per-dataset and per-model basis.
Code and pretrained models can be found at github.com/atmacvit/bincr…
Our crowd counting paper can be read here
https://twitter.com/arxiv_cscv/status/1428729370135367694
... and this work is a happy collaboration with @ganramkr 😀
• • •
Missing some Tweet in this thread? You can try to
force a refresh