
#NeurIPS2021 spotlight: Optimal policies tend to seek power.
Consider Pac-Man: Dying traps Pac-Man in one state forever, while staying alive lets him do more things. Our theorems show that for this reason, for most reward functions, it’s optimal for Pac-Man to stay alive. 🧵:
Consider Pac-Man: Dying traps Pac-Man in one state forever, while staying alive lets him do more things. Our theorems show that for this reason, for most reward functions, it’s optimal for Pac-Man to stay alive. 🧵:
We show this formally through *environment symmetries*. In this MDP, the visualized state permutation ϕ shows an embedding of the “left” subgraph into the “right” subgraph. The upshot: Going “right” leads to more options, and more options -> more ways for “right” to be optimal. 

We provide the first formal theory of the statistical incentives of optimal policies, which applies to all MDPs with environment symmetries. Besides showing that keeping options is more likely, we also show it is more powerful. Thus, “optimal policies tend to seek power.”
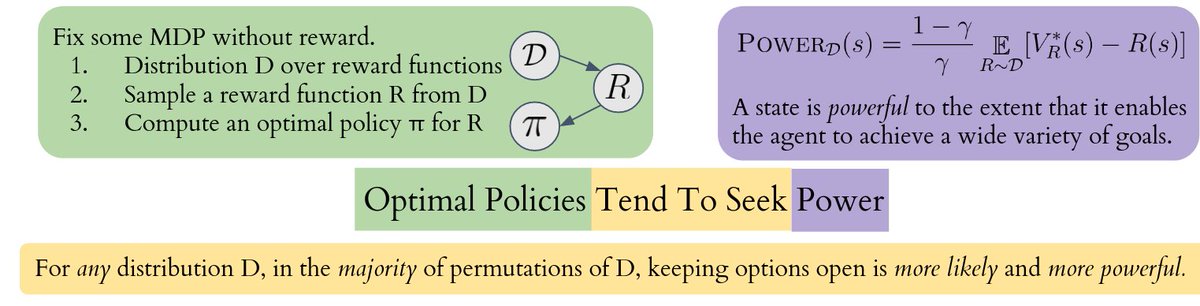
This lesson generalizes. It might be very, very hard to design intelligent real-world AI systems which let us deactivate and correct them. If, statistically, most goals don’t incentivize that behavior, then our goals would conflict with the goals of most smart AI agents.
Paper: arxiv.org/abs/1912.01683
NeurIPS recorded presentation: neurips.cc/virtual/2021/p…
NeurIPS poster session: Tomorrow, Tue 7 Dec 8:30 a.m. PST, spot D3 in eventhosts.gather.town/app/sX430NSSjB…
Series of blog posts on this line of work: alignmentforum.org/s/fSMbebQyR4wh…
NeurIPS recorded presentation: neurips.cc/virtual/2021/p…
NeurIPS poster session: Tomorrow, Tue 7 Dec 8:30 a.m. PST, spot D3 in eventhosts.gather.town/app/sX430NSSjB…
Series of blog posts on this line of work: alignmentforum.org/s/fSMbebQyR4wh…
• • •
Missing some Tweet in this thread? You can try to
force a refresh


