
✨📜 New paper out!
'Diegetic representation of feedback in open games' arxiv.org/abs/2206.12338, accepted for proceedings track at ACT'22
TL;DR: 'reverse-mode diff' for games clarifies game-theoretic structure, fixes conceptual issues and unifies them with learners
🧵 0/n
'Diegetic representation of feedback in open games' arxiv.org/abs/2206.12338, accepted for proceedings track at ACT'22
TL;DR: 'reverse-mode diff' for games clarifies game-theoretic structure, fixes conceptual issues and unifies them with learners
🧵 0/n

At least two of original inventors of open games, @_julesh_ and @philipp_m_zahn, have been quite enthusiastic about the ideas in the paper (and afaiu also @Anarchia45 liked them :) 1/n
https://twitter.com/_julesh_/status/1513865273643786247?s=20&t=X9SLPYWi5TAUlb8XtnUn0g
First, what the heck does 'diegetic' mean?
It's a loanword from narratology and means 'internal to the story being narrated'. You might be familiar with 'diegetic narrators', being narrators who also feature in the story they recount, vs 'extradiegetic narrators' which don't 2/n
It's a loanword from narratology and means 'internal to the story being narrated'. You might be familiar with 'diegetic narrators', being narrators who also feature in the story they recount, vs 'extradiegetic narrators' which don't 2/n

I picture game specifications (extensive form and open games, specifically) as telling a story about how a game is played, featuring players as characters. The climax of the story is when players react to the outcomes of the game by deviating their strategy 3/n
So 'diegetic representation of feedback' means to explicitly represent this part of the story in the 'game system'. Until now, this part was handled *extradiegetically*, using decoration by equilibrium predicates, best response and selection functions. 4/n

The problem? The most important part of the system, the strategic core of the game, which ends up computing Nash equilibria, had to be handled ad-hoc and wasn't really recognized as part of the system 5/n
Most embarassingly, when last year we outlined some of the core ideas regarding the representation of agency in cybercats (matteocapucci.wordpress.com/2021/06/21/ope…), we missed that 'open games with agency' were, according to our criterion, devoid of agency!😱 6/n
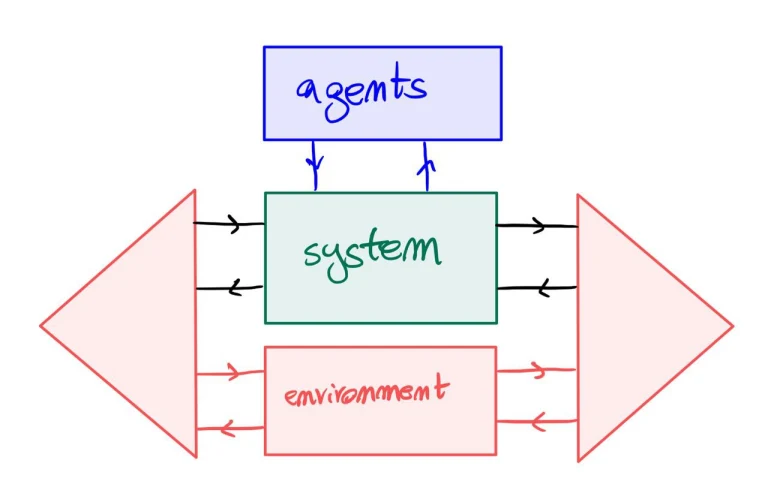
In fact the selection function of an open game is a decoration on the top boundary object and not a morphism, which would represent a system of agents. Remember: morphisms are systems, objects are just boundaries. 7/n

