
Wondering how to detect when your neural network is about to predict pure non-sense in a safety critical scenario?
We answer your questions in our #ICCV2021 @ICCV_2021 paper!
Thursday 1am (CET) or Friday 6pm (CET), Session 12, ID: 3734
📜 openaccess.thecvf.com/content/ICCV20…
Thread 🧵👇
We answer your questions in our #ICCV2021 @ICCV_2021 paper!
Thursday 1am (CET) or Friday 6pm (CET), Session 12, ID: 3734
📜 openaccess.thecvf.com/content/ICCV20…
Thread 🧵👇
The problem with DNNs is they are trained on carefully curated datasets that are not representative of the diversity we find in the real world.
That's especially true for road datasets.
In the real world, we have to face "unknown unkowns", ie, unexpected objects with no label.
That's especially true for road datasets.
In the real world, we have to face "unknown unkowns", ie, unexpected objects with no label.

How to detect such situation?
We propose a combination of 2 principles that lead to very good results:
1_ Disentangle the task (classification, segmentation, ...) from the Out-of-distribution detection.
2_ Train the detector using generated adversarial samples as proxy for OoD.
We propose a combination of 2 principles that lead to very good results:
1_ Disentangle the task (classification, segmentation, ...) from the Out-of-distribution detection.
2_ Train the detector using generated adversarial samples as proxy for OoD.

For 1_, we propose an auxiliary network called obsnet solely devoted to predict OoD. It mimics the architecture of the main network with added residual connection from its activation maps in order to *observe* the decision process.

How do we train the obsnet, you ask?
Well simple, we train it to detect when the main network fails.
However, errors are rare because the main network is accurate (obviously you take the best one 😅) and errors are not representative of OoD.
So how do we solve these problem?
Well simple, we train it to detect when the main network fails.
However, errors are rare because the main network is accurate (obviously you take the best one 😅) and errors are not representative of OoD.
So how do we solve these problem?

We introduce Local Adversarial Attacks (LAA) to trigger failures of the main network.
- We now have as many training samples as required
- We hallucinate OoD-like objects using blind spot of the main network.
It's all local, and it doesn't change the accuracy of the main network.
- We now have as many training samples as required
- We hallucinate OoD-like objects using blind spot of the main network.
It's all local, and it doesn't change the accuracy of the main network.
In practice, we select a random shape and attack the main network's prediction inside it. That's all! 😲
So simple, everybody can successfully code it! 😎
So simple, everybody can successfully code it! 😎
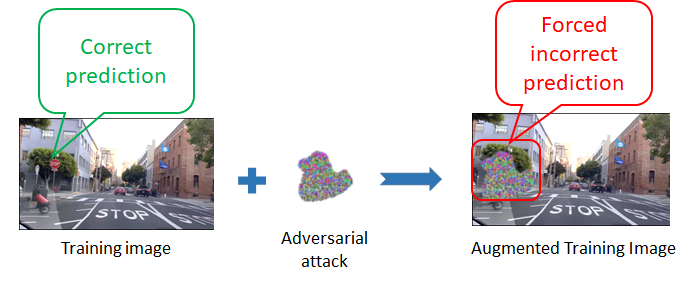
At inference, nothing is changed. LAA is used only during training, so inference time and accuracy are preserved.

We obtain super competitive results both in terms of OoD detection accuracy and in terms of inference time.
We did massive experiments by implementing and testing loads of existing methods on 3 different datasets.
We did massive experiments by implementing and testing loads of existing methods on 3 different datasets.

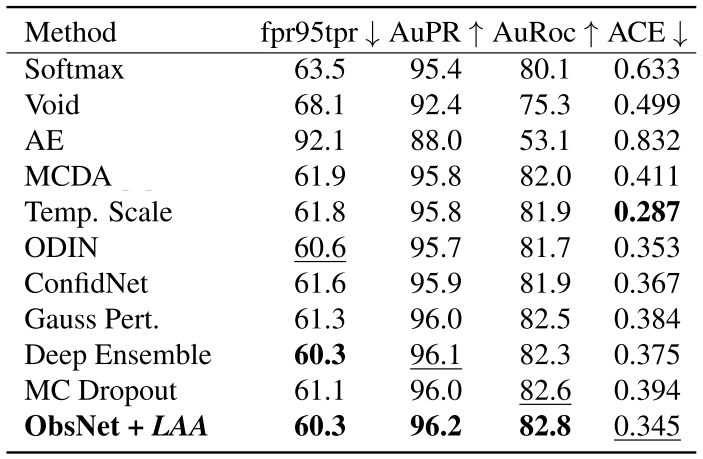
All relevant info below:
📜 openaccess.thecvf.com/content/ICCV20…
🤖 github.com/valeoai/obsnet
📽️
⏰ Session 12 #ICCV2021 Thursday 14/10 at 1 AM (CET) and Friday 15/10 at 6 PM (CET) *ID 3734*
All the hard work by @victorbesnier1 with help from @abursuc and me.
~ FIN ~
📜 openaccess.thecvf.com/content/ICCV20…
🤖 github.com/valeoai/obsnet
📽️
⏰ Session 12 #ICCV2021 Thursday 14/10 at 1 AM (CET) and Friday 15/10 at 6 PM (CET) *ID 3734*
All the hard work by @victorbesnier1 with help from @abursuc and me.
~ FIN ~
• • •
Missing some Tweet in this thread? You can try to
force a refresh





