
A #network administrator's worst nightmare can be intermittent network congestion - it's impossible to predict, short-lived, and has major impact. Can #Python help us find and fix it?
Let's find out! 🧵
Prefer a blog post format? Click here: chrisjhart.com/Practical-Pyth…
Let's find out! 🧵
Prefer a blog post format? Click here: chrisjhart.com/Practical-Pyth…
A case I've seen in TAC is where customers observe intermittently incrementing input discard counters on interfaces of a Nexus 5500 switch. This is usually followed by reports of connectivity issues, packet loss, or application latency for traffic flows traversing the switch. 

Oftentimes, this issue is highly intermittent and unpredictable. Once every few hours (or sometimes even days), the input discards will increment over the course of a few dozen seconds, then stop.
First, let's explore what input discards mean, the challenges with troubleshooting this intermittent issue manually, and how we can use Python to help troubleshoot.
Cisco Nexus 5000, 6000, and 7000 switches utilize a Virtual Output Queue (VOQ) queuing architecture for unicast traffic.
This means as a packet enters the switch, it:
1. Parses packet headers
2. Determines the packet's egress interface (forwarding decision)
3. Buffers the packet on the ingress interface in a virtual queue (VQ) for the egress interface until the interface can transmit the packet
1. Parses packet headers
2. Determines the packet's egress interface (forwarding decision)
3. Buffers the packet on the ingress interface in a virtual queue (VQ) for the egress interface until the interface can transmit the packet
An interface becomes congested when the total sum of traffic that needs to be transmitted out of the interface exceeds the bandwidth of the interface itself.
For example, let's say that Ethernet1/1, Ethernet1/2, and Ethernet1/3 of a switch are all interfaces with 10Gbps of bandwidth.
Let's also say that 7.5Gbps of traffic ingresses the switch through Ethernet1/1, and 7.5Gbps of traffic ingresses the switch through Ethernet1/2.
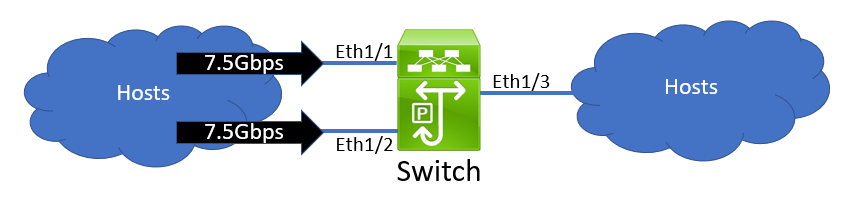
All 15Gbps of this traffic needs to egress Ethernet1/3. However, Ethernet1/3 is a 10Gbps interface; it can only transmit up to 10Gbps of traffic at once. Therefore, the excess 5Gbps of traffic *must* be buffered by the switch.
This traffic will be buffered at the ingress interfaces (Ethernet1/1 and Ethernet1/2) within a virtual queue that represents Ethernet1/3.
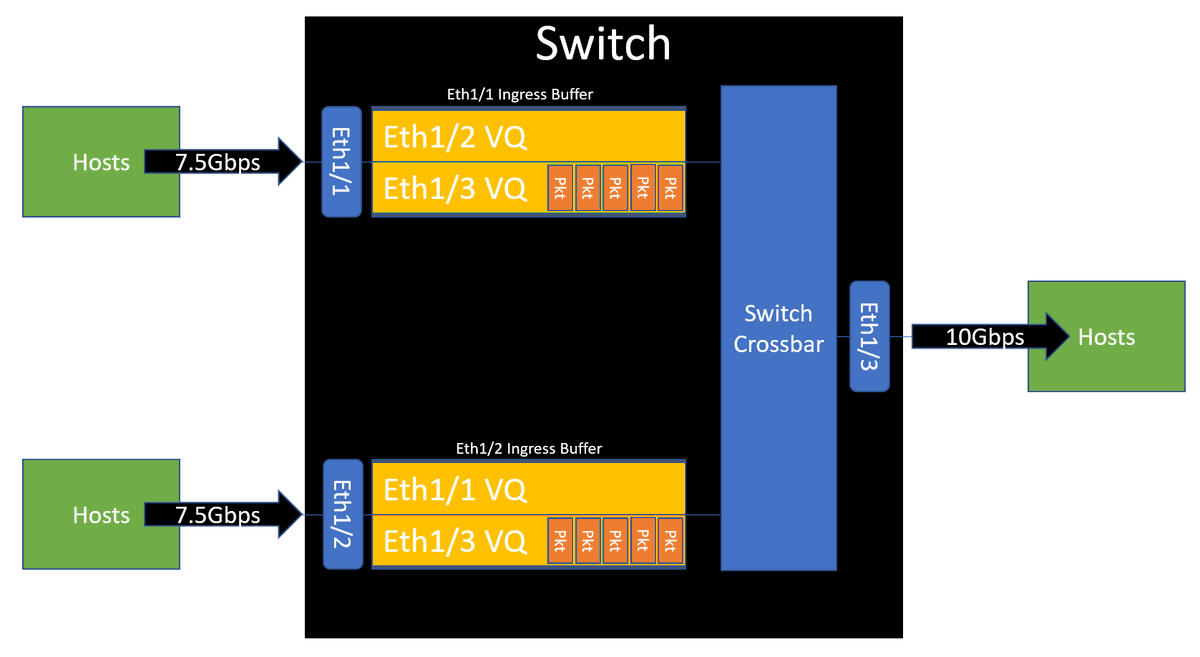
If Ethernet1/3 remains congested for a "long" period of time, then the virtual queue for Ethernet1/3 on the ingress buffer of Ethernet1/1 and Ethernet1/2 will become full, and the switch will not be able to accept new packets destined to Ethernet1/3.
