
Braintrust (@usebraintrust) is one of the highest-profile attempts at a Web3 use case.
With $123M raised, investors say it's a decentralized network disrupting Upwork.
My analysis shows it's a centralized staffing agency juicing up growth metrics.
Who does your brain trust?🧵
With $123M raised, investors say it's a decentralized network disrupting Upwork.
My analysis shows it's a centralized staffing agency juicing up growth metrics.
Who does your brain trust?🧵



Braintrust presents itself as a manifestation of @cdixon’s “insight” that Web2’s take rate is Web3’s opportunity.
So how exactly is it able to operate with a lower take rate? The answer will shock you…
So how exactly is it able to operate with a lower take rate? The answer will shock you…


Braintrust's home page proclaims: You can keep 100% of what you earn.
It neglects to mention that's after subtracting a 10% take rate. Oops.
Some Braintrust investors, like @packyM, level with us about the 10% take rate. Other investors, like @variantfund's @jessewldn, don't.
It neglects to mention that's after subtracting a 10% take rate. Oops.
Some Braintrust investors, like @packyM, level with us about the 10% take rate. Other investors, like @variantfund's @jessewldn, don't.




Braintrust’s 10% take rate isn’t necessarily low. It's the same as Upwork’s take rate for similar kinds of contracts.

Maybe Braintrust wants us to compare their 10% take rate to that of a high-touch recruiting agency.
It's low when compared to a recruiting fee of 20-50%.
But how exactly does Braintrust expect to undercut the recruiting agency business model?
It's low when compared to a recruiting fee of 20-50%.
But how exactly does Braintrust expect to undercut the recruiting agency business model?
It's up to Braintrust to prove out a business model with lower recruiting costs.
Instead, they’ve focused on expanding their network and growing top-line revenue.
Sources tell me they currently operate like a venture-subsidized staffing agency.
Instead, they’ve focused on expanding their network and growing top-line revenue.
Sources tell me they currently operate like a venture-subsidized staffing agency.
Braintrust touts revenue growth here: info.app.usebraintrust.com
Note they’ve opted for a cumulative graph; the revenue-by-month curve would be flatter.
Still, the total amount companies are paying for job contracts and fees has grown from about $5M/month in Jan to $10M/mo in Aug.
Note they’ve opted for a cumulative graph; the revenue-by-month curve would be flatter.
Still, the total amount companies are paying for job contracts and fees has grown from about $5M/month in Jan to $10M/mo in Aug.

Interestingly, despite the recent 2x revenue growth, the market cap of the BTRST token has been flat or down.
It’s currently $175M, down 76% from last year’s ICO.
It’s currently $175M, down 76% from last year’s ICO.

I wonder how many recruiter salaries currently get subsidized by Braintrust’s venture funding.
LinkedIn shows 248 employees, but many are just network participants.
If Braintrust keeps charging industry-low fees, it’s not clear how they’ll keep affording recruiter salaries.
LinkedIn shows 248 employees, but many are just network participants.
If Braintrust keeps charging industry-low fees, it’s not clear how they’ll keep affording recruiter salaries.

How is a blockchain token supposed to help Braintrust sustain a recruiting operation with lower fees?
According to their white paper, here's what the BTRST token provides:
⬜️Governance
⬜️Bid Staking
⬜️Career Benefits
According to their white paper, here's what the BTRST token provides:
⬜️Governance
⬜️Bid Staking
⬜️Career Benefits

Braintrust's #1 claim about the BTRST token is that it attracts contractors who appreciate having network governance rights...
Yet there’s been no serious on-chain voting to date.
A core team member even admitted that Braintrust's on-chain voting feature isn’t a priority.
Yet there’s been no serious on-chain voting to date.
A core team member even admitted that Braintrust's on-chain voting feature isn’t a priority.



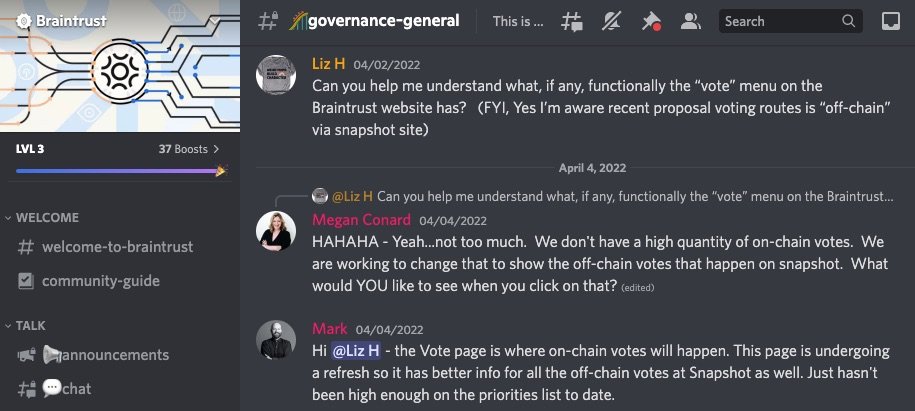
Does important governance still happen off-chain?
Kind of.
The Braintrust community recently “voted” on a proposal to partner with Kunai, a non-blockchain developer contracting marketplace: snapshot.org/#/usebraintrus…
The decision appears to have had little community involvement.
Kind of.
The Braintrust community recently “voted” on a proposal to partner with Kunai, a non-blockchain developer contracting marketplace: snapshot.org/#/usebraintrus…
The decision appears to have had little community involvement.

