
Started writing my own React bindings for @croquetio, feeling pretty good. gist.github.com/steveruizok/73…
The regular @croquet/react bindings have a lot of boilerplate that's available from their context object (e.g. a viewId) so these bindings folds that stuff in. 

It’s still a lot of boilerplate though. Most of the “subscriptions” I’m writing are manually syncing these two data sources (the data published from the model and the React state).
But I have a feeling that there’s more we can do to reduce that boilerplate and improve the experience.
Forcing this thing to play with patches and a zustand store
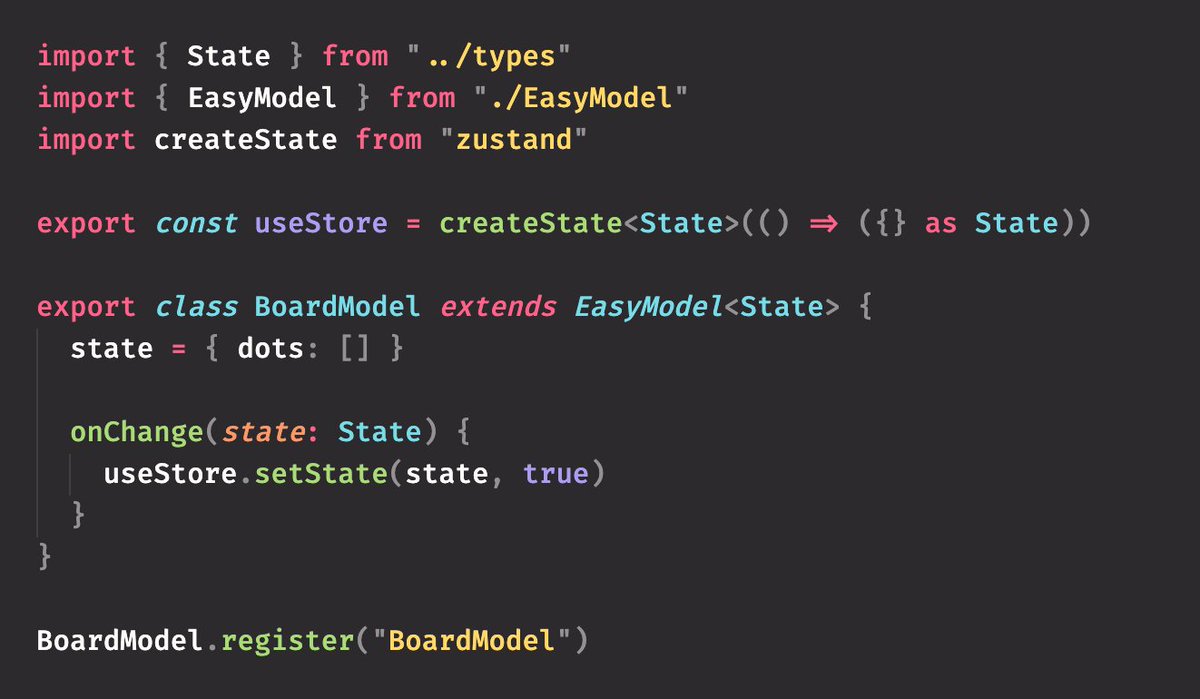
Let's pretend we only need one way to change the state: by smashing in some deep partial "patch" over the current state
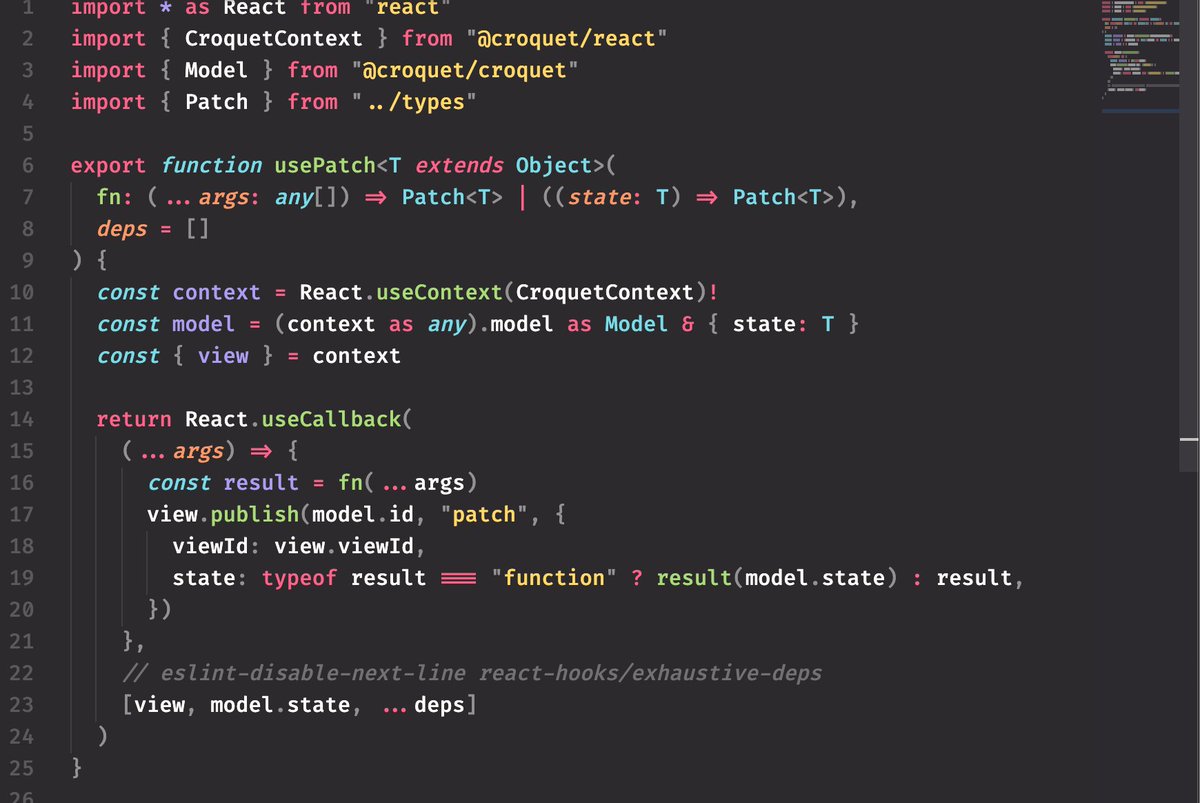