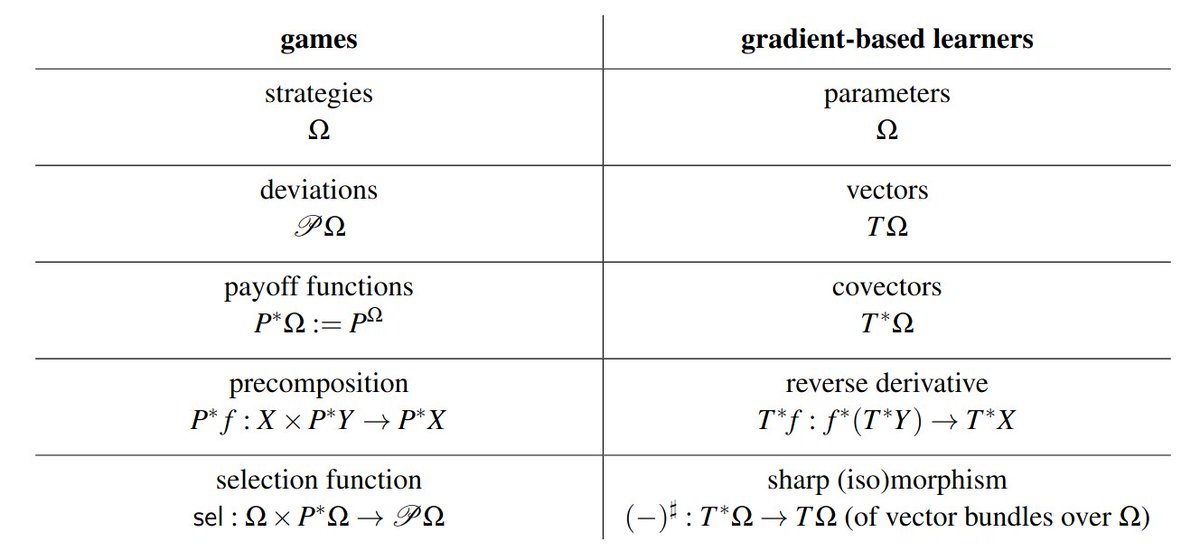
Compare this to learners (depicted), in which over a controlled system L lies a well-distinguished controller system, the GD (gradient descent) lens, which diegetically embodies a cybernetic feedback action-reaction cycle. 8/n
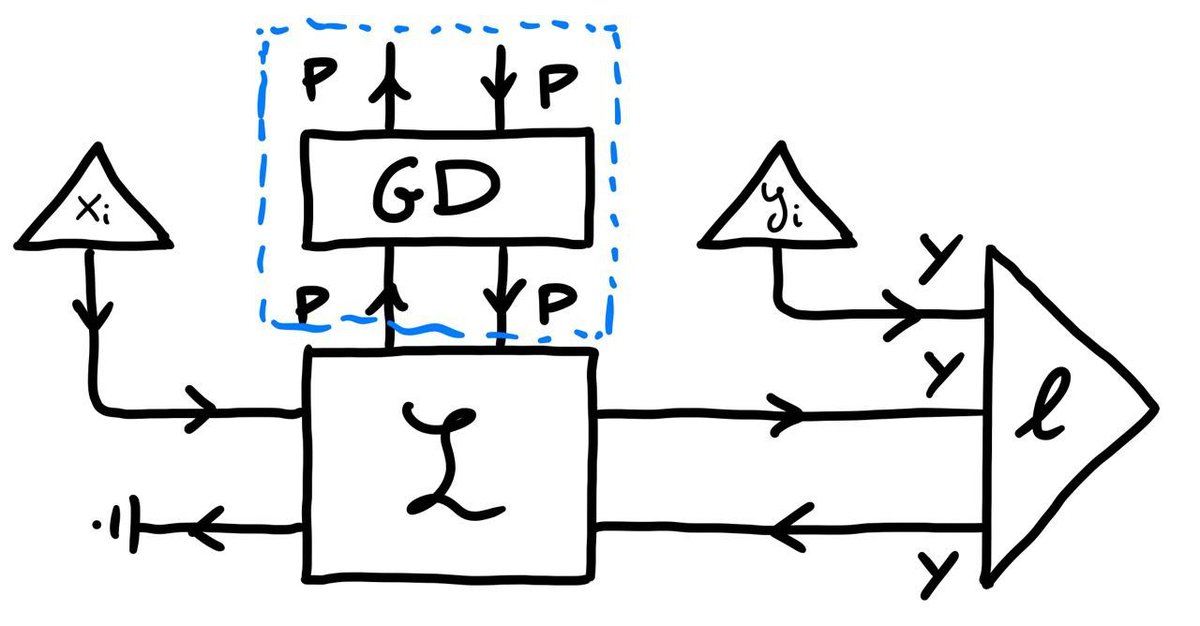
The main problem in doing so for open games lies in the extreme counterfactuality of players' feedback processing. In fact in open games (and in all game theory before them) players are pictured receiving a payoff as their only feedback 9/n
Usually players in games are pictured as utility-maximizing agents which receive a payoff they strive to maximize. However, this picture is (partially) wrong! This took me a long time to realize, but then I was enlightened 10/n
Players do not receive just their payoff as feedback, but *an entire payoff function*. Then they select their strategy in order to maximize what they can get from that. Without such an informative feedback from the game arena, they wouldn't be able to compute best responses 11/n
Players that only receive a payoff from the system are reinforcement learning agents, and balance such low bandwidth feedback with a richer internal dynamics. Incidentally, you can read about this in @RiuSakamoto & @_julesh_ latest paper arxiv.org/abs/2206.04547 12/n
So the main idea in my paper is to take this seriously and rethink games as feedback systems where feedback is given by a sort of backpropagation of payoff functions. The results are striking! 13/n
In the paper I show you can associate a feedback dynamics functorially to a given play dynamics. That is, given the way players interact and suitable payoff types, we can automatically build the so-called 'coplay' of a game, i.e. the backward pass of an open game 14/n
Fixing payoffs P, this is achieved by first defining a functor P^* : Set -> Lens(Set) which does a very simple thing: given f:X->Y, sends it to the lens (X,P^X) -> (Y,P^Y) given by (f, P^f), where P^f : u ↦ f;u 15/n

