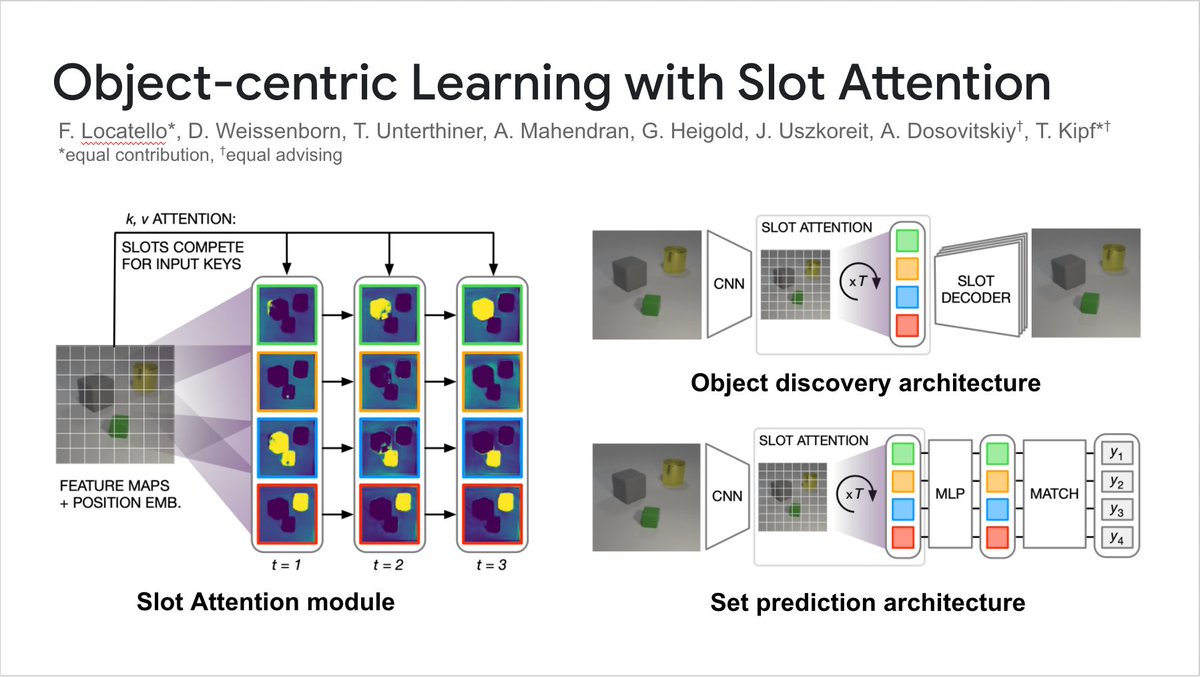
Excited to share our work on Conditional Object-Centric Learning from Video!
We introduce SAVi, a slot-based model that can discover + represent visual entities in videos, using simple location cues and object motion (...or entirely unsupervised)
🖥️ slot-attention-video.github.io
1/7
We introduce SAVi, a slot-based model that can discover + represent visual entities in videos, using simple location cues and object motion (...or entirely unsupervised)
🖥️ slot-attention-video.github.io
1/7
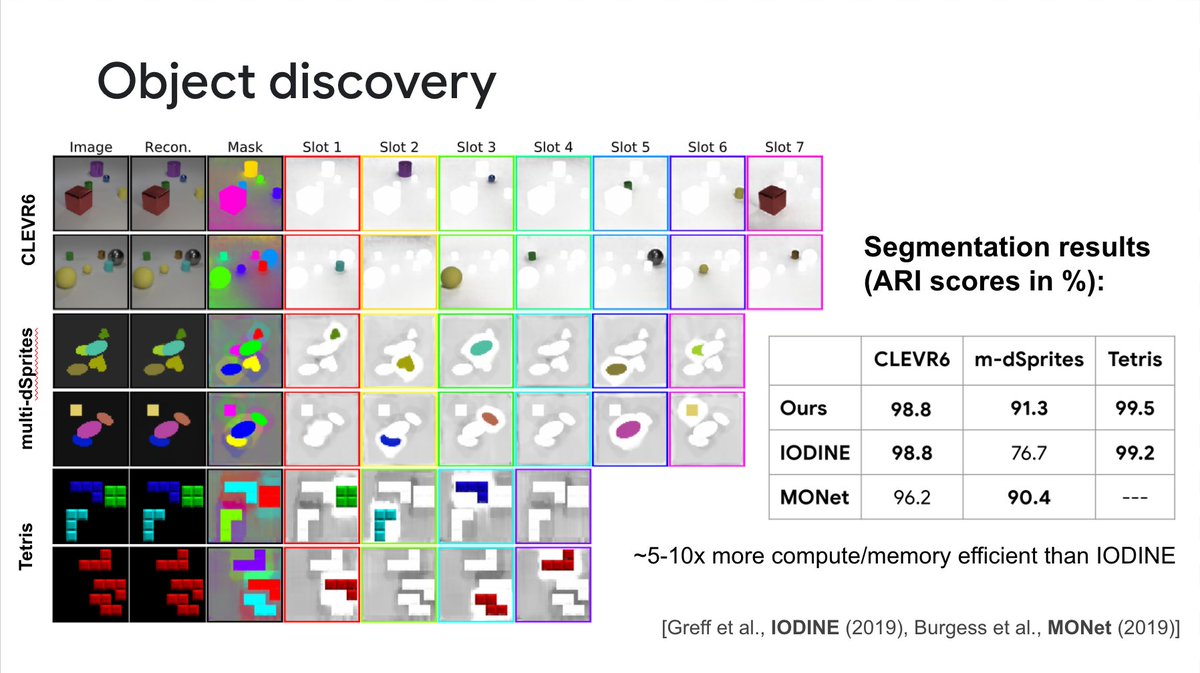
When trained entirely unsupervised (by simply reconstructing the input video), SAVi learns to decompose videos into meaningful entities, such as objects or parts that move independently.
While this works on (simple) real data, such as in this robotic grasping environment...
2/7
While this works on (simple) real data, such as in this robotic grasping environment...
2/7
...bridging the gap to visually more complex scenes with diverse textures is a challenge, esp. since the notion of an object can often be ambiguous.
Simple cues, such as points on objects in the first frame, and predicting motion (optical flow) can break this ambiguity...
3/7
Simple cues, such as points on objects in the first frame, and predicting motion (optical flow) can break this ambiguity...
3/7
