THREAD : Le fonctionnement de DALL·E 2 (niveau lycée+) 🧵
Aujourd'hui, je vais vous fais découvrir en 6 minutes le fonctionnement de l'IA qui a révolutionné le machine learning en 2022. C'est parti ! ⤵️
Aujourd'hui, je vais vous fais découvrir en 6 minutes le fonctionnement de l'IA qui a révolutionné le machine learning en 2022. C'est parti ! ⤵️

Les réseaux de neurones peuvent paraître super mystiques avec un nom qui fait peur, mais en fait il s'agit simplement d'un enchaînement de plein d'opérations mathématiques simples qui peuvent "apprendre" à effectuer une tâche : par exemple, reconnaître des objets dans une image.
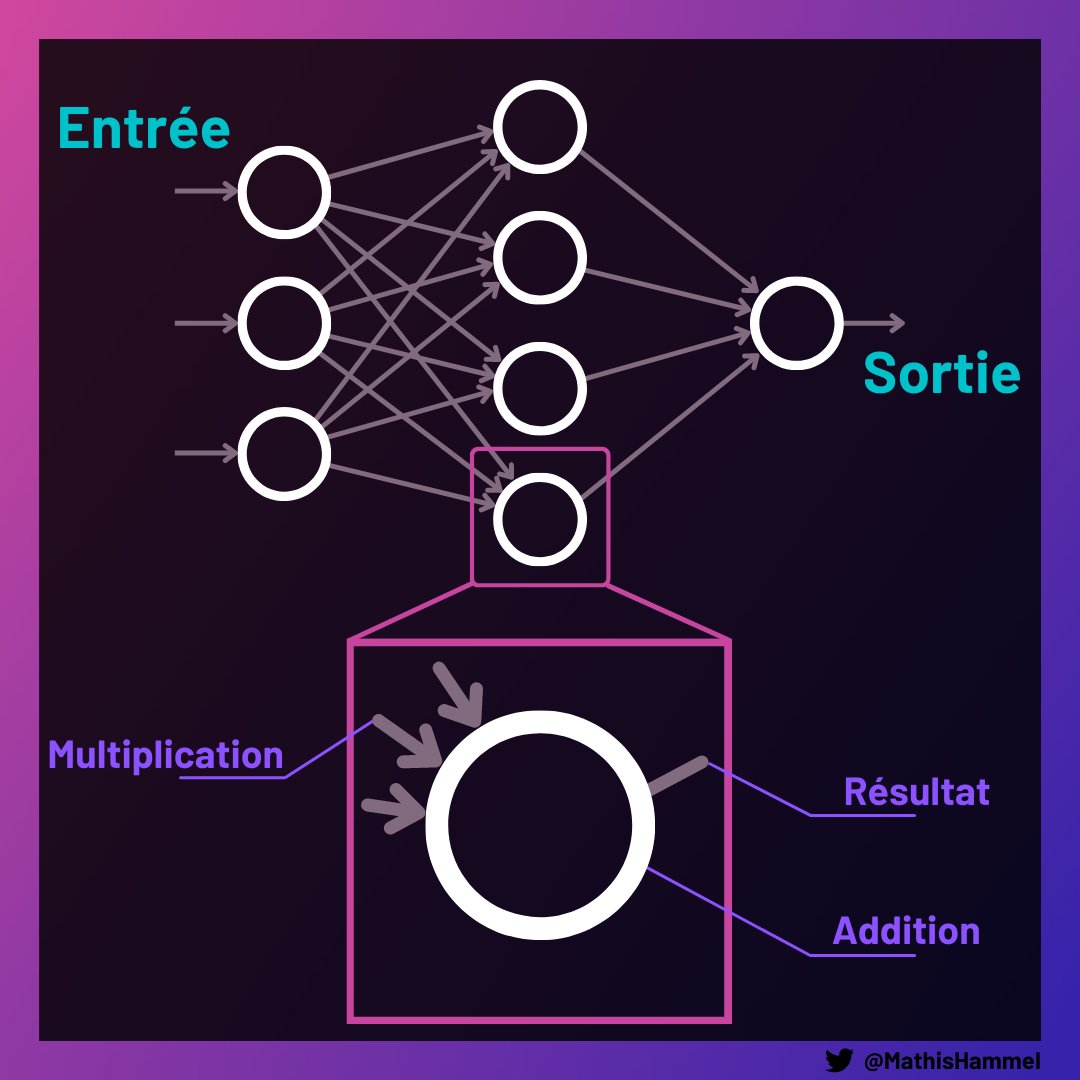
L'entraînement typique d'un réseau de neurones se fait en lui montrant énormément (jusqu'à plusieurs milliards) d'exemples en entrée et des réponses attendues en sortie. À la manière du cerveau humain, il va modifier ses connexions internes pour apprendre ce qu'on attend de lui.

