Kaggle's 2021 State of Data Science and Machine Learning survey was released a few days ago.
If you didn't see it, here are some important takeaways 🧵
If you didn't see it, here are some important takeaways 🧵
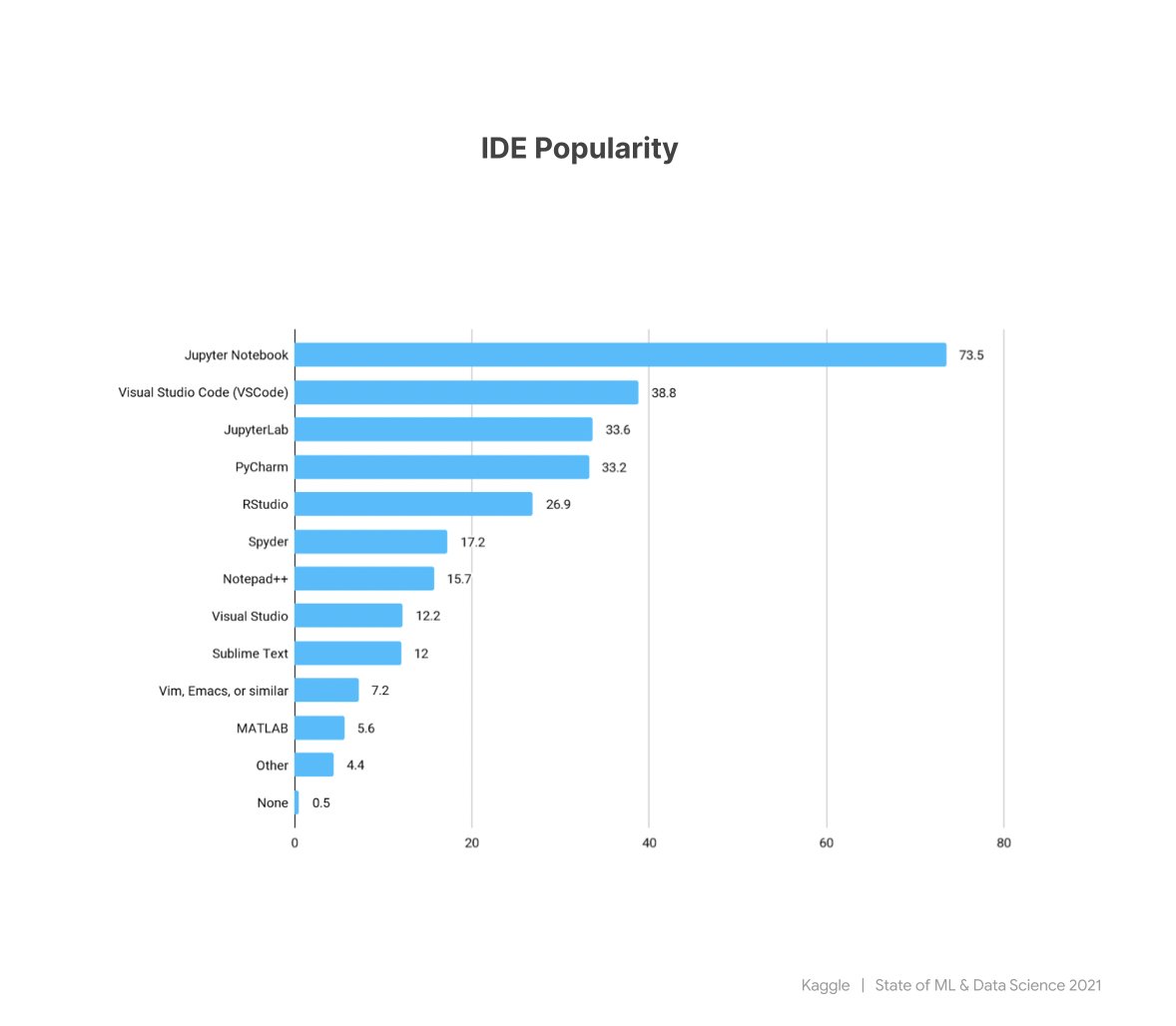
Top 5 IDEs
1. Jupyter Notebook
2. Visual Studio Code
3. JupyterLab
4. PyCharm
5. RStudio
1. Jupyter Notebook
2. Visual Studio Code
3. JupyterLab
4. PyCharm
5. RStudio
ML Algorithms Usage: Top 10
1. Linear/logistic regression
2. Decision trees/random forests
3. Gradient boosting machines(Xgboost, LightGBM)
5. Convnets
6. Bayesian approaches
7. Dense neural networks(MLPs)
8. Recurrent neural networks(RNNs)
9. Transformers(BERT, GPT-3)
10. GANs
1. Linear/logistic regression
2. Decision trees/random forests
3. Gradient boosting machines(Xgboost, LightGBM)
