
Tip: when expanding an Xcode XIP archive, use the command line (xip --expand) rather than Archive Utility. It’s at least 25% faster–sometimes even twice as fast, depending on the circumstances. They both call into the Bom API, so I profiled both to see why there’s a difference.
Decompressing a XIP is fairly straightforward: Bom runs file operations (which don’t generally benefit from parallelization) on one main thread and then spawns worker threads as necessary for CPU-bound tasks. The most obvious one is decompression, of course. 

Xcode is massive–it’s over half a million files. Its XIP is more than 10 GB, and if fully expanded on disk it’d take up over 30 GB of space. Fortunately, it doesn’t have to be: APFS supports transparent compression, and Apple has marked most of the bundle as being able to use it.
Xcode is massive–it’s over half a million files. Its XIP is more than 10 GB, and if fully expanded on disk it’d take up over 30 GB of space. Fortunately, it doesn’t have to be: APFS supports transparent compression, and Apple has marked most of the bundle as being able to use it.
This feature lets Xcode use less than 20 GB of space on-disk if extracted properly, which both the command line and GUI tools do. (Sadly, Archive Utility’s free space check uses the full, uncompressed size, so it will often reject the archive even when there’s plenty of space.)
Anyways, the decompression process for a XIP is fairly straightforward: read files out from the XIP’s LZMA stream, recompress them with LZFSE if possible, then write them to disk. The compression is handled by AppleFSCompression, and it’s more than happy to parallelize the task.
That’s what all the worker threads are doing, by the way. But if you have even a handful of CPU cores you’ll notice it has a really hard time keeping all of them busy. The bottleneck is *not* the actual de- and re-compression, but writing out the files to disk!

Specifically, it’s the creation of those half a million files that really hurts overall performance. The “driver” thread is unable to create files fast enough to keep the worker thread pool busy doing actual work on the CPU, because it’s blocked by file operations in the kernel.
Part of this time, of course, is waiting to write to disk. But SSDs are fast, and the thread is still using a lot of CPU time. What’s it doing? Well, a lot of it is APFS bookkeeping, which is slow but not particularly surprising to encounter. But there’s some more going on…
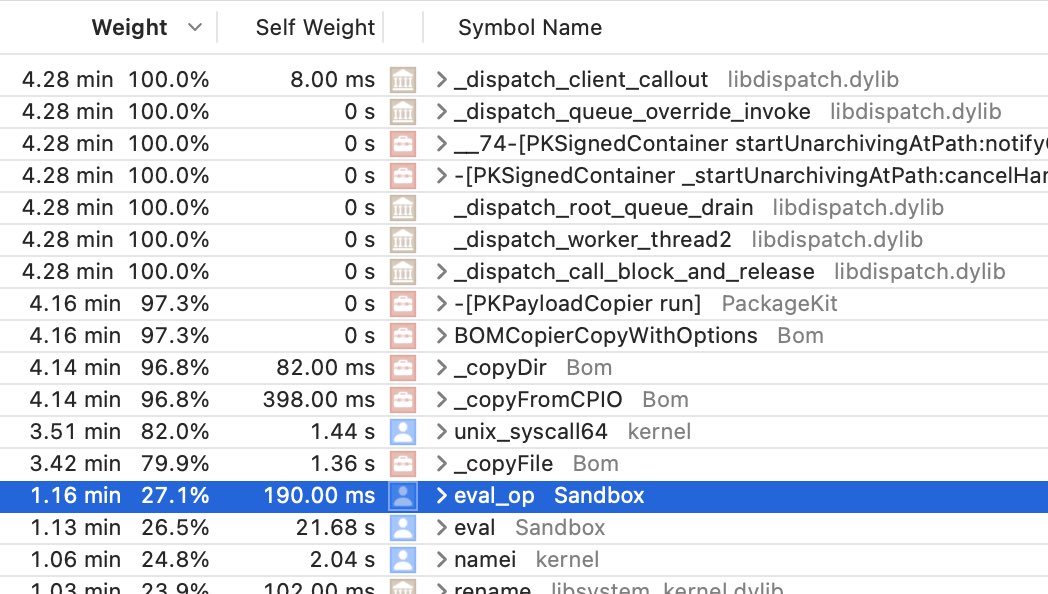
Before any system call even has a chance to touch the disk, macOS needs to make sure that it has permission to do so. In this case all the accesses will succeed, but the kernel still needs to check, and it asks Sandbox.kext to do so. A policy is evaluated to verify the access.
How expensive is this evaluation? Pretty expensive, it turns out. Filesystem operations might spend up to 30% of their time on CPU just evaluating sandbox policies! And all of these run synchronously on that one thread, so they block everything else from proceeding.
Why is xip faster? First, it’s a command line tool, rather than a GUI app. macOS throttles apps that are obscured or minimized after a while, which pretty much everyone does to Archive Utility and can easily make the process take twice as long.
Secondly, I found that xip consistently spent less time in Sandbox evaluation. I can’t be sure why, but my guess is that it has a simpler profile (it’s basically unsandboxed…) so the policy might be simpler to check. All other things being equal, it’s still 25% faster overall.
Plus, you might get to skip this:
Since Xcode expansion is kernel-bound, an amusing test might be to try decompressing it on Linux and seeing how it compares. My impression is that they care more about filesystem performance, but it’d be interesting to see how it fares.
(This thread broke my Twitter client–the repeated tweet is just an artifact of that.)
• • •
Missing some Tweet in this thread? You can try to
force a refresh