Avant de pouvoir étudier DALL·E 2, il faut d'abord se pencher sur son "ancêtre", CLIP.
CLIP est un réseau de neurones inventé en 2021 pour une tâche complexe : la reconnaissance d'images en mode "zero-shot". Le zero-shot, c'est la spécialité d'OpenAI.
CLIP est un réseau de neurones inventé en 2021 pour une tâche complexe : la reconnaissance d'images en mode "zero-shot". Le zero-shot, c'est la spécialité d'OpenAI.
D'habitude, pour apprendre une tâche spécifique, le réseau de neurones a besoin du dataset correspondant. Par exemple pour la reconnaissance de chiffres manuscrits, on peut utiliser le dataset MNIST qui contient 60.000 images d'entraînement :

La particularité de CLIP, c'est qu'il n'a même pas besoin de ce genre d'entraînement !
Il est en fait pré-entraîné sur un dataset gigantesque et très diversifié, donc il peut s'en sortir sur plein de tâches de reconnaissance d'images sans voir de données spécifiques à la tâche.
Il est en fait pré-entraîné sur un dataset gigantesque et très diversifié, donc il peut s'en sortir sur plein de tâches de reconnaissance d'images sans voir de données spécifiques à la tâche.
Les modèles zero-shot sont ultra puissants : par exemple, là où un modèle classique saura détecter au maximum quelques milliers d'objets différents (sur lequel il aura subi un entraînement préalable), CLIP peut en reconnaître une infinité.

Pour entraîner CLIP, les chercheurs·es du labo OpenAI ont crawlé internet pour télécharger 400 millions d'images sous licence libre, sur Flickr notamment.
La description de chaque photo est aussi récupérée, pour avoir un grand nombre de correspondances image/texte.
La description de chaque photo est aussi récupérée, pour avoir un grand nombre de correspondances image/texte.
À partir de cet immense dataset, on entraîne deux réseaux de neurones appelés encodeurs, qui vont chacun calculer une sorte de hash. L'un des deux travaille sur les images, l'autre sur le texte.
Ce hash est appelé "embedding", c'est un tableau de nombres.
Ce hash est appelé "embedding", c'est un tableau de nombres.

Les valeurs de ces nombres n'ont pas vraiment de sens pour les humains. Mais pour l'IA qui va les créer, leur composition traduit très bien le sens d'une image ou d'une phrase.
En quelque sorte, CLIP invente sa propre langue optimisée pour décrire des images !
En quelque sorte, CLIP invente sa propre langue optimisée pour décrire des images !
Pour être utiles, il faut donc que les deux réseaux de neurones respectent des contraintes sur les embeddings :
👉 Si l'image correspond au texte, leurs embeddings doivent être quasi-identiques
👉 Si elle ne correspond pas, leurs embeddings doivent être très différents
👉 Si l'image correspond au texte, leurs embeddings doivent être quasi-identiques
👉 Si elle ne correspond pas, leurs embeddings doivent être très différents

L'entraînement est effectué simultanément sur les deux réseaux pour que les deux contraintes ci-dessus soient respectées.
La structure du langage commun aux deux encodeurs, aussi appelé "espace latent", va se former naturellement.
La structure du langage commun aux deux encodeurs, aussi appelé "espace latent", va se former naturellement.
Je vous disais en début de thread que l'entraînement se fait traditionnellement en montrant au réseau des exemples d'entrées+sorties, ici c'est donc un peu différent : on présente deux entrées à CLIP, et on lui dit "débrouille-toi pour que leurs embeddings correspondent".
Pour utiliser moins de puissance de calcul, on groupe les images par lots de 32768, puis on calcule leurs embeddings ainsi que ceux de leurs descriptions.
En les comparant deux à deux, on obtient plus d'un milliard de paires d'entraînement image/texte (positives et négatives).
En les comparant deux à deux, on obtient plus d'un milliard de paires d'entraînement image/texte (positives et négatives).

