NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
abs: arxiv.org/abs/2111.12417
presents a unified multimodal pretrained model that can generate new or manipulate existing visual data (i.e., images and videos) for various visual synthesis tasks
abs: arxiv.org/abs/2111.12417
presents a unified multimodal pretrained model that can generate new or manipulate existing visual data (i.e., images and videos) for various visual synthesis tasks


NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, etc. Furthermore, it also shows surprisingly good zero-shot capabilities on text-guided image and video manipulation tasks 

Sketch-to-Video (S2V)
Text-Guided Video Manipulation (TV2V)
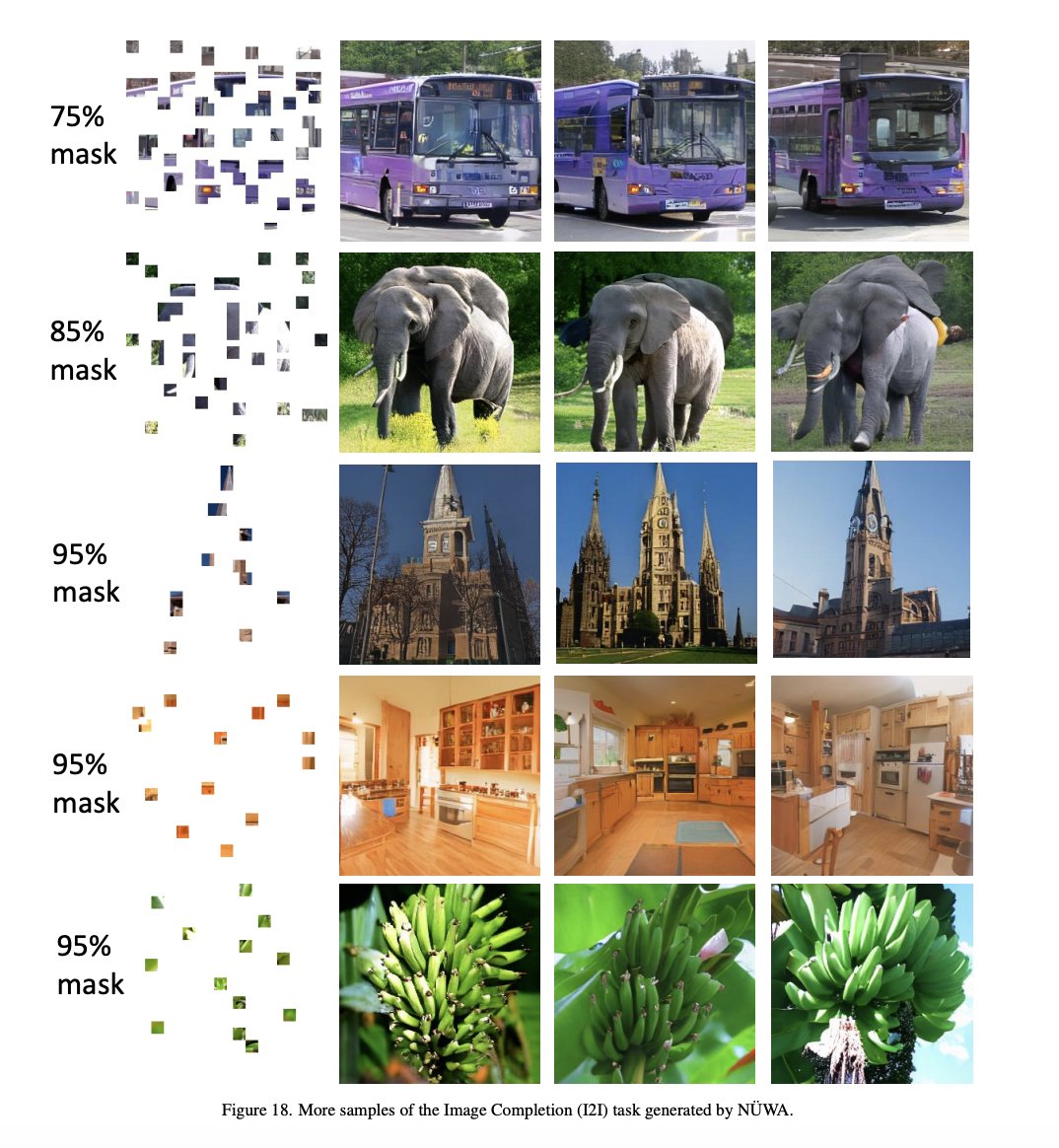
Image Completion (I2I)

