
Dense retrieval models (e.g. DPR) achieve SOTA on various datasets. Does this really mean dense models are better than sparse models (e.g. BM25)?
No! Our #EMNLP2021 paper shows dense retrievers even fail to answer simple entity-centric questions.
arxiv.org/abs/2109.08535 (1/6)
No! Our #EMNLP2021 paper shows dense retrievers even fail to answer simple entity-centric questions.
arxiv.org/abs/2109.08535 (1/6)

We construct EntityQuestions, consisting of simple, entity-rich questions such as “Where was Arve Furset born?”. We find dense retrieval models drastically underperform sparse models! (2/6)
We decouple the two distinct aspects of these questions: the entities and the question patterns. We find that dense retrieval models can only generalize to common entities or the question patterns that have been observed during training. (3/6)
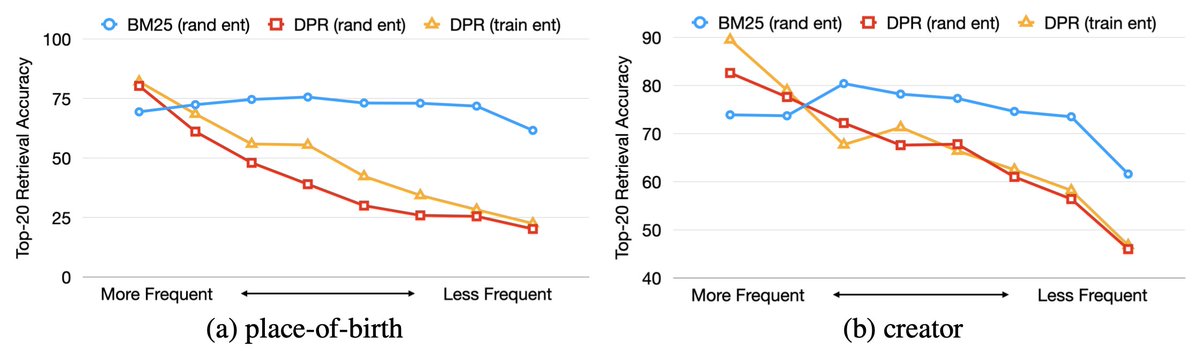
We fine-tune DPR on these simple questions and find updating the passage encoder is particularly crucial to get good results. Our visualization also shows that gold passage vectors for these questions are clustered together, so that it is difficult to discriminate them. (4/6)

We study two simple techniques aiming at fixing the issue. We find (1) data augmentation is unable to consistently improve performance on new questions; (2) fixing a robust passage index and specializing question encoder leads to memory-efficient transfer to new domains. (5/6)

Please check out our paper for details!
The code/dataset is available on GitHub: github.com/princeton-nlp/…
Joint work with @cdsciavolino, @leejnhk, @danqi_chen
(6/6)
The code/dataset is available on GitHub: github.com/princeton-nlp/…
Joint work with @cdsciavolino, @leejnhk, @danqi_chen
(6/6)
• • •
Missing some Tweet in this thread? You can try to
force a refresh