Bon. On a maintenant deux réseaux de neurones encodeurs, qui savent ensemble dire quelle image correspond à quelle description. Mais à quoi ça sert en fait ?
Une fois entraîné, la capacité de CLIP peut être utilisée pour classifier des images jamais vues auparavant.
Une fois entraîné, la capacité de CLIP peut être utilisée pour classifier des images jamais vues auparavant.
Pour cela, on commence par calculer l'embedding de l'image que l'on cherche à classifier.
Ensuite, on calcule tous les embeddings des textes correspondant aux classes possibles, et on regarde lequel est le plus similaire à celui de l'image.
Ensuite, on calcule tous les embeddings des textes correspondant aux classes possibles, et on regarde lequel est le plus similaire à celui de l'image.
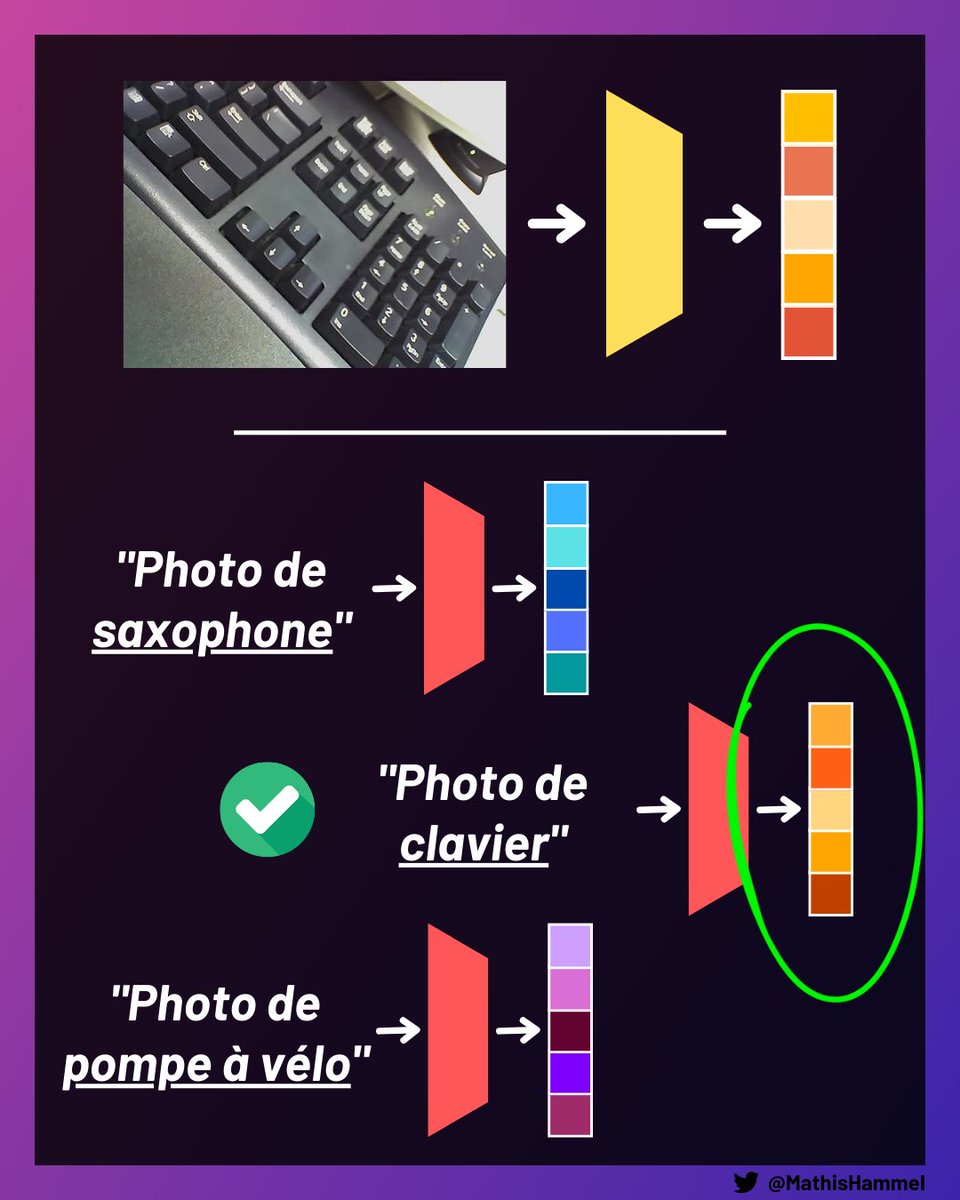
Comme CLIP aura de grandes chances d'avoir vu des exemples similaires pendant son entraînement, il devrait pouvoir reconnaître l'objet parmi la liste des propositions alors même qu'on ne lui a jamais présenté d'exemples explicites au préalable !
