When I started with machine learning, I always made the same mistake:
I confused a couple of metrics that look very similar but are entirely different.
Let's fix that for you.
↓
I confused a couple of metrics that look very similar but are entirely different.
Let's fix that for you.
↓
2. When we train a machine learning model, we need to compute how different our predictions are from the expected results.
For example, if we predict a house's price as $150,000, but the correct answer is $200,000, our "error" is $50,000.
For example, if we predict a house's price as $150,000, but the correct answer is $200,000, our "error" is $50,000.
3. There are multiple ways we can compute this error, but two common choices are:
• RMSE — Root Mean Squared Error
• MAE — Mean Absolute Error
These have different properties that will shine depending on the problem you want to solve.
• RMSE — Root Mean Squared Error
• MAE — Mean Absolute Error
These have different properties that will shine depending on the problem you want to solve.
4. Remember:
The optimizer will use this error to adjust the model. We want to set up the right incentives, so the model learns.
The optimizer will use this error to adjust the model. We want to set up the right incentives, so the model learns.
5. Let's focus on a critical difference between these two metrics:
Remember the "squared" portion of the RMSE.
It means that you are "squaring" the difference between the prediction and the expected value.
Why is this relevant?
Remember the "squared" portion of the RMSE.
It means that you are "squaring" the difference between the prediction and the expected value.
Why is this relevant?
6. Squaring the difference "penalizes" larger values.
If you expect a prediction to be 2, but you get 10, using RMSE, the error will be (2 - 10)² = 64.
However, if you get 5, the error will be (2 - 5)² = 9.
Do you see how it penalizes larger errors?
If you expect a prediction to be 2, but you get 10, using RMSE, the error will be (2 - 10)² = 64.
However, if you get 5, the error will be (2 - 5)² = 9.
Do you see how it penalizes larger errors?
7. MAE doesn't have the same property.
The error increases proportionally with the difference between predictions and target values.
Understanding this is important to decide which metric is better for each case.
The error increases proportionally with the difference between predictions and target values.
Understanding this is important to decide which metric is better for each case.
8. Predicting a house's price is a good example where $10,000 off is twice as bad as $5,000.
We don't necessarily need to rely on RMSE here, and MAE may be all we need.
We don't necessarily need to rely on RMSE here, and MAE may be all we need.
9. But predicting the pressure of a tank may work differently.
While 5 psi off may be within the expected range, 10 psi off may be a complete disaster.
Here 10 is much worse than just two times 5, so RMSE may be a better approach.
While 5 psi off may be within the expected range, 10 psi off may be a complete disaster.
Here 10 is much worse than just two times 5, so RMSE may be a better approach.
10. Although there's more to RMSE and MAE, I have always found this metal model helpful to understand how they work.
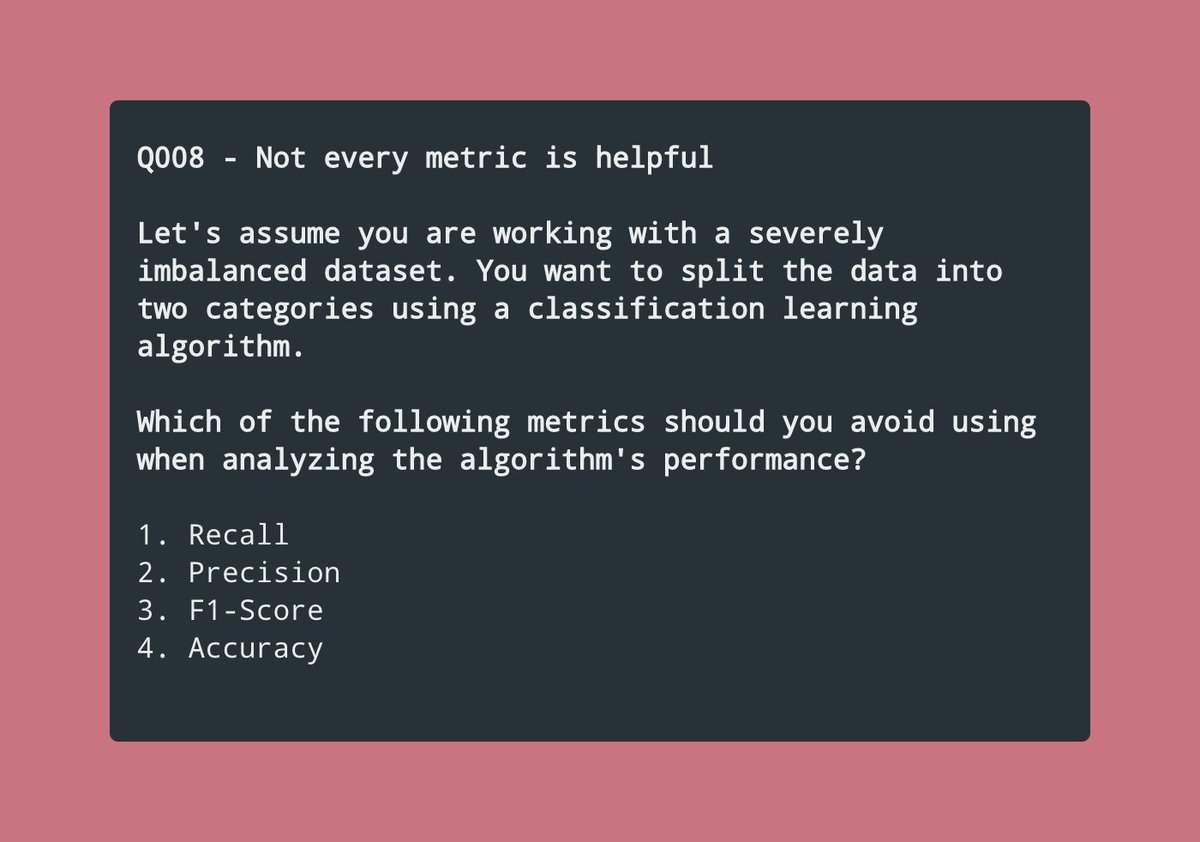
Three days ago, I asked the attached question.
We should be ready now to answer it.
Three days ago, I asked the attached question.
We should be ready now to answer it.

11. Looking at Option 1, we already know it is a correct answer.
RMSE penalizes larger differences between predictions and expected results.
RMSE penalizes larger differences between predictions and expected results.
12. Looking at both formulas, RMSE has extra squaring and root squaring operations, so it can't be faster to compute than MAE.
Option 2 is, therefore, not correct.
Option 2 is, therefore, not correct.
13. Option 3 states that RSME is indifferent to the direction of the error, but MAE isn't.
This is not correct: MAE uses the absolute value of the error, so both negative and positive values will end up being the same.
This is not correct: MAE uses the absolute value of the error, so both negative and positive values will end up being the same.
14. Option 4 states that MAE is indifferent to the direction of the error, but RMSE isn't.
This is not correct either.
RMSE squares the error, so both negative and positive values will end up being the same.
This is not correct either.
RMSE squares the error, so both negative and positive values will end up being the same.
15. In summary, the only correct answer to this question is Option 1.
By the way, I write practical tips, break down complex concepts, and regularly publish short quizzes to keep you on your toes.
Follow me @svpino, and let's do this together!
By the way, I write practical tips, break down complex concepts, and regularly publish short quizzes to keep you on your toes.
Follow me @svpino, and let's do this together!
• • •
Missing some Tweet in this thread? You can try to
force a refresh