At the time of the vote on Kunai, Braintrust’s network had about 45,000 registered members.
Only 27 wallets voted, a microscopic fraction of the community.
Those 27 votes all gave unanimous consent. Very normal.
Is this what living in the Network State feels like, @balajis?
Only 27 wallets voted, a microscopic fraction of the community.
Those 27 votes all gave unanimous consent. Very normal.
Is this what living in the Network State feels like, @balajis?

The next claim about BTRST is “bid staking” (a feature not yet live).
If you're applying for work, bid staking lets you agree to punish yourself with a financial loss if you don’t show up to a scheduled interview.
This idea… doesn’t require a blockchain. I’ll leave it at that.
If you're applying for work, bid staking lets you agree to punish yourself with a financial loss if you don’t show up to a scheduled interview.
This idea… doesn’t require a blockchain. I’ll leave it at that.


The final claim about BTRST is “career benefits”: They incentivize you to take a course, and in the future they’ll give you some kind of special perks.
But to the extent these benefits make any business sense, they could obviously be matched by Web2 competitors like Upwork.
But to the extent these benefits make any business sense, they could obviously be matched by Web2 competitors like Upwork.


Investors think the key to disrupting traditional recruiting is incentivizing referrals with BTRST tokens.
Where’s the evidence this drives below-market costs?
Sources tell me most recruiters are paid market wages in fiat, including half the names on the referral leaderboard.
Where’s the evidence this drives below-market costs?
Sources tell me most recruiters are paid market wages in fiat, including half the names on the referral leaderboard.


Braintrust claims to have more transparency than its Web2 predecessors.
But juicing revenue by partnering with existing Web2 agencies and subsidizing recruiter pay isn't transparent.
Ironically, Upwork offers a more transparent public breakdown of their revenue and headcount.
But juicing revenue by partnering with existing Web2 agencies and subsidizing recruiter pay isn't transparent.
Ironically, Upwork offers a more transparent public breakdown of their revenue and headcount.




What have we learned about $BTRST?
⬜️ Job seekers hardly use it
⬜️ Recruiters hardly use it
⬜️ But Braintrust uses it to paint misleading narratives about take rates, ownership, and transparency
The tokens aren’t helping build a winning business as claimed in the white paper.
⬜️ Job seekers hardly use it
⬜️ Recruiters hardly use it
⬜️ But Braintrust uses it to paint misleading narratives about take rates, ownership, and transparency
The tokens aren’t helping build a winning business as claimed in the white paper.
Web3 proponents like @packyM love pointing out that a talent marketplace is a real use case and potentially a real business.
And they’re right: copying Upwork is a real use case, and can be a sustainable business.
It’s just not a Web3-enabled use case or a Web3-enabled biz.
And they’re right: copying Upwork is a real use case, and can be a sustainable business.
It’s just not a Web3-enabled use case or a Web3-enabled biz.


A wide range of reputable Web3 investors poured over $100M into this project.
Do investors know there’s no community voting? Do they know how much staffing is subsidized?
Typical of Web3, a poorly-articulated business model justified a sky-high valuation.
Do investors know there’s no community voting? Do they know how much staffing is subsidized?
Typical of Web3, a poorly-articulated business model justified a sky-high valuation.

Braintrust still has potential to get profitable before funding runs out if they swallow their pride.
Forget the white paper. BTRST tokens are no more than a marketing gimmick.
Best hope may be to rollup (centralize) many agencies like Kunai and drive operational efficiencies.
Forget the white paper. BTRST tokens are no more than a marketing gimmick.
Best hope may be to rollup (centralize) many agencies like Kunai and drive operational efficiencies.
The key takeaway of my analysis is how incapable blockchain is at helping companies succeed.
I can assure you the next Web3 company I analyze will be the same. There are fundamental reasons why blockchain is devoid of practical applications.
I can assure you the next Web3 company I analyze will be the same. There are fundamental reasons why blockchain is devoid of practical applications.
https://twitter.com/liron/status/1558508739358965760
It's a shame that smart people are still getting fooled by Web3's #HollowAbstractions.
Thankfully, a growing number of tech folks are speaking out that blockchain technology doesn’t have any practical applications.
Those are the brains to trust.
Thankfully, a growing number of tech folks are speaking out that blockchain technology doesn’t have any practical applications.
Those are the brains to trust.
If you like getting disillusioned with Web3 "use cases", check out my thread about @Helium:
https://twitter.com/liron/status/1551738599254773765
And my breakdown of @Shopify’s ill-conceived NFT “tokengated commerce” feature:
https://twitter.com/liron/status/1557848322961854464
@packyM @variantfund @jessewldn Funny exchange where @gilbert brings up the 10% take rate to @adamjacksonsf.
From this @AcquiredFM episode: acquired.fm/episodes/web3-…
From this @AcquiredFM episode: acquired.fm/episodes/web3-…
• • •
Missing some Tweet in this thread? You can try to
force a refresh