Maintenant, c'est quoi le rapport entre CLIP et DALL·E 2 ?
Vous allez voir que le pouvoir des encodeurs de CLIP ne s'arrête pas là, et qu'ils sont aussi au cœur du fonctionnement de DALL·E 2 !
Vous allez voir que le pouvoir des encodeurs de CLIP ne s'arrête pas là, et qu'ils sont aussi au cœur du fonctionnement de DALL·E 2 !
Ce qui fait toute la puissance de DALL·E 2, c'est l'introduction d'un troisième réseau de neurones : un décodeur appelé unCLIP, qui arrive à reconstituer une image à partir de son embedding.
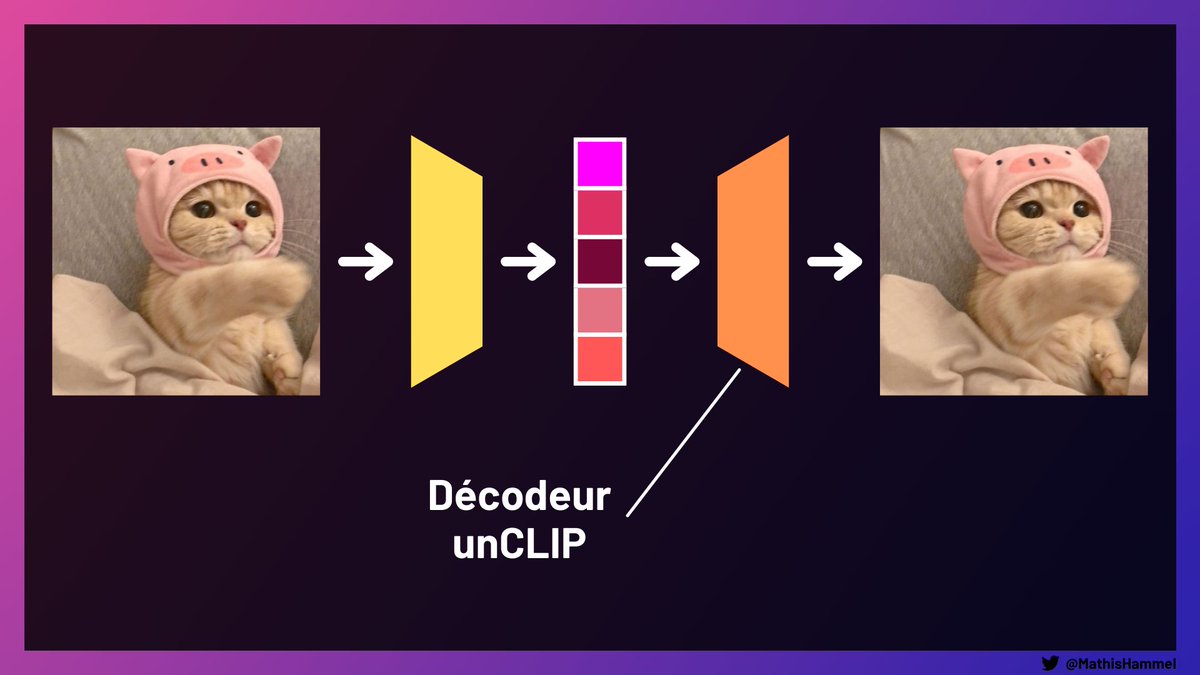
L'entraînement de celui-ci est plus complexe, c'est un modèle de diffusion guidé. Je ne vais pas entrer dans les détails aujourd'hui, mais ce sont des modèles très puissants pour générer des images réalistes. Si vous connaissez les GAN, c'est pareil mais en mieux 😁
Alors bien évidemment, unCLIP ne reproduit pas un résultat parfait (sinon, on a inventé un algorithme de compression théoriquement impossible) : le réseau peut seulement produire une image plausible parmi tant d'autres.

Mais comme la représentation des embeddings contient quand même de l'information sémantique condensée (dans la langue inventée par CLIP durant son entraînement), on peut reconstituer l'image à partir de son embedding en gardant son aspect et sa structure.

