
We've been on a multi-year effort to take steps towards understanding how well NLP/language tech serves people on a *global* scale. Here's a first report: arxiv.org/abs/2110.06733
We perform meta-analysis of performance across 7 tasks, and devise "global utility" metrics. 1/7
We perform meta-analysis of performance across 7 tasks, and devise "global utility" metrics. 1/7


The idea is that language tech should serve every person in the world, not just English native speakers. Based on this, we come up with metrics for language-weighted and population-weighted performance that explicitly consider how many people or languages may benefit 2/7

We then collect performance metrics for seven different tasks, and calculate how well these tasks are doing to serve every language or every population. See some of the breakdowns in the attached figure. 3/7


This allows us to approximate how well a technology is serving potential users throughout the world. It also allows us to identify "pain points," languages that seem to be most underserved, based on our priorities with respect to equity of language or population coverage. 4/7

We also discuss some potential reasons behind current inequities, such as the economic or academic incentives that may cause technology for a particular language to be more or less researched. 5/7
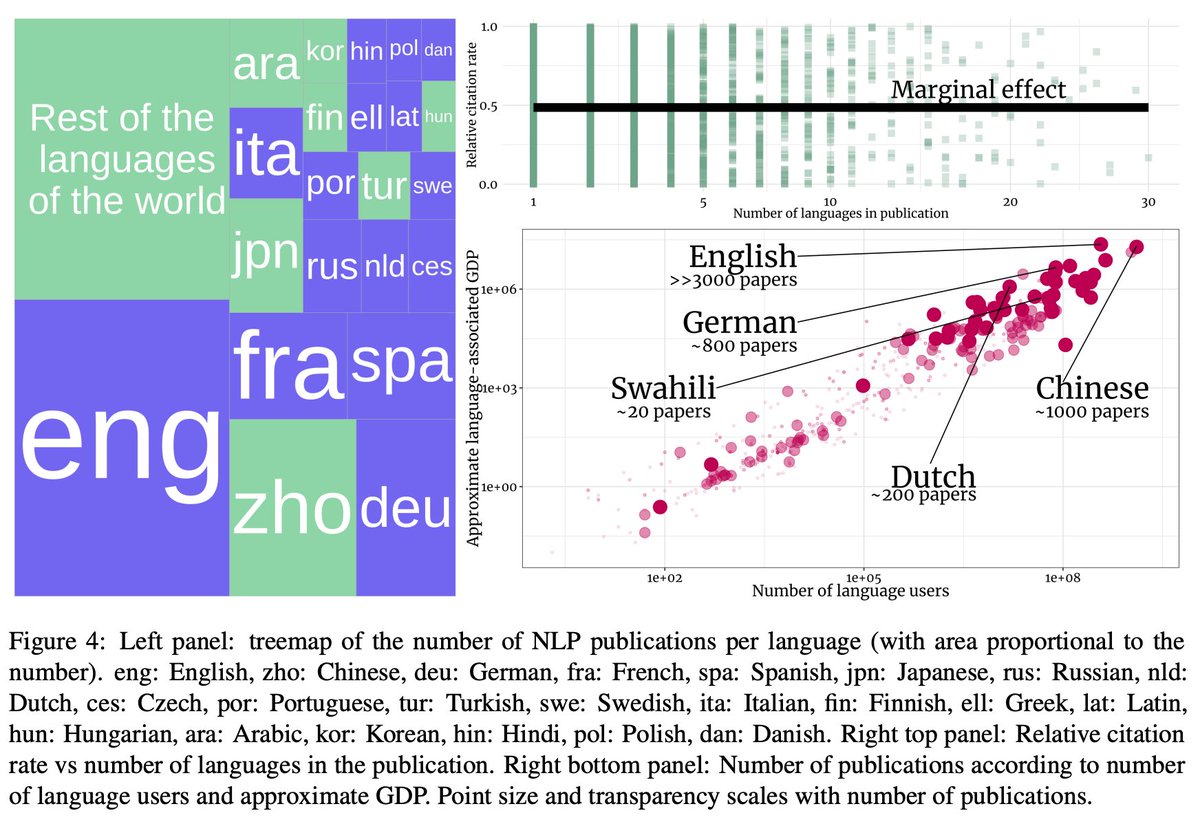
This is a tremendously difficult problem, and the current paper just scratched the surface (with many simplifying assumptions). Nonetheless we (@blasi_lang, @anas_ant, and me) hope this can start a dialog and focus attention/effort on improving technologies globally. 6/7
The overall project has just started and we would definitely love feedback and/or contributions from the broader community! 7/7
• • •
Missing some Tweet in this thread? You can try to
force a refresh














