
Happy to share our #NAACL2022 paper: “Masked Part-Of-Speech Model: Does Modeling Long Context Help Unsupervised POS-tagging?”
🐭MPoSM models long-term & bidirectional tag dependency.
arxiv.org/abs/2206.14969
w/ @byryuer @mohitban47
Join us in Seattle (oral session6B July12)
🧵
🐭MPoSM models long-term & bidirectional tag dependency.
arxiv.org/abs/2206.14969
w/ @byryuer @mohitban47
Join us in Seattle (oral session6B July12)
🧵

Previous Part-Of-Speech (POS) induction models usually assume certain independence assumptions (e.g., Markov, unidirectional, local dependency) that do not hold in real languages. For example, the subject-verb agreement can be both long-term and bidirectional.

Our Masked Part-Of-Speech Model (🐭MPoSM (pronounced as m-possum)) is inspired by masked language modeling. It has 2 parts: a Local POS Prediction module, and a Masked POS Reconstruction module. Through the reconstruction objective, it models arbitrary tag dependencies.
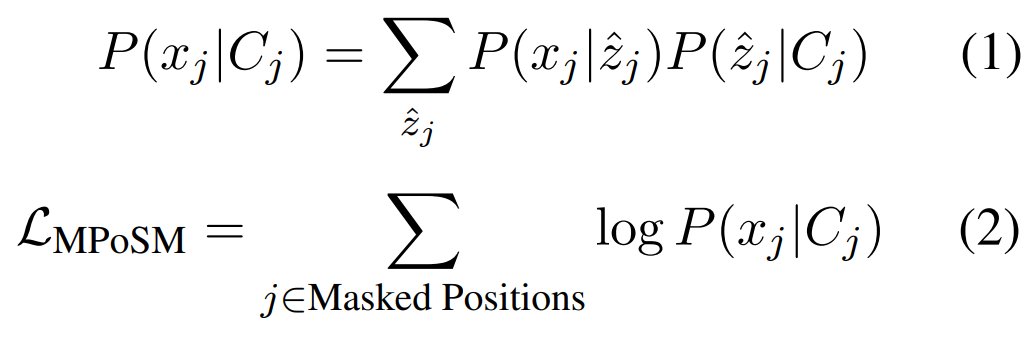
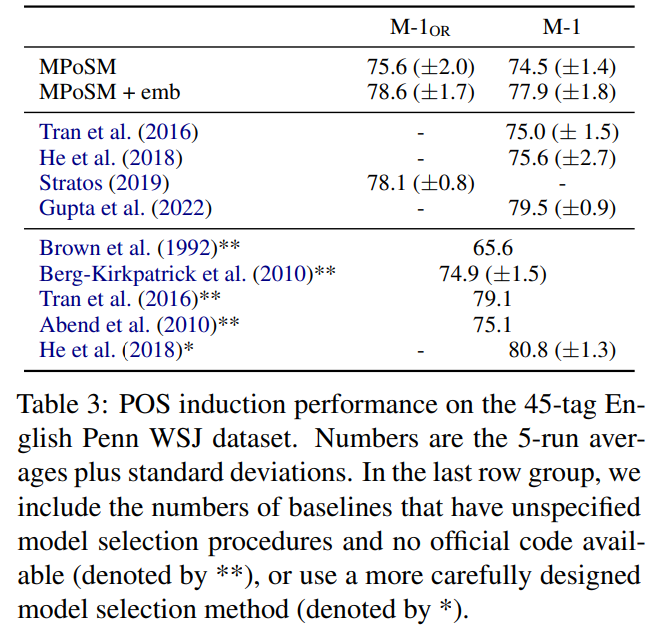
MPoSM achieves competitive results on both the English Penn WSJ dataset & the universal treebank containing 10 languages (de en es fr id it ja ko pt-br sv). It reaches 77.9 M1 on the WSJ dataset. Similar to the recent work by Gupta et al., it can also leverage the power of mBERT.

Back to the title: Does Modeling Long Context Help Unsupervised POS-tagging?
Surprisingly, we see mixed results.
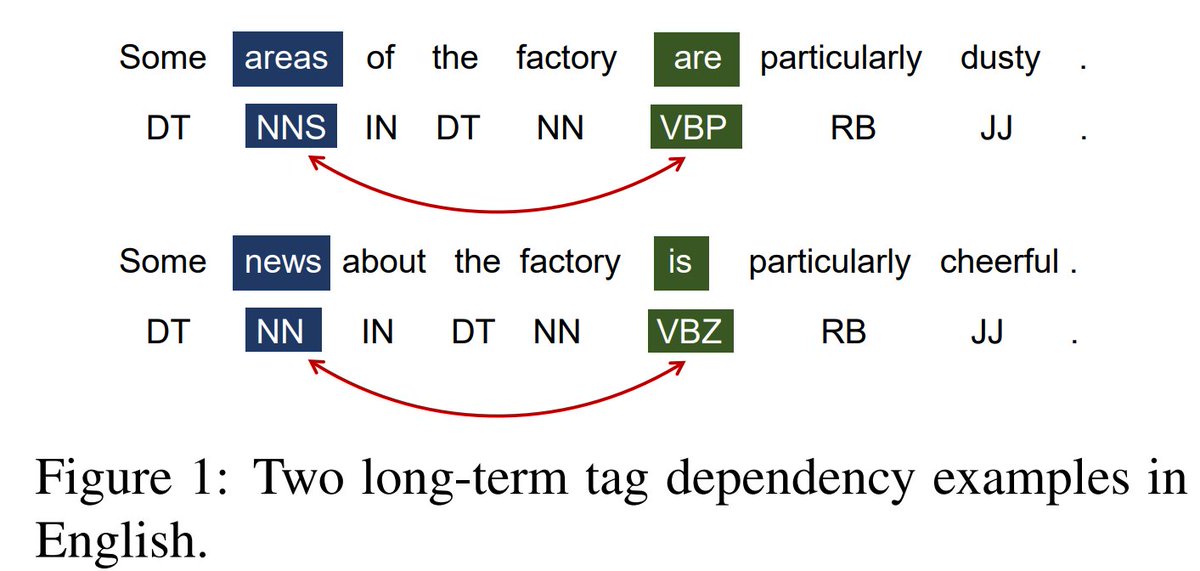
This is interesting because ideally modeling a longer context should help in most cases (e.g. the long-term subject-verb agreement in the picture below).
Surprisingly, we see mixed results.
This is interesting because ideally modeling a longer context should help in most cases (e.g. the long-term subject-verb agreement in the picture below).

To better understand this phenomenon, we design a synthetic experiment that specifically diagnoses the ability to learn tag agreement. Surprisingly, strong baselines fail to solve this problem consistently, even in a very simplified setting: the agreement between adjacent words.

In this experiment, MPoSM achieves overall better performance but still not perfect (indicating the optimization challenge in learning agreements).
Lastly, we conduct a detailed error analysis to shed light on other challenges (cluster size differences, dataset biases, etc.).
Lastly, we conduct a detailed error analysis to shed light on other challenges (cluster size differences, dataset biases, etc.).


Our code is available at github.com/owenzx/MPoSM
We will also do an in-person oral presentation at @naaclmeeting during 16:15 – 17:45 PST on July 12.
See you in Seattle!
We will also do an in-person oral presentation at @naaclmeeting during 16:15 – 17:45 PST on July 12.
See you in Seattle!
• • •
Missing some Tweet in this thread? You can try to
force a refresh