5. Convnets
6. Bayesian approaches
7. Dense neural networks(MLPs)
8. Recurrent neural networks(RNNs)
9. Transformers(BERT, GPT-3)
10. GANs

Machine Learning Tools Landscape - Top 8
1. Scikit-Learn
2. TensorFlow(tf.keras included)
3. XGBoost
4. Keras
5. PyTorch
6. LightGBM
7. CatBoost
8. Huggingface🤗
1. Scikit-Learn
2. TensorFlow(tf.keras included)
3. XGBoost
4. Keras
5. PyTorch
6. LightGBM
7. CatBoost
8. Huggingface🤗

Cloud Computing Tools - Top 3
1. AWS
2. GCP
3. Microsoft Azure
1. AWS
2. GCP
3. Microsoft Azure

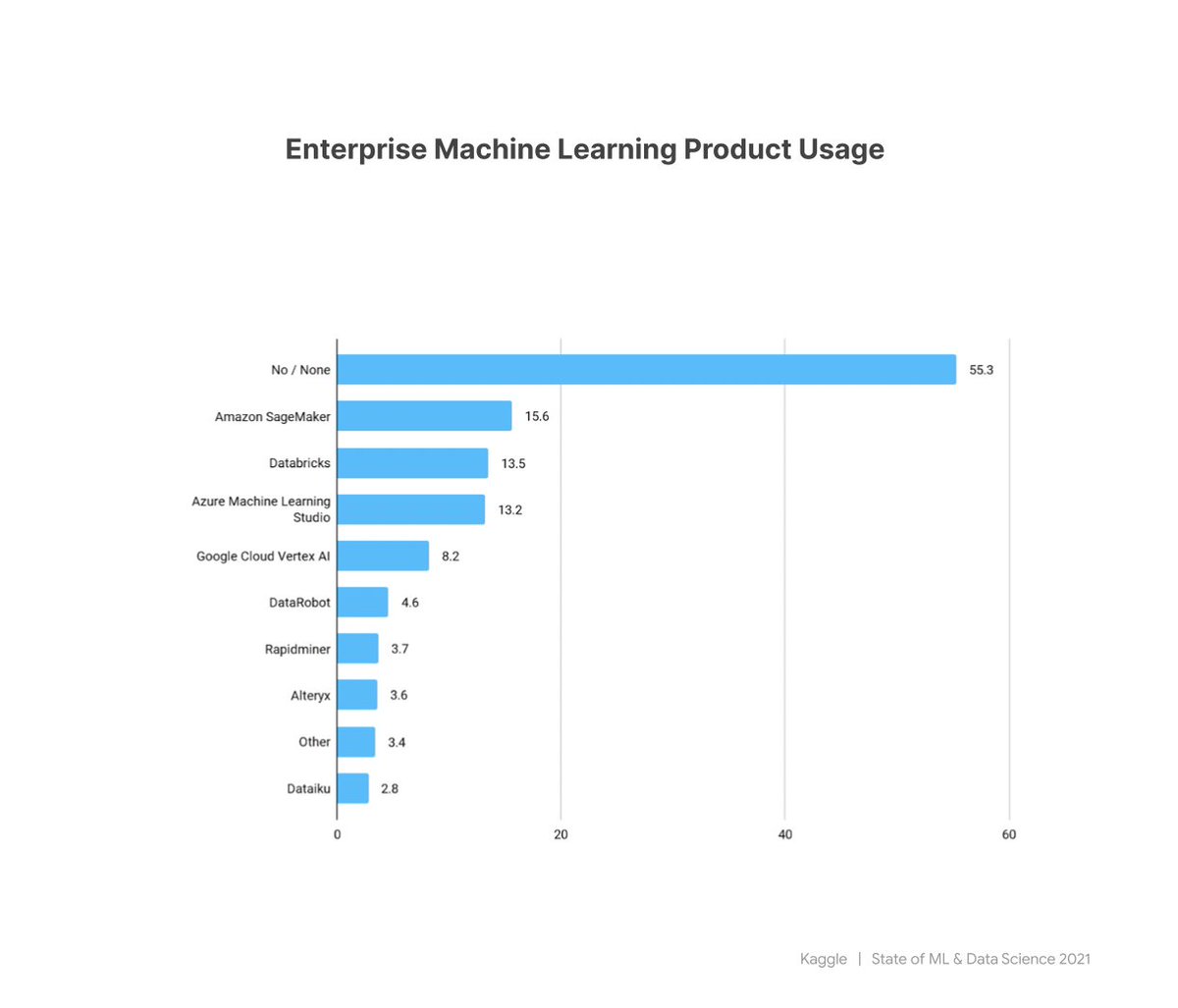
Enteprise ML Tools - Top 5
1. Amazon SageMaker
2. DataBricks
3. Asure ML Studio
4. Google Cloud Vertex AI
5. DataRobot
Notes: If you look at the graph, it seems that over half the number of the survey responders don't use those kinds of tools.
1. Amazon SageMaker