So our model will handle that patch like this, I think. Let's call it an easy model, and we'll extend this one for our app's particular state.
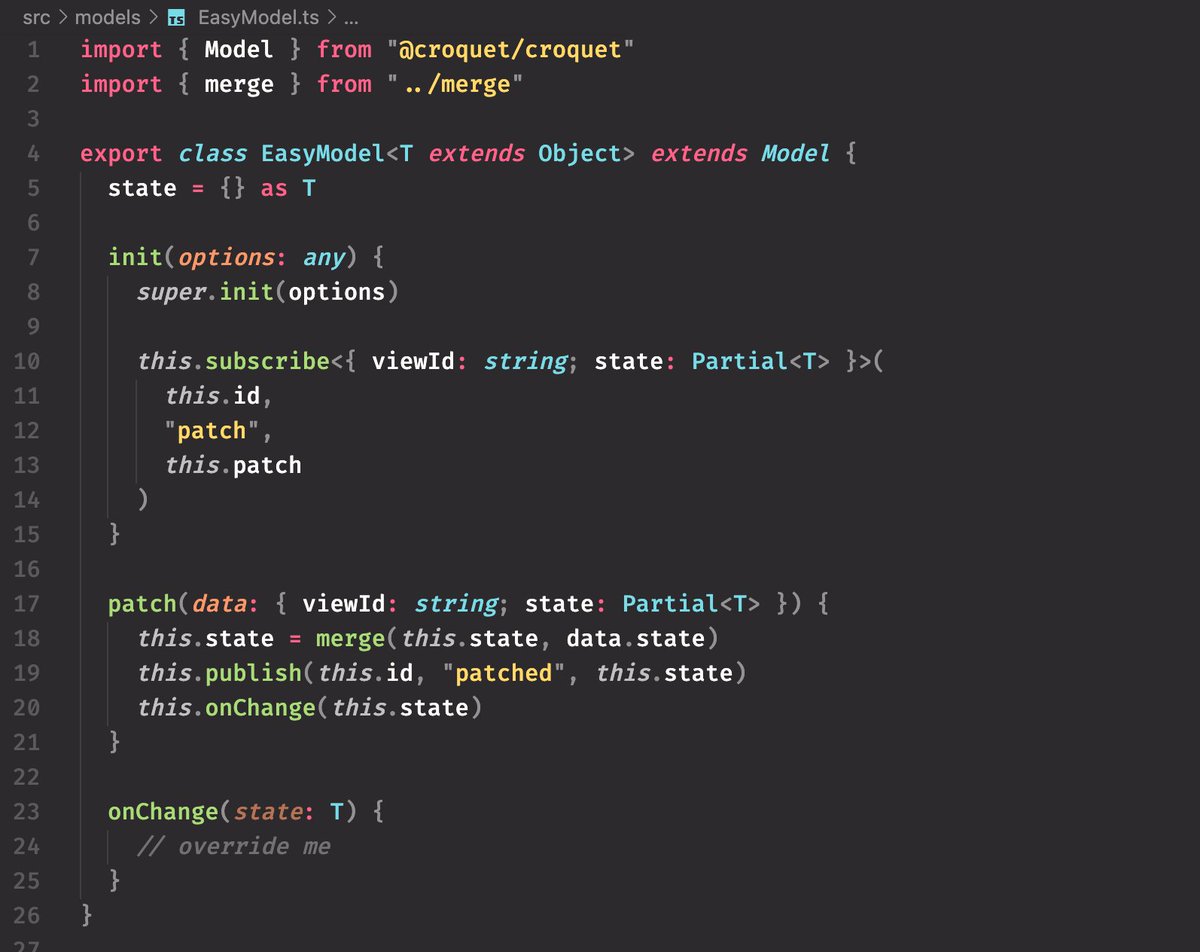
And then we make our "easy state" together with a zustand store, which it will update on change
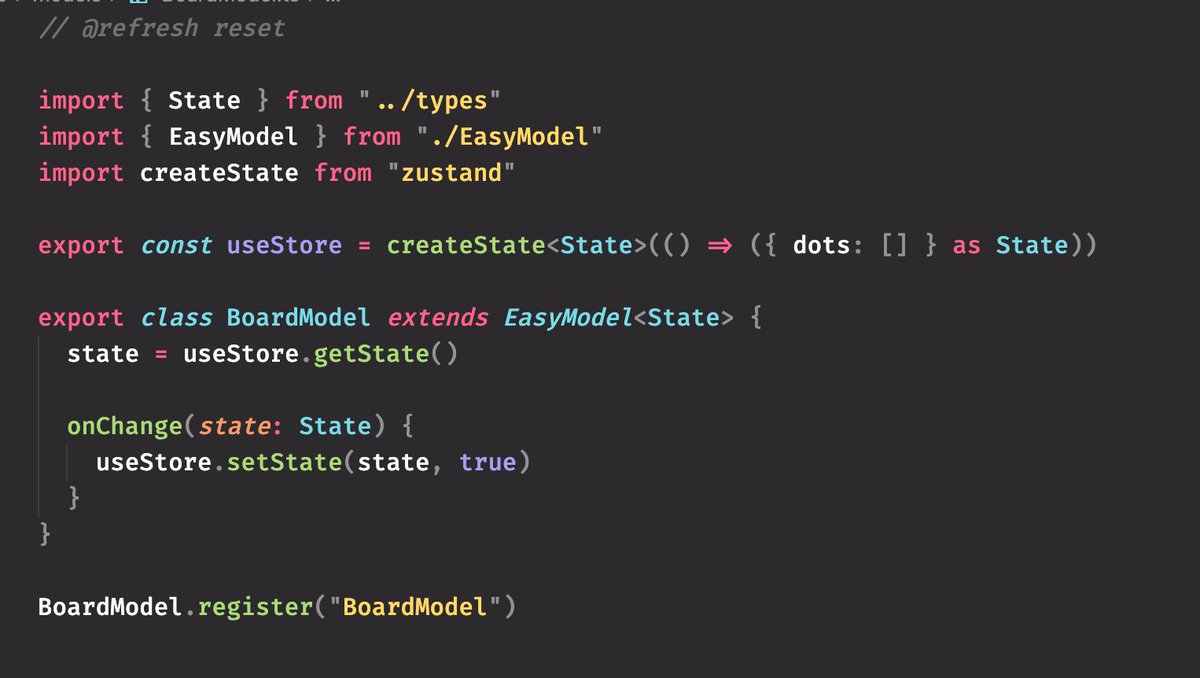
Then tada! Select out data as needed from the zustand store, and change the state by sending in new patches.