Additional packets are then dropped on ingress, and the "input discards" counter is incremented on the ingress interface (Ethernet1/1 and Ethernet1/2). It's important to note that no counter will be incremented on the congested egress interface.
The word "long" is purposefully ambiguous because it is subjective. Within a matter of milliseconds, an egress interface can become congested, ingress buffers can fill, and input discards can begin to increment on a switch's interfaces.
A few milliseconds is a very short amount of time to a human being, but to a computer, a few milliseconds can be a lifetime.
The two key points are:
1. Input discards in a VOQ queuing architecture indicate one or more congested egress interfaces
2. There is no counter on an interface that identifies it is congested
1. Input discards in a VOQ queuing architecture indicate one or more congested egress interfaces
2. There is no counter on an interface that identifies it is congested
Next, let's investigate how you would troubleshoot a network congestion issue on Nexus 5500 switches manually.
Ultimately, network congestion is a system throughput problem. There are two fundamental ways to solve a throughput problem in a system:
1. Identify the bottleneck of the system and improve it.
2. Reduce the flow of the system until the bottleneck no longer exists.
1. Identify the bottleneck of the system and improve it.
2. Reduce the flow of the system until the bottleneck no longer exists.
Option #2 is not very helpful because network engineers often have little or no control over the amount of traffic within the network, which leaves us with Option #1.
Dr. Goldratt's Theory of Constraints states that making improvements anywhere but the bottleneck of a system will not improve the throughput of the system. Therefore, identifying a congested egress interface is extremely important to solving network congestion.
Nexus 5500 series switches offer a command - "show hardware internal carmel asic <x> registers match .*STA.*frh.*" - that displays a set of ASIC registers that match the regular expression ".*STA.*frh.*".
Registers matching this pattern identify the amount of data stored in a specific egress interface's virtual queue at the time of the command's execution.
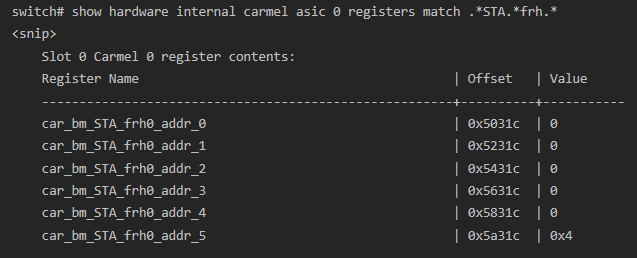
The output of this command shows that the interface corresponding with ASIC 0's memory address 5 (indicated by the "addr_5" substring of the register) contained data when the command was executed.
This output does *not* show historical data - it's a snapshot of the ASIC's buffers at the time the command is executed.
We can translate the ASIC number and memory address to an egress interface we recognize using the "show hardware internal carmel all-ports" command.
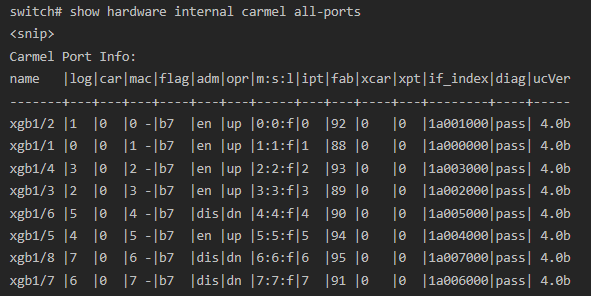
This table has three columns we should pay attention to - "name", "car", and "mac". The "car" column (which stands for "Carmel", the internal name of the Nexus 5500 ASIC) maps to the ASIC identifier. The "mac" column maps to the memory address.