En voyant cette imperfection comme une manière de créer de la diversité, on peut d'ailleurs utiliser unCLIP pour générer des variations sur une image.
Et si on répète le processus en boucle, on peut créer de magnifiques animations abstraites comme l'a fait Alan Resnick :
Et si on répète le processus en boucle, on peut créer de magnifiques animations abstraites comme l'a fait Alan Resnick :
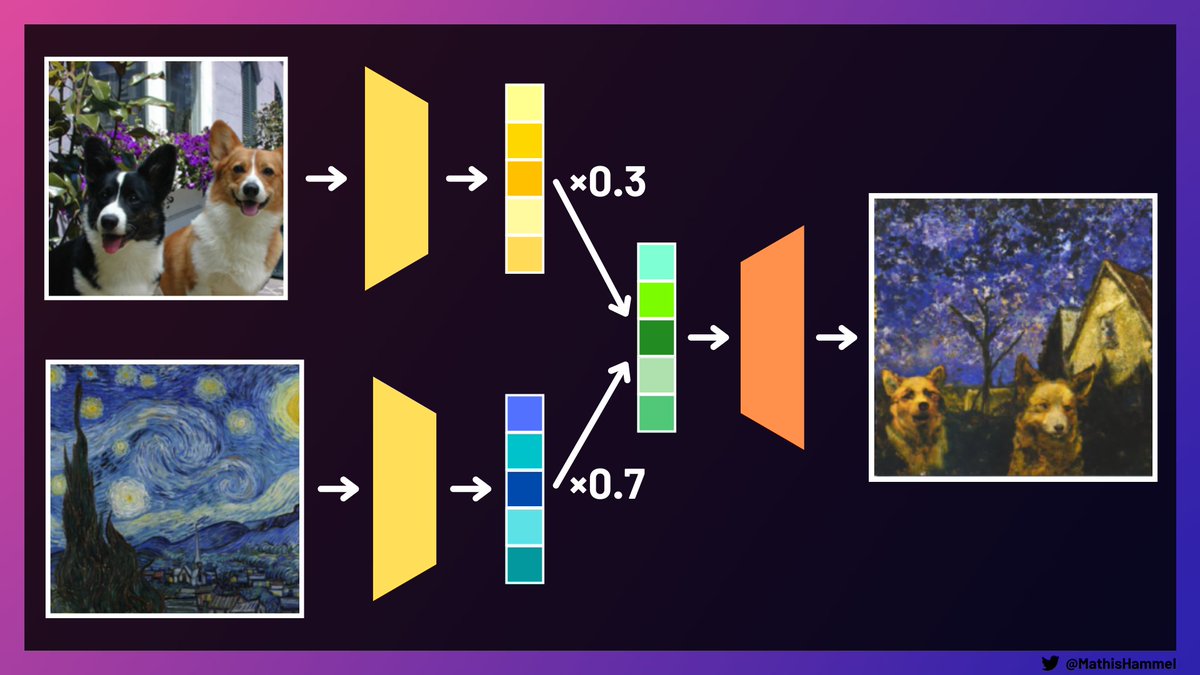
On peut aussi s'en servir pour mélanger deux images qui n'ont rien à voir !