2. DataBricks
3. Asure ML Studio
4. Google Cloud Vertex AI
5. DataRobot
Notes: If you look at the graph, it seems that over half the number of the survey responders don't use those kinds of tools.
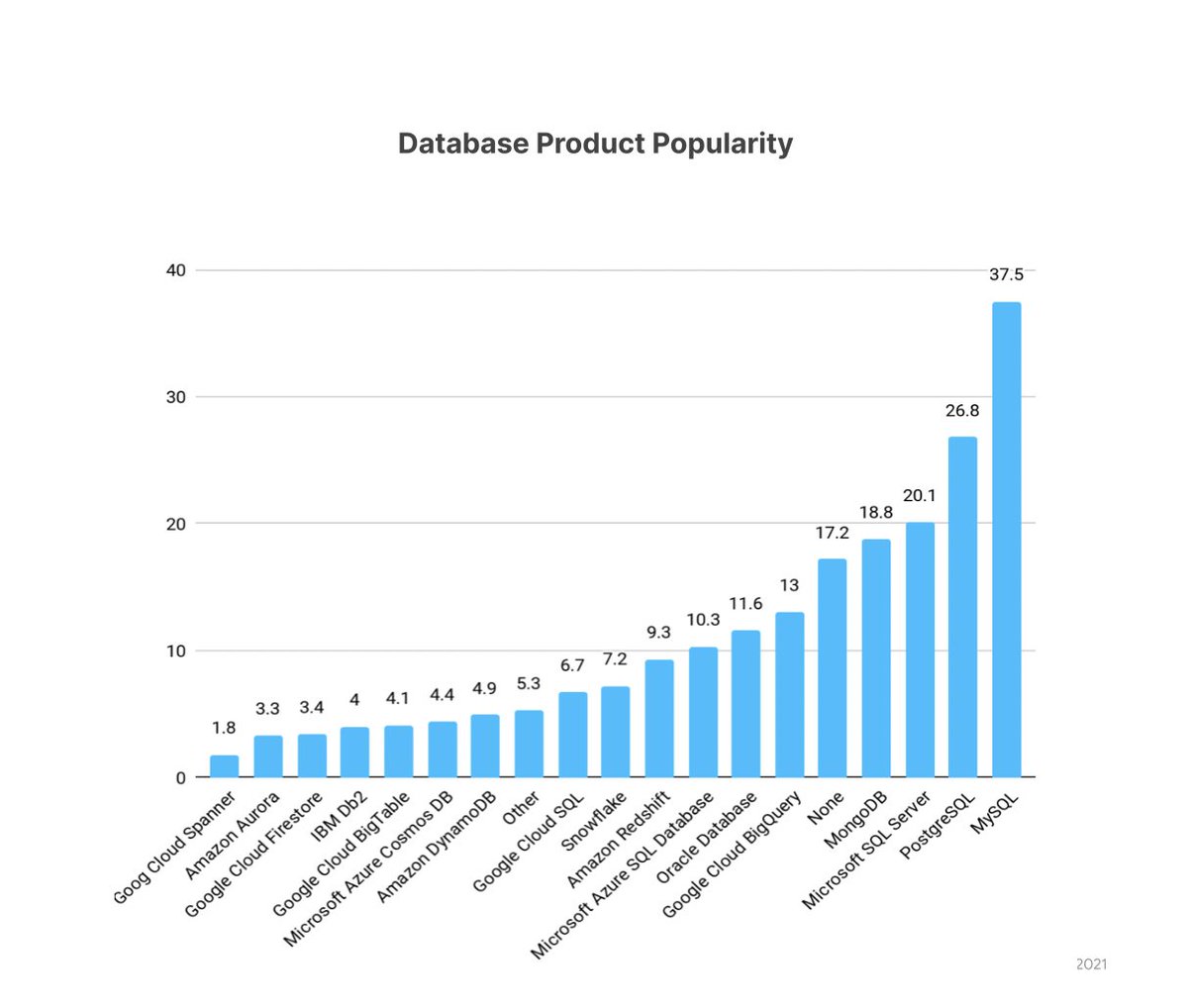
Databases - Top 4
1. MySQL
2. PostgreSQL
3. Microsoft SQL Server
4. MongoDB
1. MySQL
2. PostgreSQL
3. Microsoft SQL Server
4. MongoDB
Machine Learning Experimentation Tools - Top 4
1. TensorBoard
2. MLflow
3. Weights & Biases
4. Neptune.ai
Notes: Looking at the graph, the majority of Kagglers do not track their ML models. All eye on the leaderboard!
1. TensorBoard
2. MLflow
3. Weights & Biases
4. Neptune.ai
Notes: Looking at the graph, the majority of Kagglers do not track their ML models. All eye on the leaderboard!

AutoML Tools - Top 5
1. Google Cloud AutoML
2. Azure Automated ML
3. Amazon SageMaker Autopilot
4. H20 Driverless AI
5. Databricks AutoML
1. Google Cloud AutoML
2. Azure Automated ML
3. Amazon SageMaker Autopilot
4. H20 Driverless AI
5. Databricks AutoML

CONCLUSIONS:
1. Notebooks are still the most appreciated way of experimenting with ML. If you never did it, try them in VSCode.
2. Scikit-Learn is ahead of the game
3. All you need is XGBoost(CC: @tunguz)
4. No need for model tracking on Kaggle. There is a leaderboard
1. Notebooks are still the most appreciated way of experimenting with ML. If you never did it, try them in VSCode.
2. Scikit-Learn is ahead of the game
3. All you need is XGBoost(CC: @tunguz)
4. No need for model tracking on Kaggle. There is a leaderboard
• • •
Missing some Tweet in this thread? You can try to
force a refresh