
I think I got it, omg
Compare to current behavior:
Quick refresher on how arrows are *supposed to* work. 

When we have an arrow between shapes, that arrow has a start and end point (actual location is based on a normalized "anchor" from when the arrow was last modified, long story)

We fire a ray from the start point through end point.
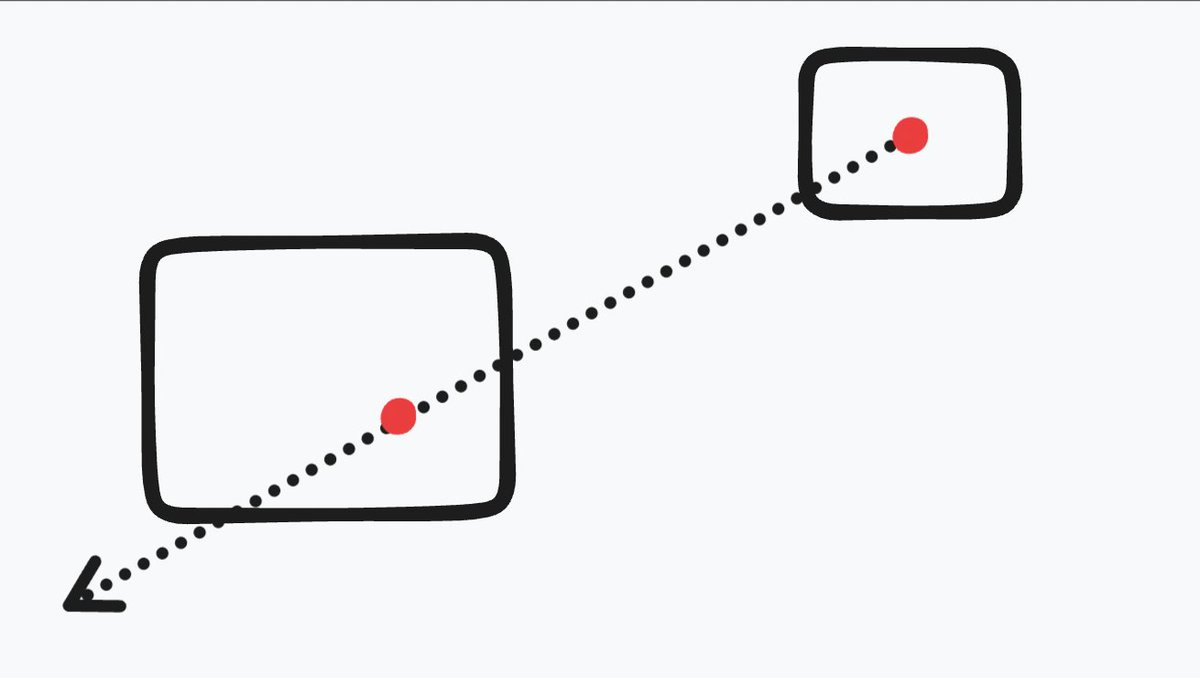
We expect to have have one intersection from the start shape, and two intersections in the end shape. We pick the intersection closer to the start point.

If the arrow has a decoration (ie an arrowhead) then we move the point back toward the other point by some distance.

Now we can draw our arrow.

Hooray!
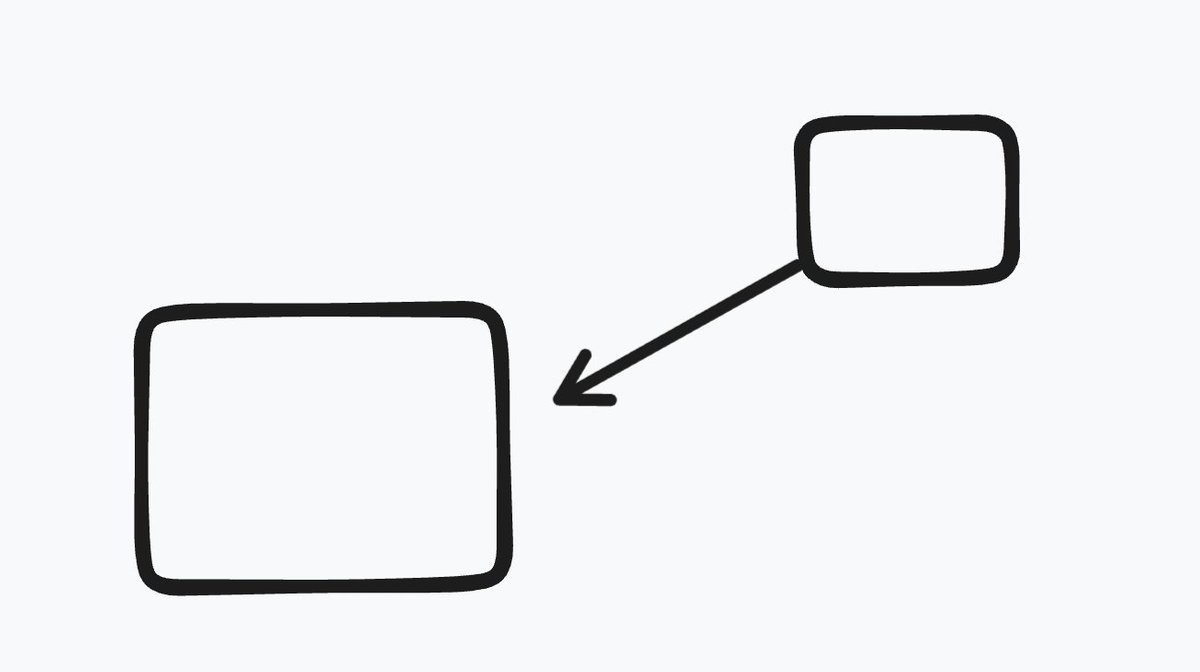
To my great shame and frustration, this routine only works if certain conditions are met. Did you catch them?
For example, what if the shapes are overlapping?

Then you get this one.

Doesn't look very good, in part because the arrow is no longer pointing "towards" its anchor, but through it.

The fix for this is to force an arrow of a known distance that points toward the anchor point.

This also works if the shape is overlapping the target point, though not as well.

There's some more to deciding when to change strategies (arrow too short? contain or collide?) but that's the main approach.
Still some work to do 🤔
🔗 test branch: tldraw-a2msnibzj-tldraw.vercel.app
• • •
Missing some Tweet in this thread? You can try to
force a refresh



