
DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning
SSL is a promising technology, but current methods are field-specific. Can we find general algorithms that can be applied to any domain?
🌐: dabs.stanford.edu
📄: arxiv.org/abs/2111.12062
🧵👇 #NeurIPS2021
1/
SSL is a promising technology, but current methods are field-specific. Can we find general algorithms that can be applied to any domain?
🌐: dabs.stanford.edu
📄: arxiv.org/abs/2111.12062
🧵👇 #NeurIPS2021
1/

Self-supervised learning (SSL) algorithms can drastically reduce the need for labeling by pretraining on unlabeled data
But designing SSL methods is hard and can require lots of domain-specific intuition and trial and error
2/
But designing SSL methods is hard and can require lots of domain-specific intuition and trial and error
2/
We designed DABS to drive progress in domain-agnostic SSL
Our benchmark addresses three core modeling components in SSL algorithms:
(1) architectures
(2) pretraining objectives
(3) transfer methods
3/
Our benchmark addresses three core modeling components in SSL algorithms:
(1) architectures
(2) pretraining objectives
(3) transfer methods
3/
1) Architectures:
Most models are designed for particular modalities (e.g. ResNets for images)
But Transformers have recently been applied to many settings, and Perceivers are even more general
What architectures are general, efficient, and learn the best representations?
4/
Most models are designed for particular modalities (e.g. ResNets for images)
But Transformers have recently been applied to many settings, and Perceivers are even more general
What architectures are general, efficient, and learn the best representations?
4/
2) Pretraining objectives:
We currently have domain-specific ways to extract signal from unlabeled data
Language modeling prevails in NLP, while contrastive learning is more common in vision
Can we uncover unifying principles and methods that work well on any domain?
5/
We currently have domain-specific ways to extract signal from unlabeled data
Language modeling prevails in NLP, while contrastive learning is more common in vision
Can we uncover unifying principles and methods that work well on any domain?
5/
3) Transfer learning
Full finetuning, linear evaluation, p/prompt/prefix tuning… there's a whole range of techniques to adapt models to downstream tasks.
Do these work equally well across domains? What are the tradeoffs, and do better methods exist?
6/
Full finetuning, linear evaluation, p/prompt/prefix tuning… there's a whole range of techniques to adapt models to downstream tasks.
Do these work equally well across domains? What are the tradeoffs, and do better methods exist?
6/
Datasets & Domains
DABS is organized into 7 domains: natural images, speech, English-language text, multilingual text, wearable sensors, chest x-rays, and images w/ text descriptions.
Each domain has an unlabeled dataset for pretraining and downstream datasets for transfer
7/
DABS is organized into 7 domains: natural images, speech, English-language text, multilingual text, wearable sensors, chest x-rays, and images w/ text descriptions.
Each domain has an unlabeled dataset for pretraining and downstream datasets for transfer
7/
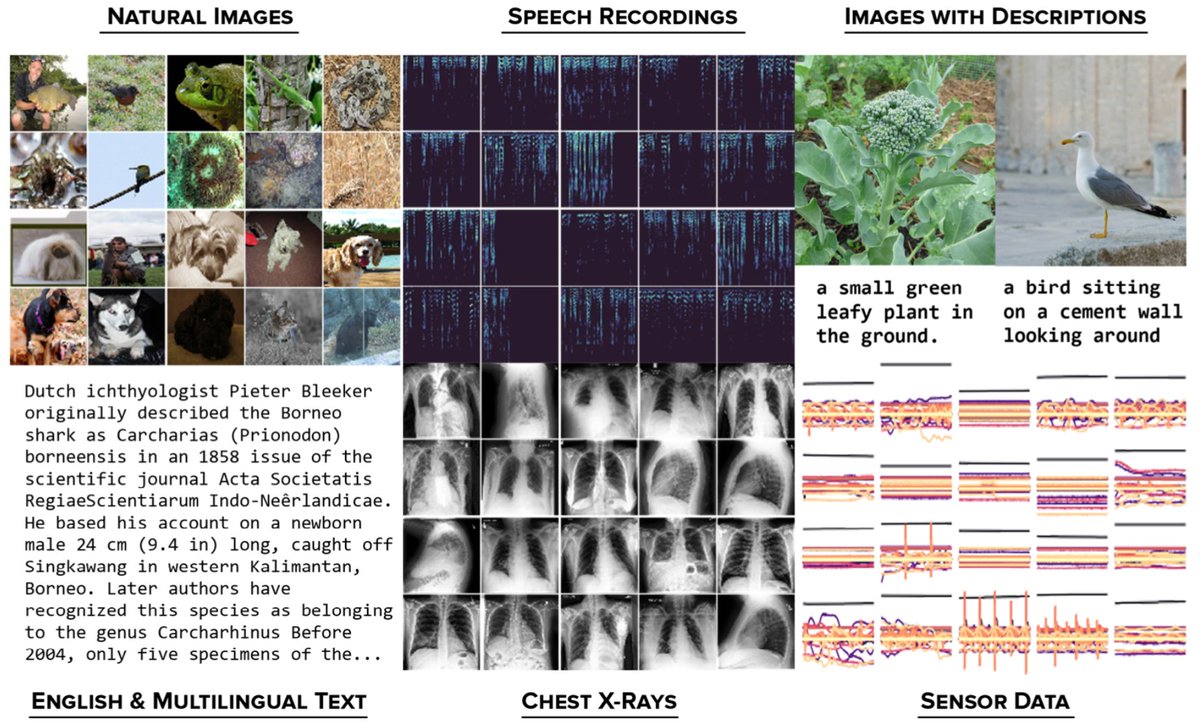
The goal is to find a *single* SSL algorithm that performs well across all of these domains
We kick off the challenge with two new baselines using transformers, where the pretraining objectives are based on the input embeddings. There's a lot of headroom left!
8/
We kick off the challenge with two new baselines using transformers, where the pretraining objectives are based on the input embeddings. There's a lot of headroom left!
8/

To assess real-world generalization, DABS is a *living benchmark*—
We'll be adding additional domains focusing on scientific and other real-world applications
Proposed algorithms will be tested on these new domains to see how well they hold up
9/
We'll be adding additional domains focusing on scientific and other real-world applications
Proposed algorithms will be tested on these new domains to see how well they hold up
9/
We hope DABS helps yield new insights about why / when SSL works, and helps make it a more mature technology that can be used off-the-shelf in scientific, medical, and other high-impact fields
10/
10/
Also—If you're a domain expert interested in adding a domain for your field (unlabeled dataset + labeled downstream tasks), please reach out!
11/
11/
This is joint work w/ Vincent Liu, Rongfei Lu, Daniel Fein, Colin Schultz, and Noah Goodman! @StanfordAILab @stanfordnlp
Stop by our #NeurIPS2021 poster on Friday, 8:30–10am PST 👋
neurips.cc/virtual/2021/p…
12/
Stop by our #NeurIPS2021 poster on Friday, 8:30–10am PST 👋
neurips.cc/virtual/2021/p…
12/
• • •
Missing some Tweet in this thread? You can try to
force a refresh