...and allow SAVi to decompose, segment, and track moving objects in visually far more complicated environments, using real-world backgrounds and realistic household objects -- without receiving explicit supervision for this task.
Caveat: this only works for moving objects.
4/7
Caveat: this only works for moving objects.
4/7
Conditioning the slots of SAVi on external context / cues gives us an interface for the model at test time:
This allows SAVi to decompose scenes at different hierarchy levels (e.g. objects/parts), depending on which context (in the form of conditioning signals) is provided.
5/7
This allows SAVi to decompose scenes at different hierarchy levels (e.g. objects/parts), depending on which context (in the form of conditioning signals) is provided.
5/7

Check out our paper to learn more about the model & find many more experiments/results!
Paper: arxiv.org/abs/2111.12594
Project page: slot-attention-video.github.io
Scaling slot-based NNs to diverse real-world data with minimal supervision is an exciting challenge for future work.
6/7
Paper: arxiv.org/abs/2111.12594
Project page: slot-attention-video.github.io
Scaling slot-based NNs to diverse real-world data with minimal supervision is an exciting challenge for future work.
6/7

Joint work w/ amazing collaborators in the Brain Team at Google Research & Robotics at Google: @gamaleldinfe, Aravindh Mahendran, Austin Stone, @sabour_sara, Georg Heigold, @rico_jski, Alexey Dosovitskiy & Klaus Greff
7/7
7/7
• • •
Missing some Tweet in this thread? You can try to
force a refresh