
Kubernetes basics explained by analogy 🧵
...or "How Kubernetes Just Repeats Good Old Deployment Patterns"
1. For a long time, people had been deploying services as groups of virtual (or physical) machines.
But VMs were often slow and bulky. Hence, not very efficient.
...or "How Kubernetes Just Repeats Good Old Deployment Patterns"
1. For a long time, people had been deploying services as groups of virtual (or physical) machines.
But VMs were often slow and bulky. Hence, not very efficient.

2. Then containers gained quite some popularity.
With containers, it became easier to distribute services. Reproducibility also improved. But containers haven't become a replacement for VMs.
Mainly, because of their deliberate focus on being an environment to run a single app:
With containers, it became easier to distribute services. Reproducibility also improved. But containers haven't become a replacement for VMs.
Mainly, because of their deliberate focus on being an environment to run a single app:

3. Instead of containers, another abstraction took off - Kubernetes Pods!
A Pod is a group of semi-fused containers. External borders were preserved, but some of the internal isolation b/w containers substituting a Pod got weakened.
A Pod is a much closer abstraction to a VM.
A Pod is a group of semi-fused containers. External borders were preserved, but some of the internal isolation b/w containers substituting a Pod got weakened.
A Pod is a much closer abstraction to a VM.

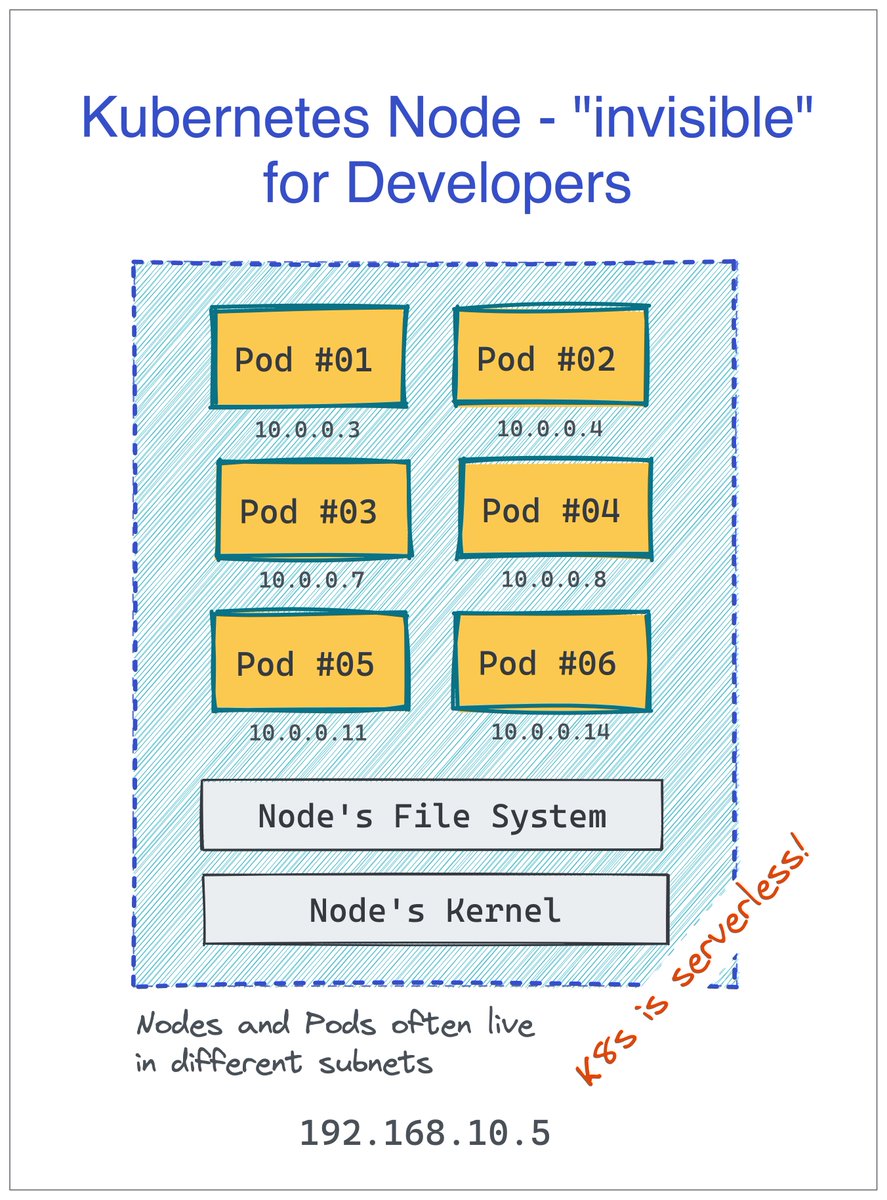