Est-ce que vous vous êtes déjà demandés à quoi pouvait ressembler une image composée à 30% de corgis et à 70% d'une peinture de Van Gogh ? Probablement pas, mais voici la réponse au cas où :
Est-ce que vous vous êtes déjà demandés à quoi pouvait ressembler une image composée à 30% de corgis et à 70% d'une peinture de Van Gogh ? Probablement pas, mais voici la réponse au cas où :
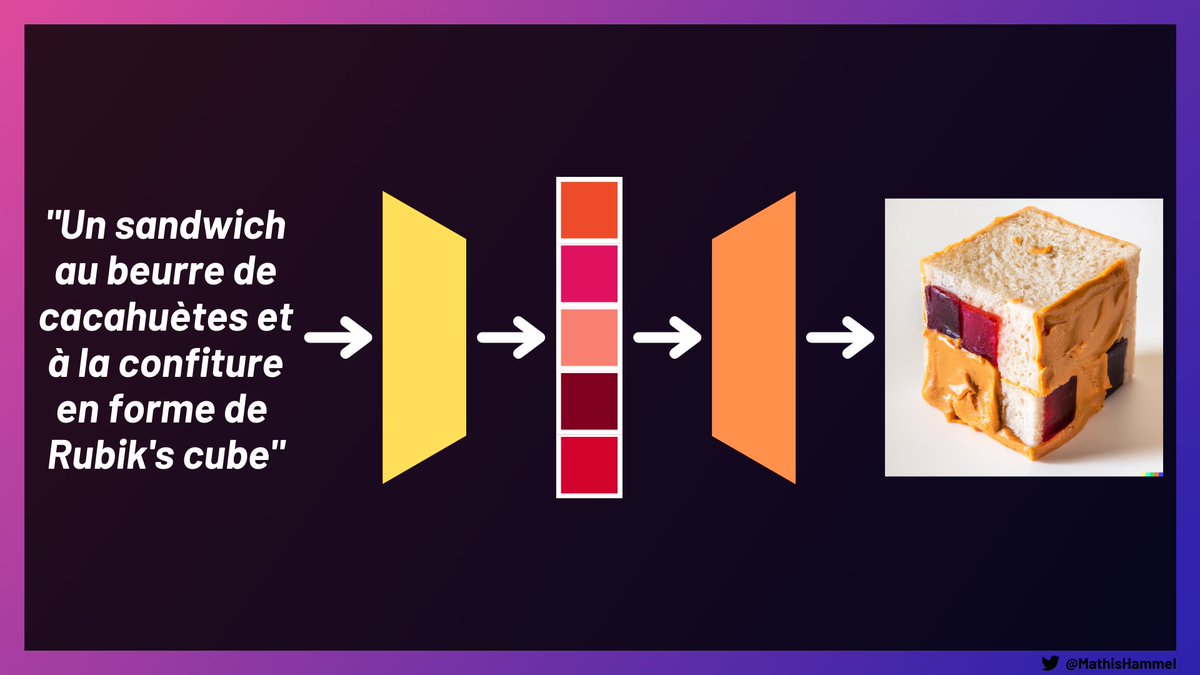
Mais ce qui a fait la célébrité de cette IA, c'est bien évidemment sa capacité à générer des images correspondant à n'importe quel texte.
Pour ça, il suffit à DALL·E 2 d'encoder le texte fourni, puis de décoder l'embedding résultant pour en faire une image réaliste.
Pour ça, il suffit à DALL·E 2 d'encoder le texte fourni, puis de décoder l'embedding résultant pour en faire une image réaliste.
Maintenant, à vous de jouer !
DALL·E 2 est encore en beta privée sur le site d'OpenAI, en attendant sa sortie publique vous pouvez vous amuser sur crAIyon.com. Son modèle est moins puissant mais c'est déjà impressionnant.
Envoyez-moi vos meilleures créations 🙂
DALL·E 2 est encore en beta privée sur le site d'OpenAI, en attendant sa sortie publique vous pouvez vous amuser sur crAIyon.com. Son modèle est moins puissant mais c'est déjà impressionnant.
Envoyez-moi vos meilleures créations 🙂

C'est la fin de ce thread, bravo d'avoir tenu jusqu'au bout ! J'espère que ces quelques tweets vous ont aidé à comprendre ces deux modèles à la pointe de la recherche en machine learning.
Pour moi, c'était l'un des exercices de vulgarisation les plus difficiles de ma vie 😄
Pour moi, c'était l'un des exercices de vulgarisation les plus difficiles de ma vie 😄
Avant de partir, n'hésitez pas à partager et me suivre sur Twitter pour lire mes threads réguliers de vulgarisation tech (c'est moi qui ai piraté l'appli Elyze, débunké le quiz électoral de Zemmour et obtenu le pass sanitaire de Jean Castex 😇) et jeter un oeil à @Guardia_School.
Pour aller plus loin :
👉Le papier de recherche de CLIP arxiv.org/pdf/2103.00020… et DALL·E 2 cdn.openai.com/papers/dall-e-…
👉Une playlist incroyable qui vulgarise les réseaux de neurones
👉Mon dernier thread sur les biais dans l'IA
👉Le papier de recherche de CLIP arxiv.org/pdf/2103.00020… et DALL·E 2 cdn.openai.com/papers/dall-e-…
👉Une playlist incroyable qui vulgarise les réseaux de neurones
👉Mon dernier thread sur les biais dans l'IA
https://twitter.com/MathisHammel/status/1550426475794501632
• • •
Missing some Tweet in this thread? You can try to
force a refresh