
Is our sample of #rstats packages tweeted about during the past week or so representative? Let's find out!
@thomas_mock has an amazing dataset of 737,466 tweets with the #rstats hashtag (with the earliest dating back over 10 years ago!)
Let's run the same code on this data!
@thomas_mock has an amazing dataset of 737,466 tweets with the #rstats hashtag (with the earliest dating back over 10 years ago!)
Let's run the same code on this data!
@thomas_mock @eddelbuettel pointed out that my first lines to get all #rstats packages on CRAN could be simplified by just running
r_pkgs <- rownames(available.packages())
(thanks!)
r_pkgs <- rownames(available.packages())
(thanks!)

Alright, let's run that same code from the previous thread to see what happens!
https://twitter.com/WomenInStat/status/1448351924273754121?s=20

Fascinating! There mayyyy be some data issues. It looks like "rt" is a top contender -- while this *is* an #rstats package, as a twitter content matter expert (😂) I also know that old retweets used to be prepended with "RT" and this is probably skewing our result!
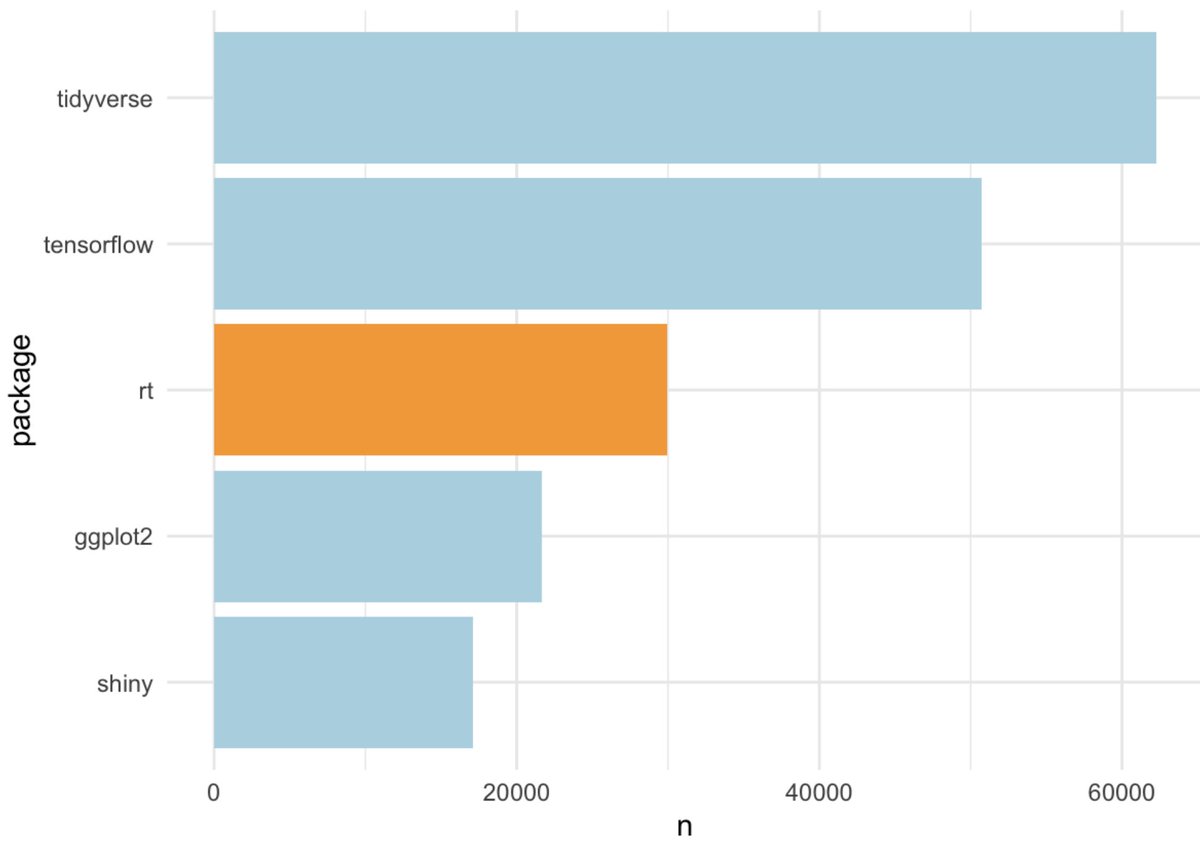
Let's filter out {rt} and see what we get!