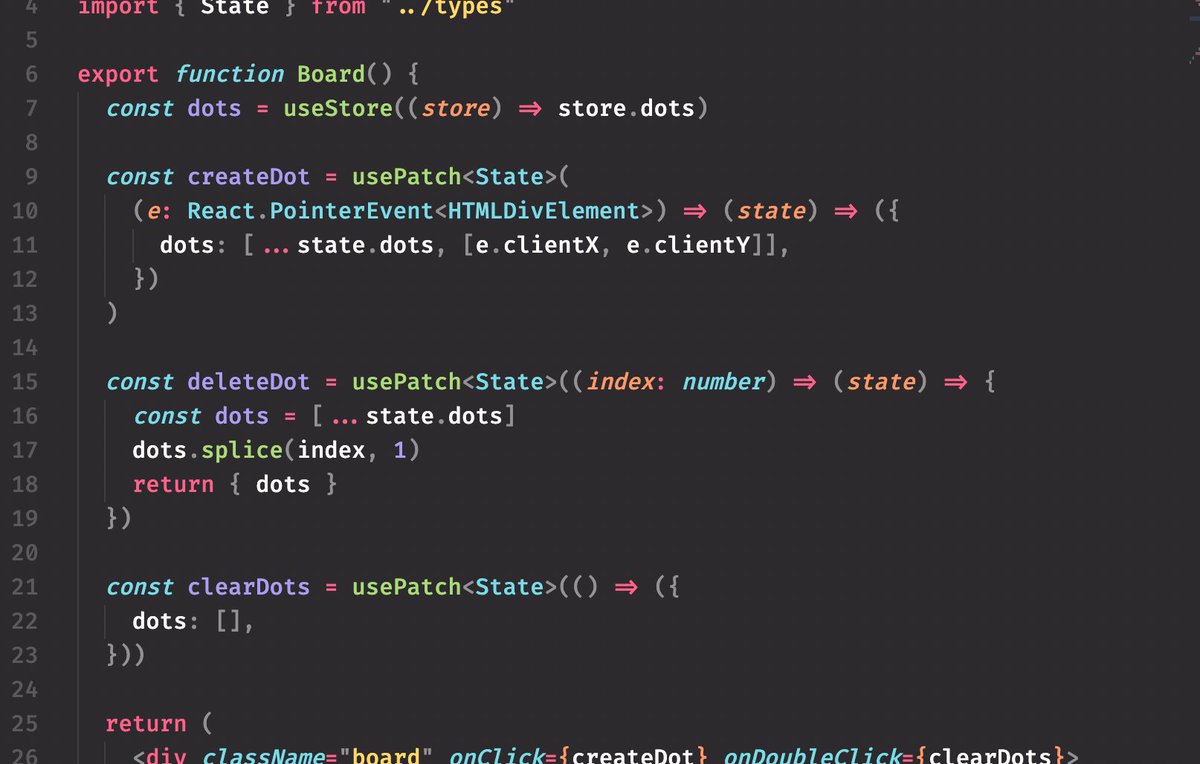
heyy
(collaborative) demo here: youthful-noyce-41aa35.netlify.app
Some initial thoughts: probably better to store dots in a map rather than an array
Maybe this one's better? happy-dijkstra-b60720.netlify.app
• • •
Missing some Tweet in this thread? You can try to
force a refresh