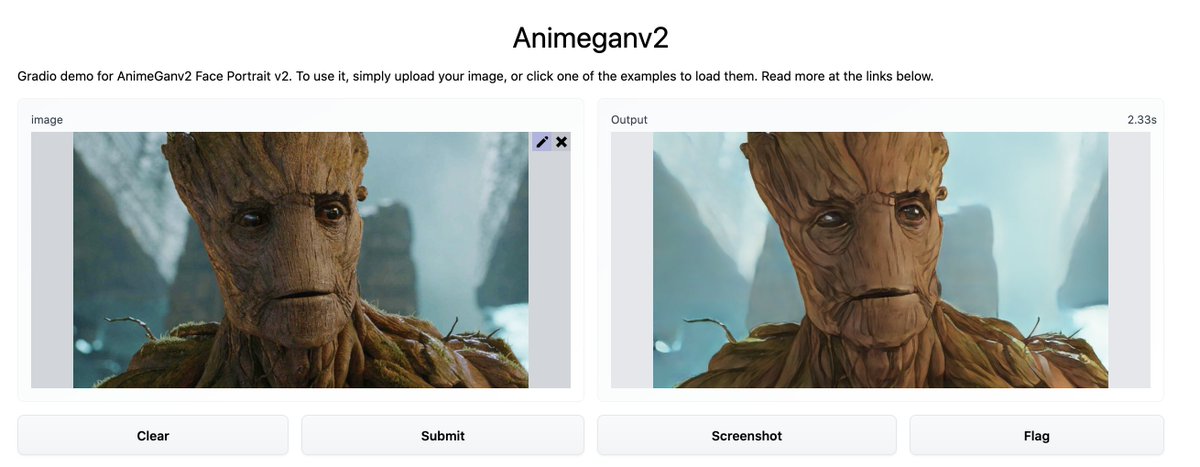
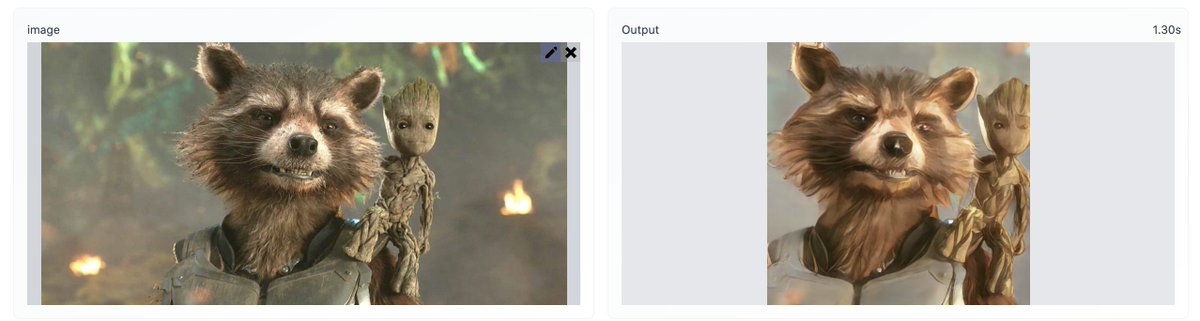
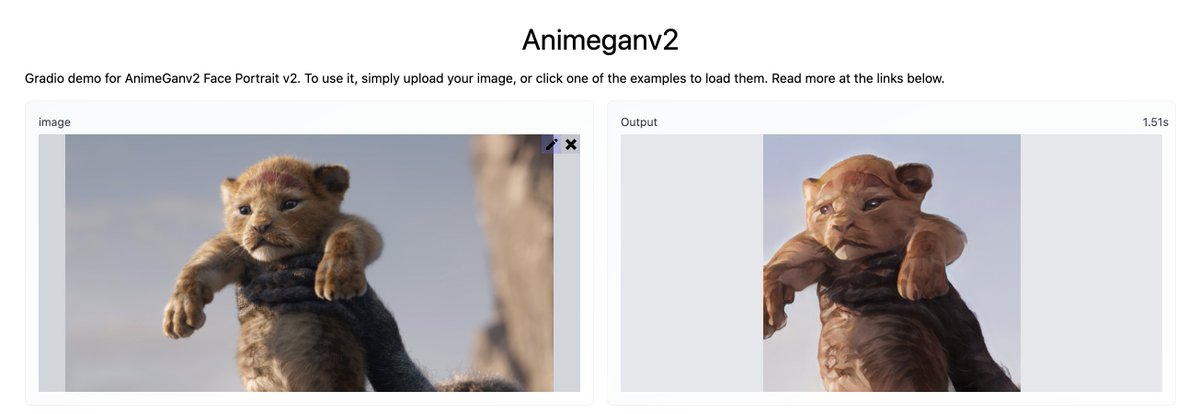
Text-Guided Image Manipulation (TI2I)

github: github.com/microsoft/NUWA
Text-to-Image

Sketch to Image

Sketch to Image

Image Completion

Image Completion
research talk:
• • •
Missing some Tweet in this thread? You can try to
force a refresh