Fun! Another data anomaly! Again, {usa} *is* an #rstats package, but a quick look at the tweets that include this shows that they are almost always referring to the country, not the package
Fun! Another data anomaly! Again, {usa} *is* an #rstats package, but a quick look at the tweets that include this shows that they are almost always referring to the country, not the package
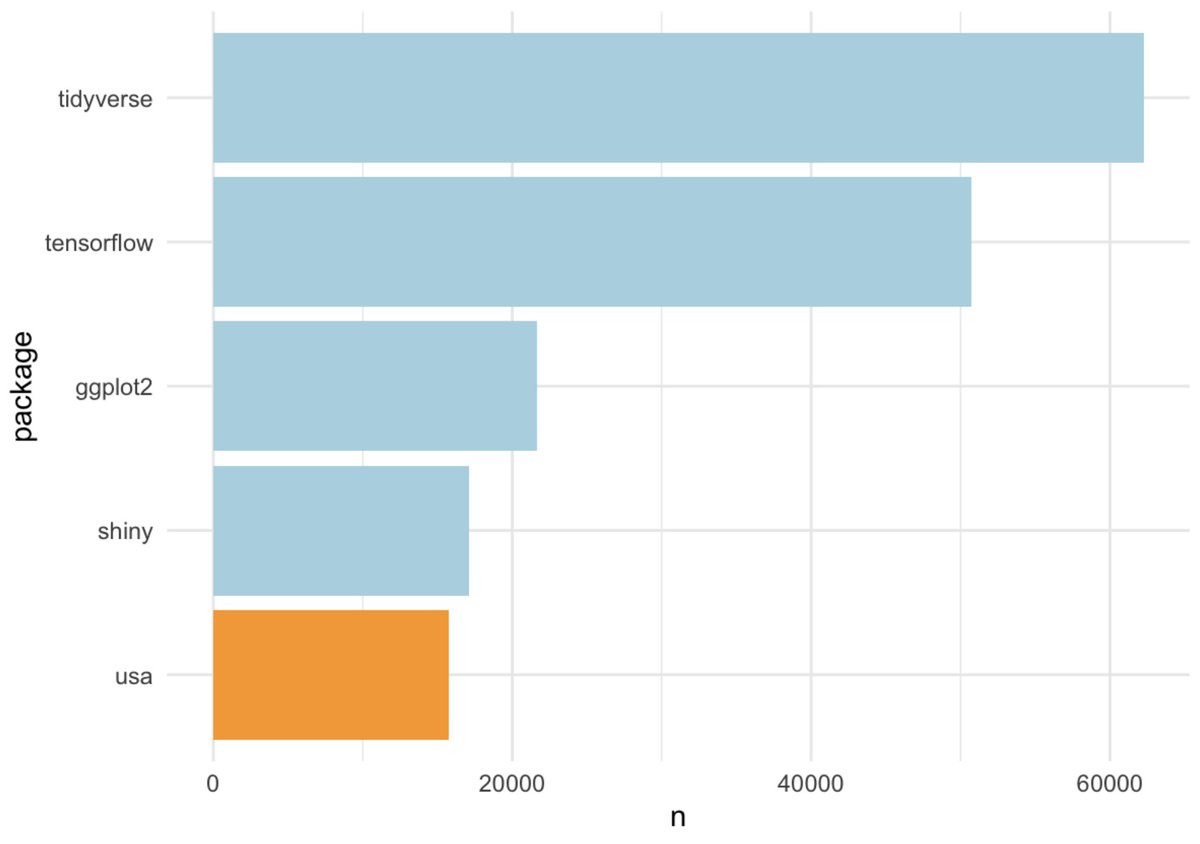
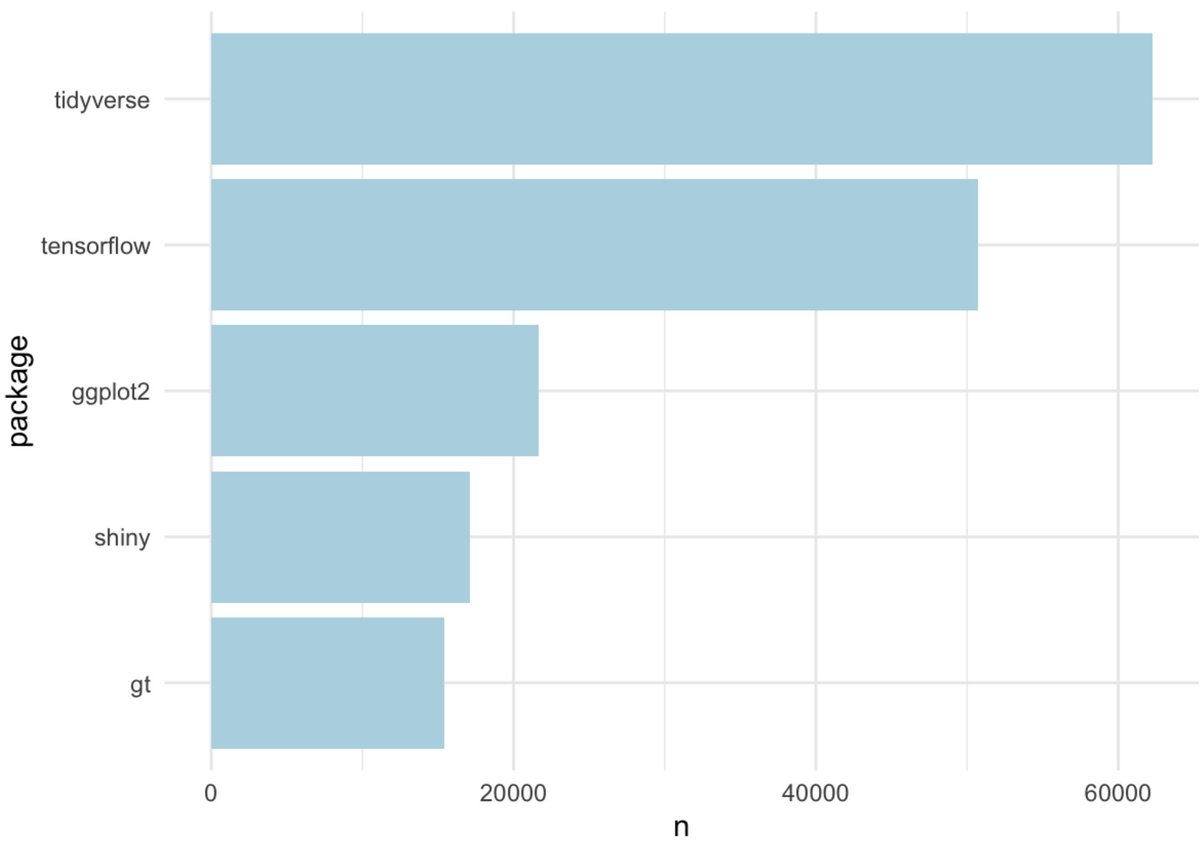
WHOA after filtering these out, we end up with the exact same 5 as we got using our sample from the past ~week with the order of the top two flipped. Sometimes sampling works!
🏆 Statistics is the real winner today!
🏆 Statistics is the real winner today!
• • •
Missing some Tweet in this thread? You can try to
force a refresh







