
Want a captioning system to describe images in more detail & grammatically, but existing caption annotations are not fine-grained?
Check our #NAACL2022 Findings paper “Fine-grained Image Captioning with CLIP Reward”!
arxiv.org/abs/2205.13115
@AdobeResearch @uncnlp
🧵👇
(1/n)
Check our #NAACL2022 Findings paper “Fine-grained Image Captioning with CLIP Reward”!
arxiv.org/abs/2205.13115
@AdobeResearch @uncnlp
🧵👇
(1/n)
https://twitter.com/ak92501/status/1530007802013417486
Toward more descriptive and distinctive caption generation, we propose using CLIP to calculate multimodal similarity and use it as a reward function. This avoids imitating only the reference caption and instead transfers fine-grained details from similar training images.
(2/n)
(2/n)

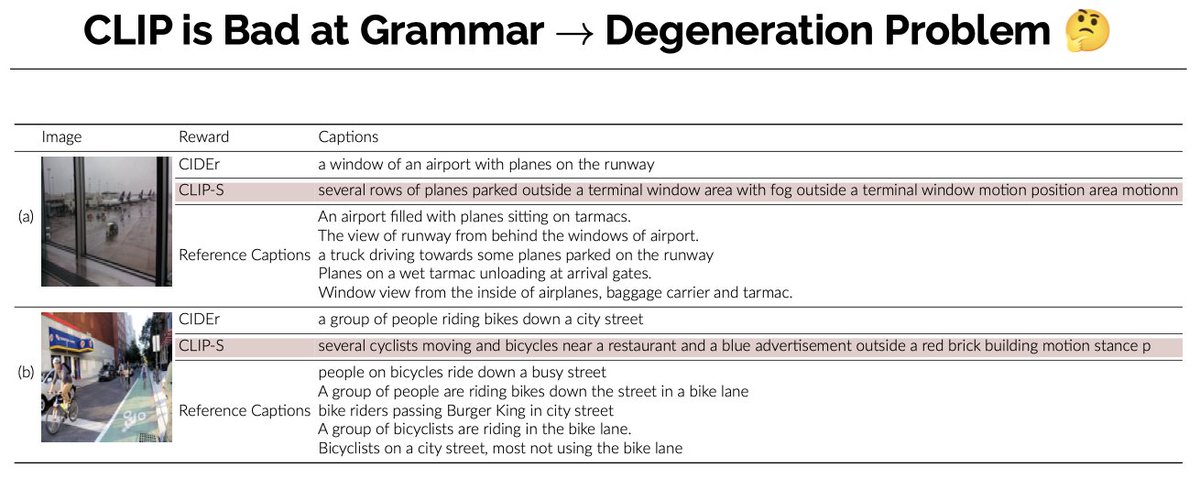
We found that using CLIP-S (@jmhessel etal) as reward provides such fine-grained guidance; but we also found that the model trained with it degenerates with repeated words. Since CLIP is trained only with a contrastive objective, its text encoder doesn't care about grammar
(3/n)
(3/n)
To address this, we next inject grammar knowledge into CLIP, by finetuning its text encoder w/o requiring extra grammar annotations. We create negative sentences by editing original ones, and learn an MLP head to classify whether a sentence is grammatically correct or not.
(4/n)
(4/n)

The grammar score successfully addresses the text degeneration problem!
(5/n)
(5/n)

To comprehensively diagnose the aspect of caption descriptiveness / fine-grainedness, we introduce FineCapEval, a fine-grained caption evaluation dataset.
(6/n)
(6/n)

In our experiment, training with our CLIP-S + grammar reward provides more fine-grained captions and outperforms other rewards on FineCapEval across the board.
In addition, human evaluation also strongly prefers our approach to MLE & CIDEr-reward model baselines.
(7/n)
In addition, human evaluation also strongly prefers our approach to MLE & CIDEr-reward model baselines.
(7/n)


Code: github.com/j-min/CLIP-Cap…
Thanks to all collaborators
@david_s_yoon @ajinkyakale @FranckDernoncou TrungBui @mohitban47
and reviewers for the feedback!
And thanks @ak92501 for the original tweet!
(8/n)
Thanks to all collaborators
@david_s_yoon @ajinkyakale @FranckDernoncou TrungBui @mohitban47
and reviewers for the feedback!
And thanks @ak92501 for the original tweet!
(8/n)
• • •
Missing some Tweet in this thread? You can try to
force a refresh