4. A single (virtual or physical) machine can run many independant Pods.
In Kubernetes, machines substituting a cluster are called Nodes, but developers are rarely concerned with this abstraction. For them, Kubernetes is serverless! 🙈
More Pods per server means better packing.
In Kubernetes, machines substituting a cluster are called Nodes, but developers are rarely concerned with this abstraction. For them, Kubernetes is serverless! 🙈
More Pods per server means better packing.
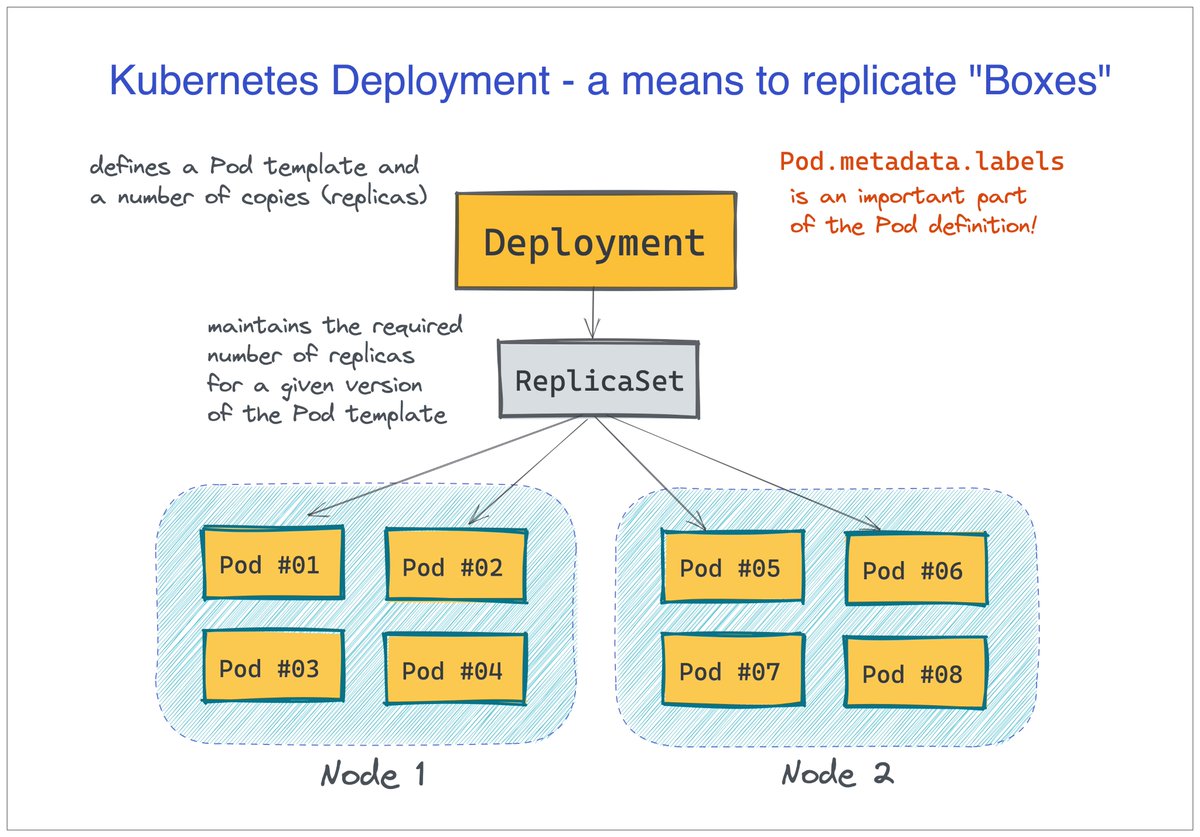
5. Deployment of Pods happens through replicating a Pod template.
There is a Deployment object in Kubernetes that holds the desired Pod template and the needed number of "copies." But logically, there is not much difference between scaling Pods and VMs.
There is a Deployment object in Kubernetes that holds the desired Pod template and the needed number of "copies." But logically, there is not much difference between scaling Pods and VMs.
6. Kubernetes Service is a means of grouping Pods behind a logical name.
Kubernetes comes with built-in service discovery.
The implementation is neither client- nor server-side (rather network-side). But from the clients' standpoint, it feels like a good old reverse proxy.
Kubernetes comes with built-in service discovery.
The implementation is neither client- nor server-side (rather network-side). But from the clients' standpoint, it feels like a good old reverse proxy.

• • •
Missing some Tweet in this thread? You can try to
force a refresh





















