
#30DaysOfJAX Day 4
So far I learned how JAX.numpy can be converted to XLA ops using Lax lower level API
But where is Jit in all of this?
[this is cool but hard, grab a coffee! ☕️]
1/12🧵
So far I learned how JAX.numpy can be converted to XLA ops using Lax lower level API
But where is Jit in all of this?
[this is cool but hard, grab a coffee! ☕️]
1/12🧵
Even with JAX operations being compiled to run using XLA, they are still executed one at a time in a sequence.
Can we do better?
Yes, Compiling it!🤯
2/12🧵
Can we do better?
Yes, Compiling it!🤯
2/12🧵
Compilers are great pieces of software and one the magics🪄 they do is to look into your code and creating an optimized faster version by, for example:
• fusing ops ➕
• not allocating temp variables 🚫🗑️
3/12🧵
• fusing ops ➕
• not allocating temp variables 🚫🗑️
3/12🧵
Python is not a compiled language! And this is where Just in time compilations can be used!
When a function is decorated with the jit decorator, that part of the code will be compiled when it's executed for the first time!
Here is a 3.5x improvement!
⚡️⚡️⚡️
4/12🧵
When a function is decorated with the jit decorator, that part of the code will be compiled when it's executed for the first time!
Here is a 3.5x improvement!
⚡️⚡️⚡️
4/12🧵

One question I always ask when I learn about this kind of speed improvement is:
-> Why don't we use it for every function ever and all the time???
jax.jit has some limitations: All arrays must have static shapes
Can you point out the error in the image?
🤔❓❔
5/12🧵
-> Why don't we use it for every function ever and all the time???
jax.jit has some limitations: All arrays must have static shapes
Can you point out the error in the image?
🤔❓❔
5/12🧵

The problem with the get_negatives function is that the shape of the returned array is not known at compile time! It changes with the input!
Let's understand that a little bit better and add two important concepts: tracing and static variables
6/12🧵
Let's understand that a little bit better and add two important concepts: tracing and static variables
6/12🧵
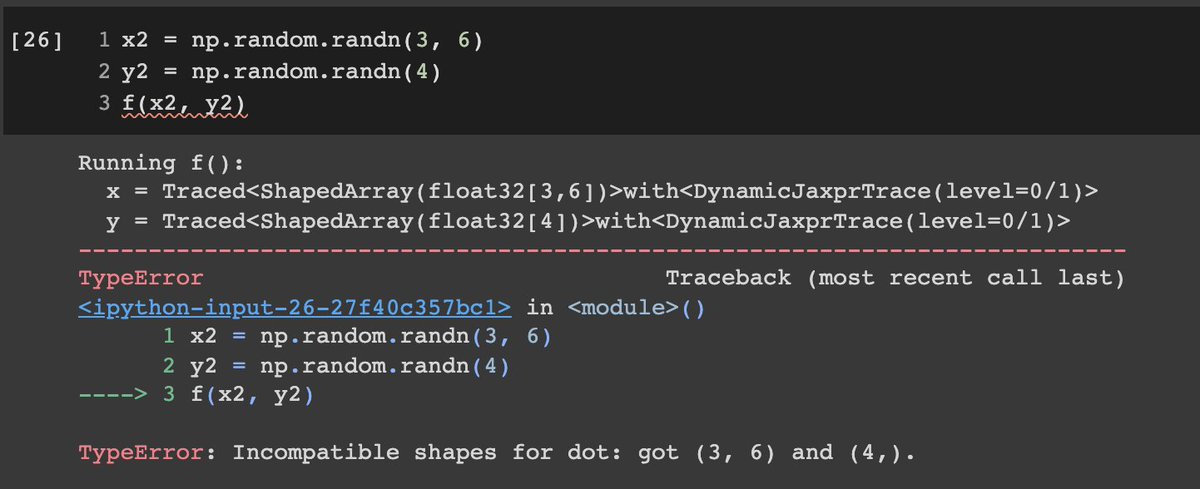
When you use the jit decorator, JIT will run (trace) your function and try to understand its effects on the inputs regarding shape and types using tracer objects
For example, you can see in the code below that the printing disappears these ops are discarded
7/12🧵
For example, you can see in the code below that the printing disappears these ops are discarded
7/12🧵

Next time, when your function is run again with the same input shape and type, it will use the compiled version.
If you change type or shape, the function will throw an exception
8/12🧵
If you change type or shape, the function will throw an exception
8/12🧵
You can even inspect the code that is generated by the decorator using make_jaxpr
9/12🧵
9/12🧵

But what can you do when you don't want your variable to be traced?
You can mark it as static
It will leave it un-traced but it's value will be evaluated at compile time
When this value changes, the function is re-compiled
10/12🧵
You can mark it as static
It will leave it un-traced but it's value will be evaluated at compile time
When this value changes, the function is re-compiled
10/12🧵

When you need operations that will keep changing (size/data type)
Use np.numpy, otherwise jax.numpy
This is one of the reasons that you won't just use: import jax.numpy as np!!!
11/12🧵
Use np.numpy, otherwise jax.numpy
This is one of the reasons that you won't just use: import jax.numpy as np!!!
11/12🧵
Summary: Jit can make your code much faster taking advantage of the powers of compilation but sometimes it won't work! Understanding how tracing and static variables work is key to leveraging Jit!
JAX, Jit, tracing! I'm starting to understand why people like it! 🧐🤓
12/12🧵
JAX, Jit, tracing! I'm starting to understand why people like it! 🧐🤓
12/12🧵
For the full code of this thread and previous one:
the colab.sandbox.google.com/github/google/…
I highly recommend doing it and making changes to really get the details!
the colab.sandbox.google.com/github/google/…
I highly recommend doing it and making changes to really get the details!
• • •
Missing some Tweet in this thread? You can try to
force a refresh