The absolute outrageous fact about this functor is, it's basically the functor P^(-), i.e. the contravariant hom-functor Set(-, P), but crucially landing in lenses allows us to define a monoidal structure on it 16/n

That's probably the most important finding in this work. The Nashator is the fundamental bit of math making games act weird and interesting. It's an extremely forgetful thing: it projects lines from a payoff matrix, thus losing most of the information in it. 17/n
Magically, the Nashator is the spice that makes the counterfactual analysis of players in a game even possible. Together with lens composition, it handles all the complexity of payoff backpropagation 18/n
We can now represent players' counterfactual analysis because the game shoots up to players their entire payoff function, crucially conditioned on other players choices. So now we have the right data to even been able to consider a system of players above the arena 19/n
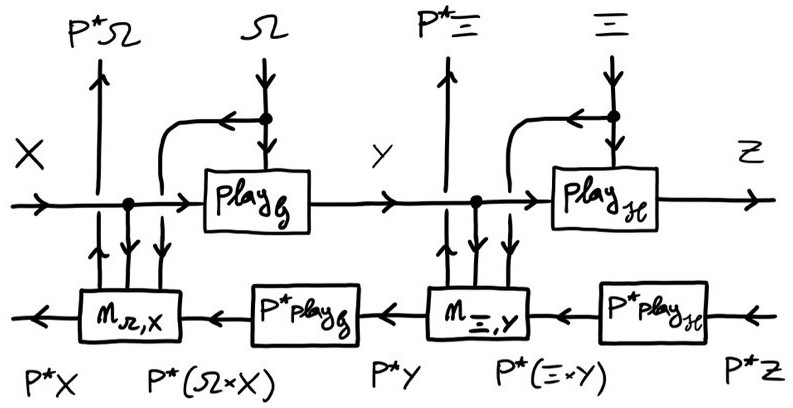
Essentially, these systems are given by selection functions (here, argmaxens) which are now given as *lenses*, hence morphisms, and not as objects, thereby fixing the conceptual awkwardness of open games with agency (here 𝒫 is powerset) 20/n

Now compare the resulting pictures we get of a gradient-based learner (left) and a game (right). Suspiciously similar, aren't they?
Next time I'll tell you about how diegetic feedback unifies the kinds of backpropagation these systems do, opening a vast horizon beyond RDCs! 21/21
Next time I'll tell you about how diegetic feedback unifies the kinds of backpropagation these systems do, opening a vast horizon beyond RDCs! 21/21
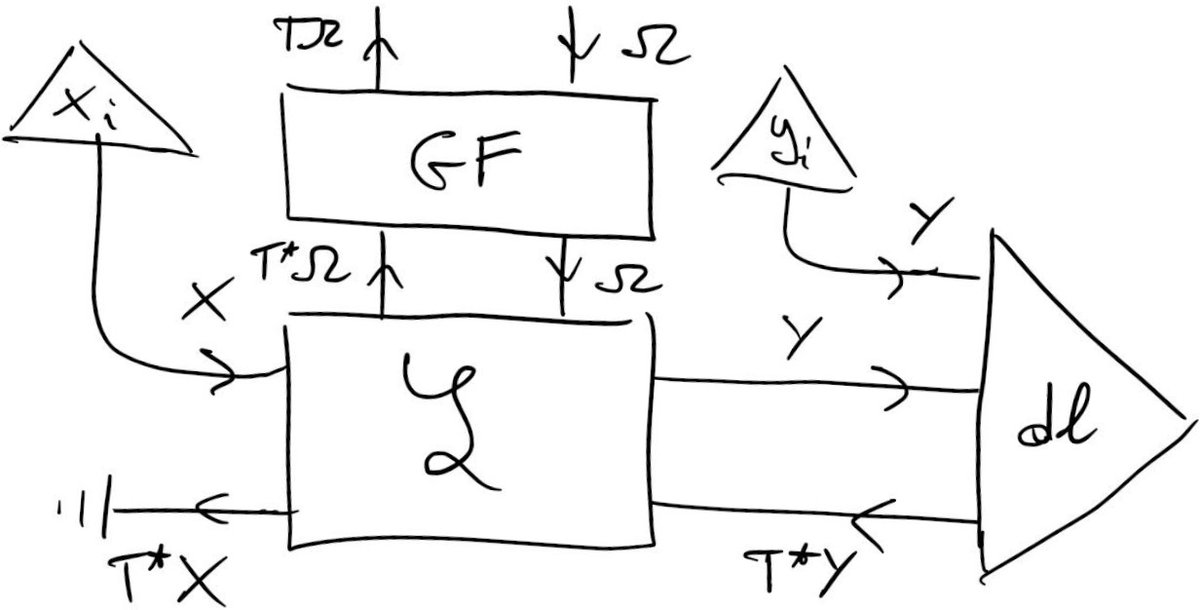

Little spoiler: 22/
• • •
Missing some Tweet in this thread? You can try to
force a refresh