The "name" column contains the internal name of the switch's interface, the numbering of which (e.g. 1/1, 1/2, etc.) maps to the external-facing interface we're familiar with (e.g. Ethernet1/1, Ethernet1/2, etc.).
The ASIC registers displayed by the "show hardware internal carmel asic <x> registers match .*STA.*frh.*" command indicates that memory address 5 of ASIC 0 contained data when the command was executed.
The table displayed by the "show hardware internal carmel all-ports" command translates this to internal interface xgb1/5, the numbering of which means that virtual queue for interface Ethernet1/5 contained data when the command was executed.
When network congestion is constantly occurring (meaning, input discards are constantly incrementing on one or more interfaces), you can execute these commands rapidly and get a very good idea as to which interface is your congested interface.
However, these commands are not very useful when network congestion is intermittent and strikes over a small period of time.
Most organizations cannot expect an employee to monitor interfaces for incrementing input discards over several hours *and* parse the collected data without error.
Thankfully, this is a perfectly reasonable expectation for a Python script!
Thankfully, this is a perfectly reasonable expectation for a Python script!
I created and published a Python script that solves this problem: github.com/ChristopherJHa…
It connects to a Nexus 5500 switch over SSH and rapidly (~10-15 checks per second) monitors a single interface for incrementing input discards.
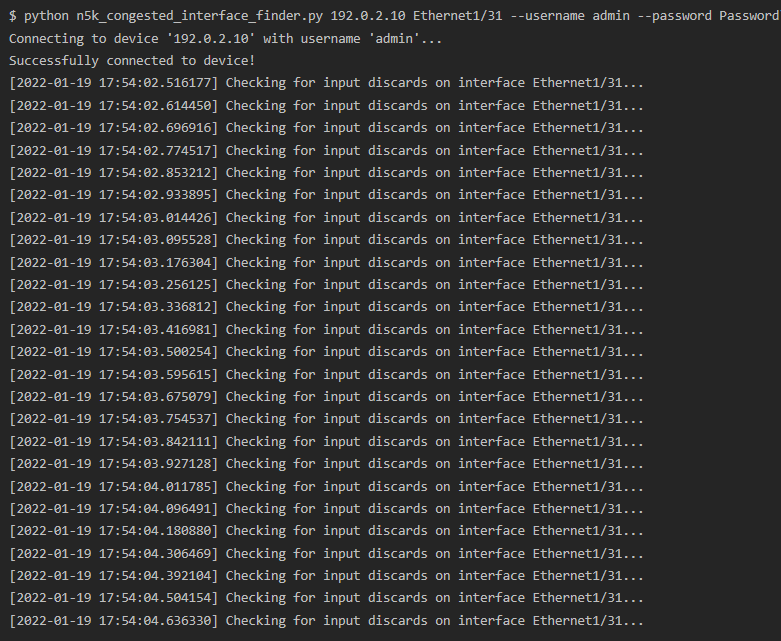
The script identifies when input discards start to increment and collects ASIC register information.
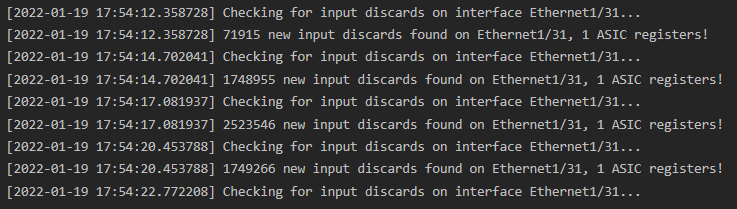
If the script is interrupted with Control+C, ASIC register data is parsed and summarized. Registers are conveniently translated to their corresponding external-facing names that network administrators are familiar with.
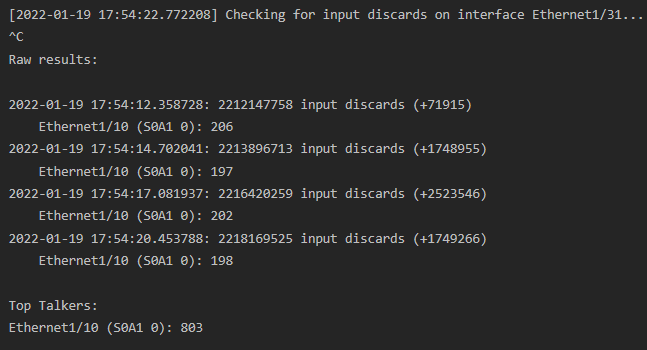
Overall, this script took about 4-6 hours to develop, test, and refine. In return, I hope it will save engineers countless hours tracking down congested egress interfaces and improve the reliability of the world's networks!
• • •
Missing some Tweet in this thread? You can try to
force a refresh









