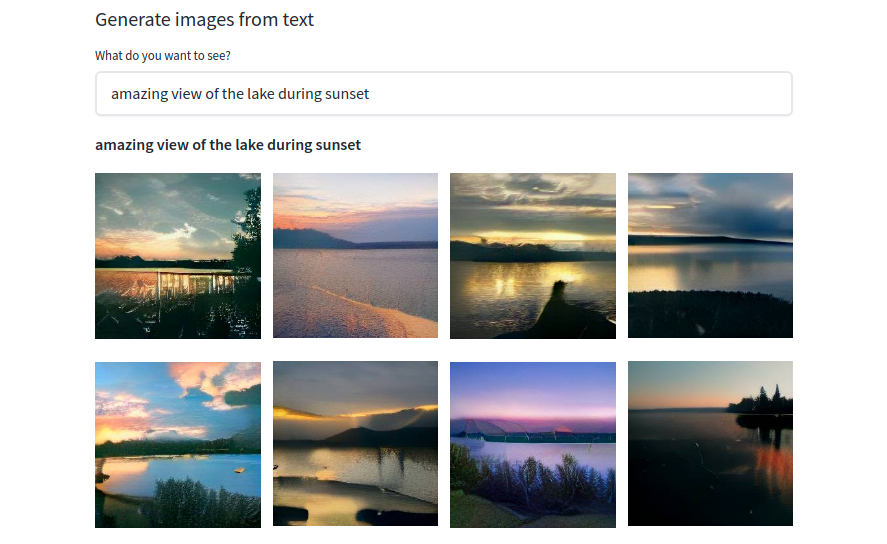
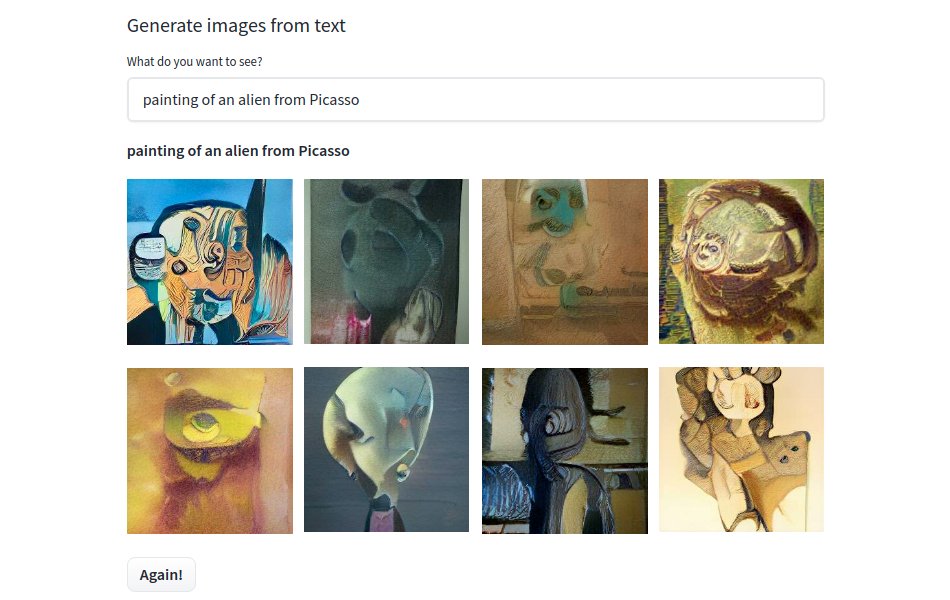
I've been comparing a lot of transformer variants on large models (400M params): Post/Pre-LN, DeepNet, NormFormers, Swin v2, GLU variants, RMSNorm, Sandwich LN, with GELU, Swish, SmeLU…
More than 2,000h of total training time on TPU v3's 😯
Here are my findings 🤓
More than 2,000h of total training time on TPU v3's 😯
Here are my findings 🤓
You must use a final LayerNorm in the decoder for any pre-LN architecture (they're always present in post-LN).
It also helps convergence to use one at the end of the encoder as well.
It also helps convergence to use one at the end of the encoder as well.

Don't use bias in dense layers.
It adds 15% of training time and hurts convergence.
It adds 15% of training time and hurts convergence.

If you use a post-LN model (LayerNorms after each residual connection), DeepNet improves a little bit stability.

I had the highest success with NormFormers.
The position of the LayerNorms is similar to Sandwich-LN (per Cogview) except in the attention block.
It shows however better stability.
The position of the LayerNorms is similar to Sandwich-LN (per Cogview) except in the attention block.
It shows however better stability.

I ran a bunch of NormFormer variants.
The paper suggests not using the scaled residual connection. I recommend not using the head scale either.
I don't use learnt scale in LN when followed by dense layers. It trains better with it but I think it's because it acts as a reduced lr.
The paper suggests not using the scaled residual connection. I recommend not using the head scale either.
I don't use learnt scale in LN when followed by dense layers. It trains better with it but I think it's because it acts as a reduced lr.

GLU variants are great!
Even if they increase peak memory (and reduce your max batch size) for same amount of total parameters, they let the model train much better!
Even if they increase peak memory (and reduce your max batch size) for same amount of total parameters, they let the model train much better!

As activation function, use GeLU (more stable) or Swish (trains faster).
I didn't have great results with the new SmeLU function.
I didn't have great results with the new SmeLU function.

RMSNorm brings more stability to the training.
However for very long runs it plateau's before LayerNorm.
However for very long runs it plateau's before LayerNorm.


I didn't have great results with Swin v2 even after playing with different values of tau scale in the cosine attention.
I think the cosine attention makes the model learn much slower.
I think the cosine attention makes the model learn much slower.

I also tested to only use Swin relative positions with other variants but it was not helpful.

Sinkformers are a bit slower to train and didn't improve the model.
Maybe it's because I can only use them in the encoder and not in the decoder due to causality.
Maybe it's because I can only use them in the encoder and not in the decoder due to causality.

You'll find more details in the report and a TLDR with links to relevant sections, full of interactive graphs and traceable runs (with diffs between runs).
Report here: wandb.ai/dalle-mini/dal…
Report here: wandb.ai/dalle-mini/dal…

Many thanks to @_arohan_ and Phil Wang for suggesting some of these ideas!
I have a lot more stuff to try in my backlog so will probably be updating this report in the future.
Also thanks to @pcuenq for running some of these experiments with me!
I have a lot more stuff to try in my backlog so will probably be updating this report in the future.
Also thanks to @pcuenq for running some of these experiments with me!
• • •
Missing some Tweet in this thread? You can try to
force a refresh