
So @jeremyphoward and @HamelHusain's new nbprocess library. (or nbdev v2). It's going to be a *GAME CHANGER*!
In a *single afternoon* I managed to create a module that lets you export #nbdev tests into pytest submodules automatically: github.com/muellerzr/nbpr…
In a *single afternoon* I managed to create a module that lets you export #nbdev tests into pytest submodules automatically: github.com/muellerzr/nbpr…

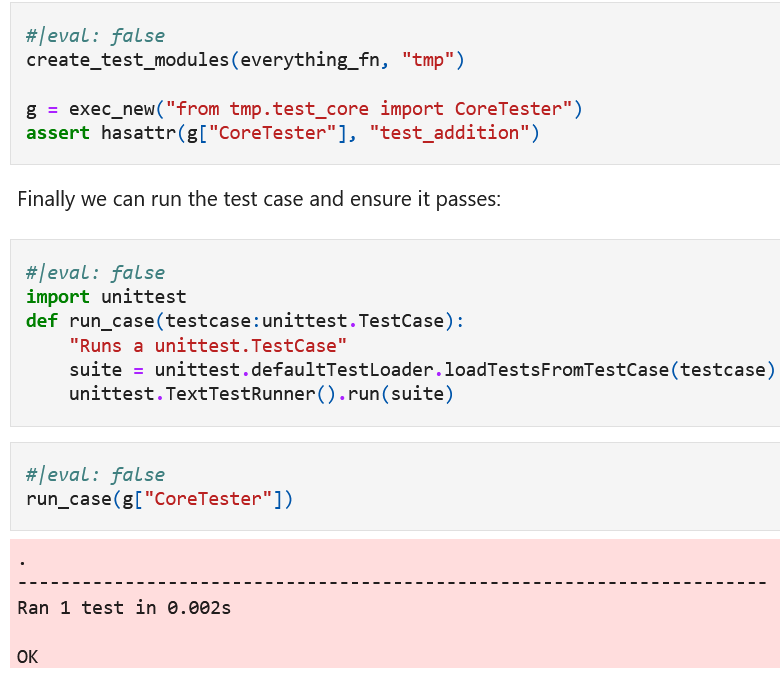
This is a gamechanger because now you don't have to worry about if need to keep your tests in your notebook. They also exist as unittest modules (or could be pytest) with ease. The craziest part about this for me is it's < 100 lines of code! TOTAL!
This isn't just nbdev version 2. It's my ~dream~ for what I wanted nbdev to be in the talk I gave in November. Is it all there yet? God no.
But I just hit one of the major points in less than a day. This will change the literate programming landscape.
But I just hit one of the major points in less than a day. This will change the literate programming landscape.
• • •
Missing some Tweet in this thread? You can try to
force a refresh












