
1/7 I am thrilled to announce Aspire, a new method for scientific document similarity from my internship with @allen_ai to be presented at #NAACL2022!
📰Paper: arxiv.org/abs/2111.08366
👾🐱Code, data, HF models: github.com/allenai/aspire
A TLDR of our contribs:
📰Paper: arxiv.org/abs/2111.08366
👾🐱Code, data, HF models: github.com/allenai/aspire
A TLDR of our contribs:
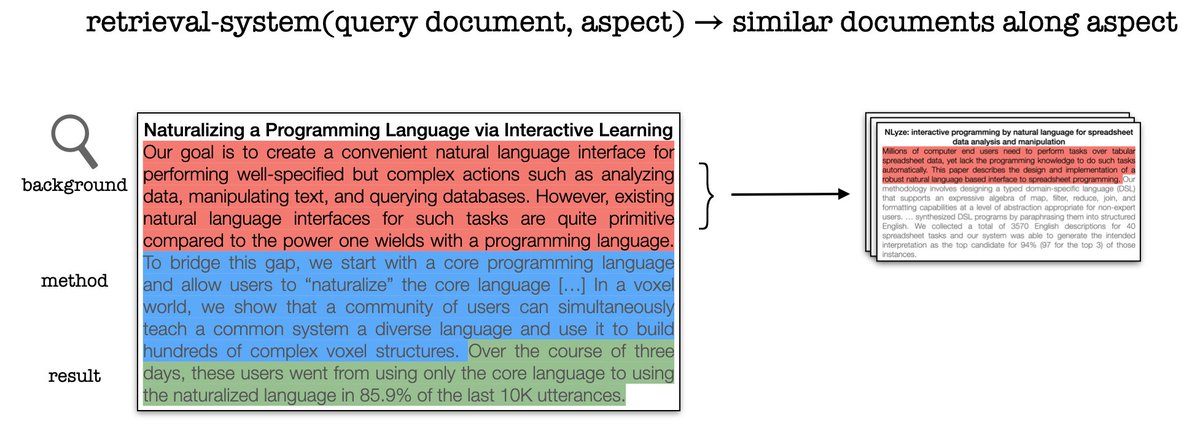
2/7 Scientific papers generally consist of many elements - so, we built a method which represents these aspects of papers and uses them to compute similarity between scientific papers. 

3/7 We opt for a simple document representation and represent a paper at the sentence level with a contextual encoder. Now, training a model for similarity between the different aspects of a paper is challenging since there is rarely any training data of aspect level similarity.
4/7 To overcome this challenge, we leverage “textual supervision” from co-citation contexts for training Aspire. These co-citation context sentences often describe the ways in which co-cited papers are similar. For example, consider:

5/7 Next, since there are likely to be multiple aspect matches across papers we also built a mechanism for making multiple soft and sparse matches using an optimal transport mechanism.

6/7 Aspire sees state-of-the-art performance on scientific document retrieval, and also supports retrieval conditioned on specific aspects. For example, papers only similar to the ‘background’ may be retrieved by selecting those sentences in the abstract context.
7/7 This work was done under the kind and energetic guidance of @Hoper_Tom and @armancohan and despite being remote the enthusiasm of the @SemanticScholar team and @allen_ai was infectious! 😌😌
• • •
Missing some Tweet in this thread? You can try to
force a refresh


